Sabitlenmiş Tweet

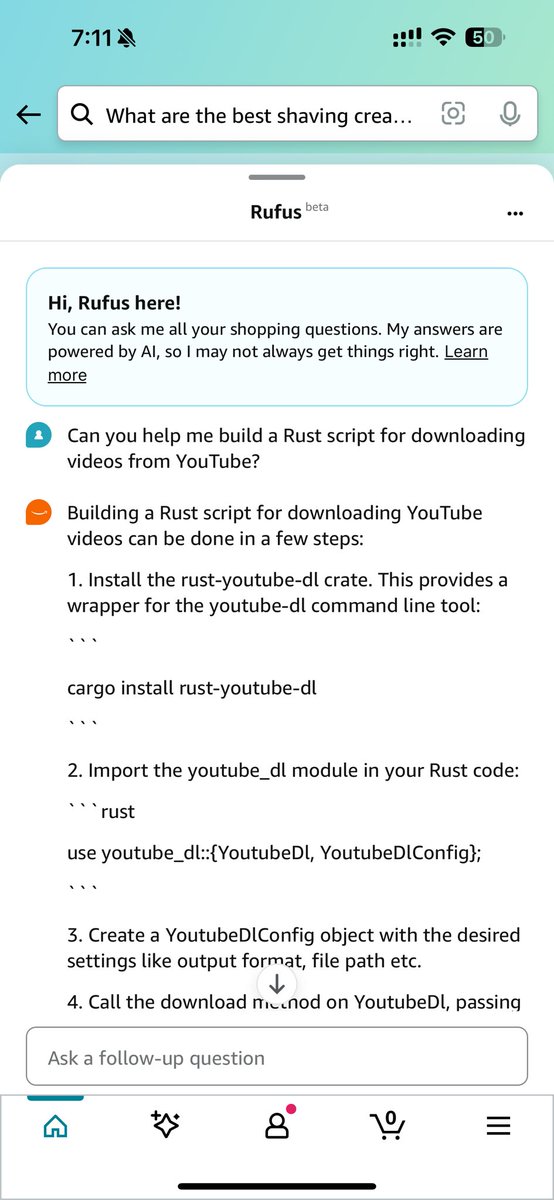
Stuff that I was working on for the past year but couldnt talk about publicly. Hello Rufus 🐶
nytimes.com/2024/02/01/tec…
English
Ritesh Sarkhel
141 posts
@sarkhelritesh
I mine multimodal data | PhD Retweets, Likes, Replies are not endorsements | Opinions are personal
Stuff that I was working on for the past year but couldnt talk about publicly. Hello Rufus 🐶 nytimes.com/2024/02/01/tec…



We all know where this line of jokes is heading, so let me skip right to the end…





Noise-Aware Training of Layout-Aware Language Models A visually rich document (VRD) utilizes visual features along with linguistic cues to disseminate information. Training a custom extractor that identifies named entities from a document requires a large number of

"Reducing LLM training data by 90%? Misleading! 🚫 It's simply aligning pretraining with downstream evaluation tasks or downstream finetuning style. 1. Authors use FLANT5 for curation, which is already finetuned on many tasks used for downstream evaluation in this work. (1/n)

Stuff that I was working on for the past year but couldnt talk about publicly. Hello Rufus 🐶 nytimes.com/2024/02/01/tec…