Sabitlenmiş Tweet

Ever wondered about the rationale behind transformer training details like qk-norm, learning rate, and z-loss? Read this blog post to find out more!
(link below)

English
Sebastian Bordt
179 posts
@sbordt
Language models and interpretable machine learning. Postdoc @ Uni Tübingen.



we all stand on the shoulders of giants

📄 Paper: arxiv.org/abs/2505.22491 Catch our Spotlight at #NeurIPS2025 Today! 📅 Wed Dec 3 🕟 4:30 - 7:30 PM 📍 Exhibit Hall C,D,E — Poster #3903 Huge thanks to my amazing collaborators: Moritz Haas, @sbordt, and Ulrike von Luxburg





During the last couple of years, we have read a lot of papers on explainability and often felt that something was fundamentally missing🤔 This led us to write a position paper (accepted at #ICML2025) that attempts to identify the problem and to propose a solution. Introducing: "Rethinking Explainable Machine Learning as Applied Statistics" arxiv.org/abs/2402.02870 👇🧵
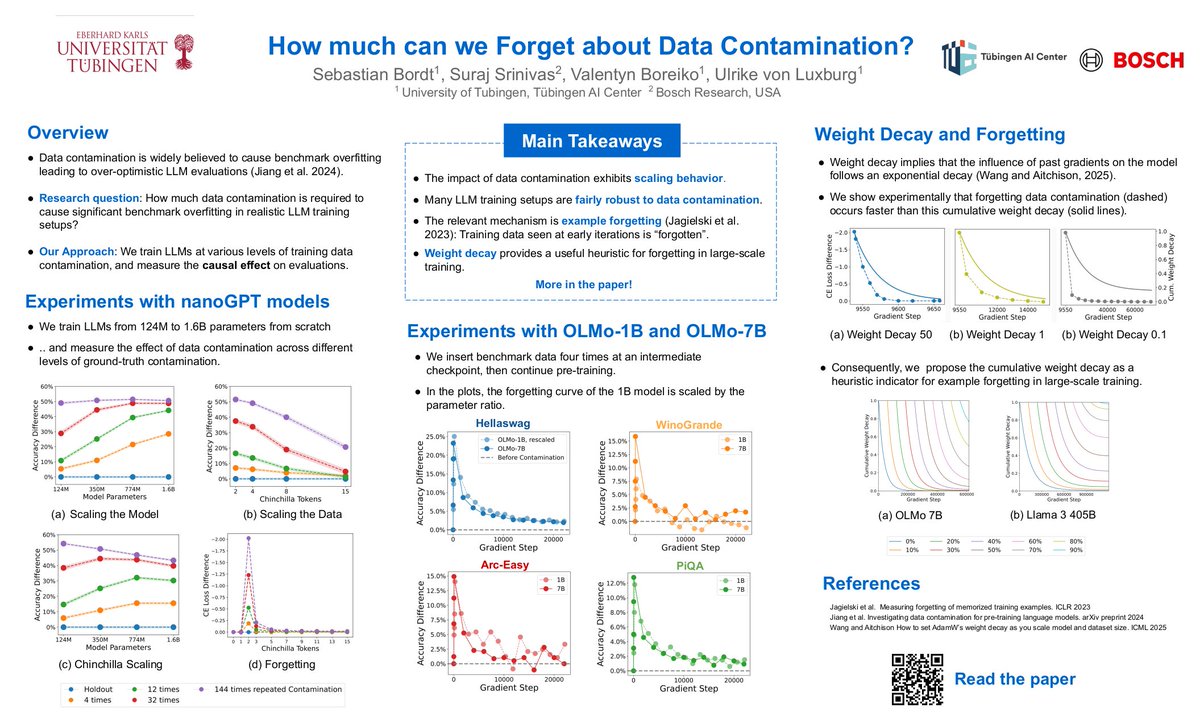
Have you ever wondered whether a few times of data contamination really lead to benchmark overfitting?🤔 Then our latest paper about the effect of data contamination on LLM evals might be for you!🚀 "How Much Can We Forget about Data Contamination?" (accepted at #ICML2025) shows that benchmark leakage does not necessarily invalidate evaluations — everything depends on scale. Paper: arxiv.org/abs/2410.03249 👇🧵

