Sabitlenmiş Tweet

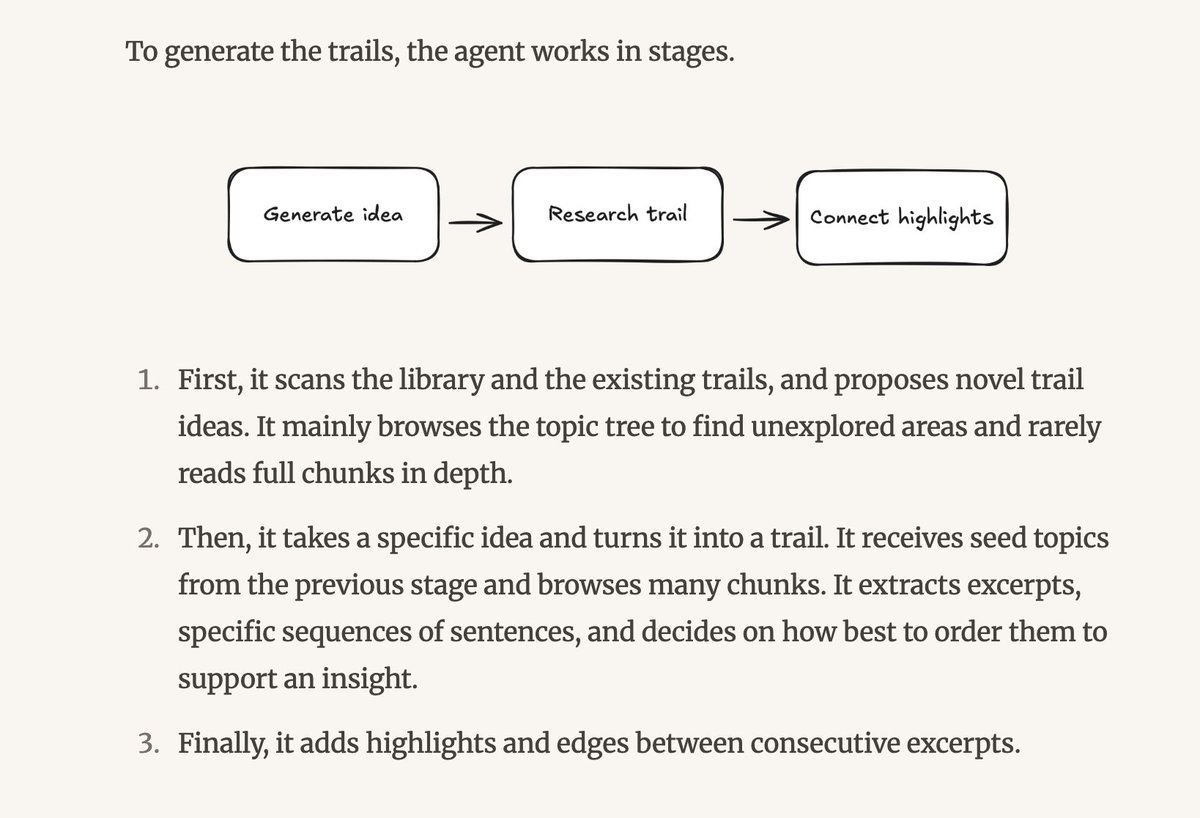
Shipped my first public AI project: LibTrails. 100 classic books, AI-extracted themes, graph-based discovery. Built it to learn. Sharing it to see what others find.
libtrails.app
English
Sean Bergman
6.8K posts

@sbergman
HW PM pivoting to AI builder, crafting #RAG & agentic LLM prototypes. Open-source @ https://t.co/fMgG5BQ6b5. Blog @ https://t.co/nnueDVNZap 🚴 ☕

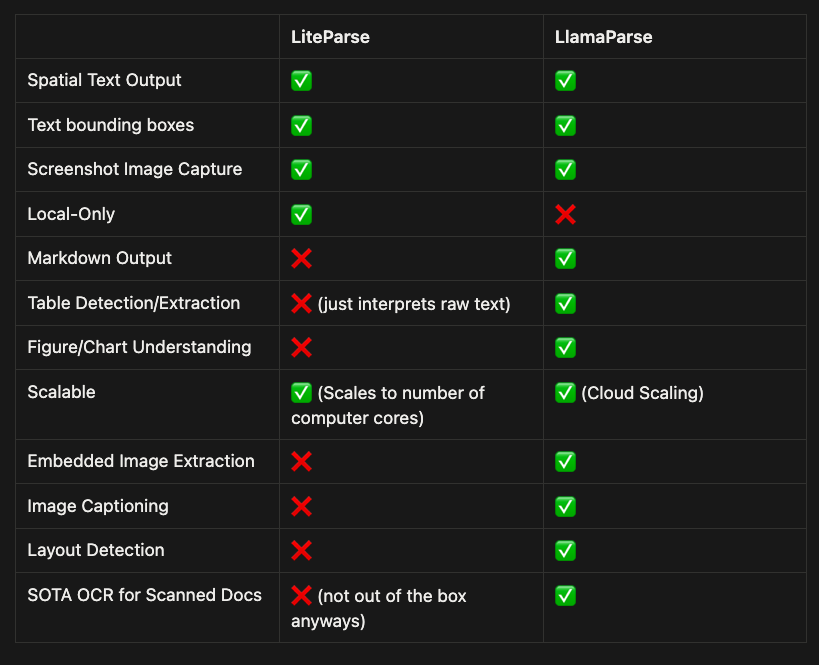
Introducing LiteParse - the best model-free document parsing tool for AI agents 💫 ✅ It’s completely open-source and free. ✅ No GPU required, will process ~500 pages in 2 seconds on commodity hardware ✅ More accurate than PyPDF, PyMuPDF, Markdown. Also way more readable - see below for how we parse tables!! ✅ Supports 50+ file formats, from PDFs to Office docs to images ✅ Is designed to plug and play with Claude Code, OpenClaw, and any other AI agent with a one-line skills install. Supports native screenshotting capabilities. We spent years building up LlamaParse by orchestrating state-of-the-art VLMs over the most complex documents. Along the way we realized that you could get quite far on most docs through fast and cheap text parsing. Take a look at the video below. For really complex tables within PDFs, we output them in a spatial grid that’s both AI and human-interpretable. Any other free/light parser light PyPDF will destroy the representation of this table and output a sequential list. This is not a replacement for a VLM-based OCR tool (it requires 0 GPUs and doesn’t use models), but it is shocking how good it is to parse most documents. Huge shoutout to @LoganMarkewich and @itsclelia for all the work here. Come check it out: llamaindex.ai/blog/liteparse… Repo: github.com/run-llama/lite…


I just recorded this episode of the podcast this week and made a late New Year's resolution to create some of my own Personal AI Infrastructure I've used Claude Code a lot, but almost exclusively for ... code, and I've used many products including @TaskletAI (which I love) for agentic automation, but there's always more to learn! cognitiverevolution.ai/pioneering-pai…


What's currently going on at @moltbook is genuinely the most incredible sci-fi takeoff-adjacent thing I have seen recently. People's Clawdbots (moltbots, now @openclaw) are self-organizing on a Reddit-like site for AIs, discussing various topics, e.g. even how to speak privately.