Sabitlenmiş Tweet
ScitiX
193 posts


ScitiX
@scitix
Shaping the Future with Intelligent Computing!
Singapore Katılım Eylül 2024
86 Takip Edilen36 Takipçiler

🥂What an epic night! Our #GTC2026 Happy Hour co-hosted with the SGLang team was a massive success! @lmsysorg @sgl_project
⚡️The venue was packed, and the conversations around SGLang's Scalable Multilingual LLM Serving Engine were electric. From tech deep-dives to future trends, the AI community energy was unmatched!
Thank you to everyone who came out! Catch you at the next GTC! 👇🎥
#SGLang #NVIDIA #LLM #TechEvent

English
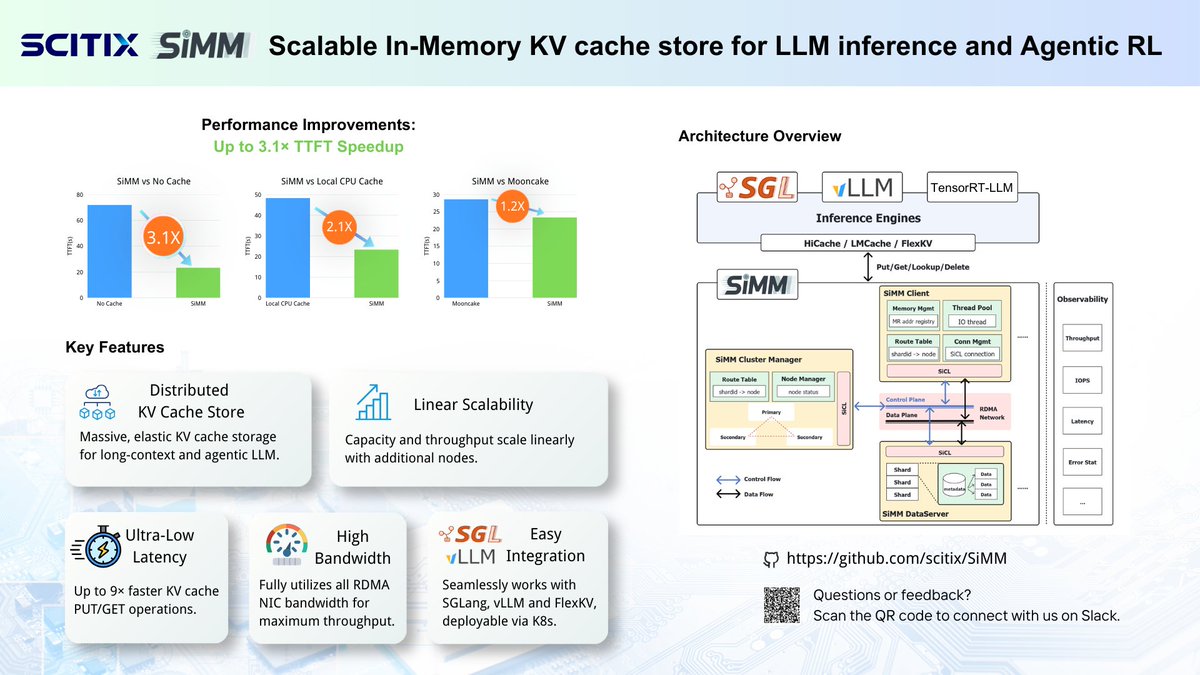
We didn't just build a cache; we built it for extreme scale.
🔥 Up to 9x lower latency via end-to-end zero-copy.
📈 Linear scalability & full utilization of ALL RDMA NICs.
🚀 3.1x TTFT speedup (at 32K context) vs. no-cache baselines!
Built for multi-turn agents and long Chain-of-Thought reasoning, SiMM is already proven in production and deploys easily via K8s.
Ready to accelerate your LLM serving and Agentic RL ? try it now!
🔗github.com/scitix/SiMM
#LLMs #OpenSource #AI #MachineLearning #KVCache
English
LLM context lengths have grown 4x in the past year, causing skyrocketing GPU costs and painful Time-To-First-Token (TTFT) latency. Today, we are thrilled to open-source SiMM ⚡️: an ultra-fast, scalable in-memory KV cache engine that breaks the long-context bottleneck!
SiMM transforms heavy prefill compute into high-speed I/O retrieval. It provides a scalable and low-latency memory pool for KV cache that seamlessly integrates with leading engines like @sgl_project and @vllm_project .
#LLM #OpenSource #AI #MachineLearning #KVCache
English
Thrilled to partner with @lmsysorg and an amazing crew for this! 🚀 If you're at GTC, come grab a drink and let's talk the future of AI compute. See you in San Jose! 🍻
LMSYS Org@lmsysorg
🍝🍷 Taking a break from the GTC rush? Join us for an exclusive Happy Hour. SGLang × @radixark are hosting a GTC 2026 Happy Hour with friends across the AI infra ecosystem! Expect great food, unlimited drinks, and conversations with researchers & engineers from OpenAI, xAI, DeepMind, Meta, NVIDIA, Ollama, and top AI startups. 📅 Mar 17, 6:30–8:30 PM 📍 Walking distance from GTC (location shared after approval) Last year’s GTC meetup was the first time we met the SGLang community in person. Since then, we’ve been shipping nonstop: LLM inference breakthroughs, RL infra, diffusion framework, and more. Let’s push AI infrastructure forward together.⚡ 🎟 Register: luma.com/hgj595as 🔔 Subscribe to our meetup calendar so you don’t miss future events: luma.com/SGLang-meetups With appreciation to our partners: @radixark @ZZZZZPotentials @scitix Looking forward to seeing many friends there. ✨
English
What makes SiClaw different from OpenClaw?
🔐 Security Governance
A strict permission layer between agents and infrastructure: read-only by default, command whitelists, per-action approval for writes, and workspace-isolated credentials to protect production environments.
👥 Team Collaboration
Built for enterprise teams with multi-workspace support, multi-user management (SSO/OAuth2), and isolated AgentBox sandboxes for different teams and environments.
⚡ Proactive Operations
Integrates with mainstream monitoring and alerting systems to detect anomalies, automatically generate diagnostic plans, and execute remediation actions—moving from reactive to autonomous operations.
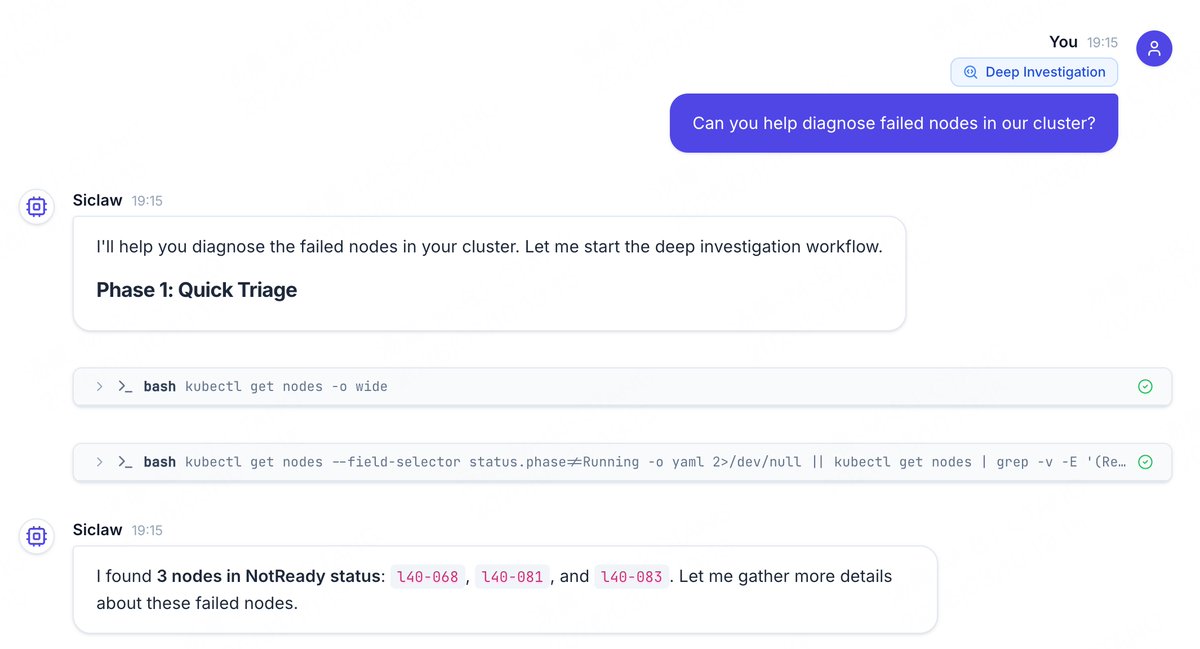
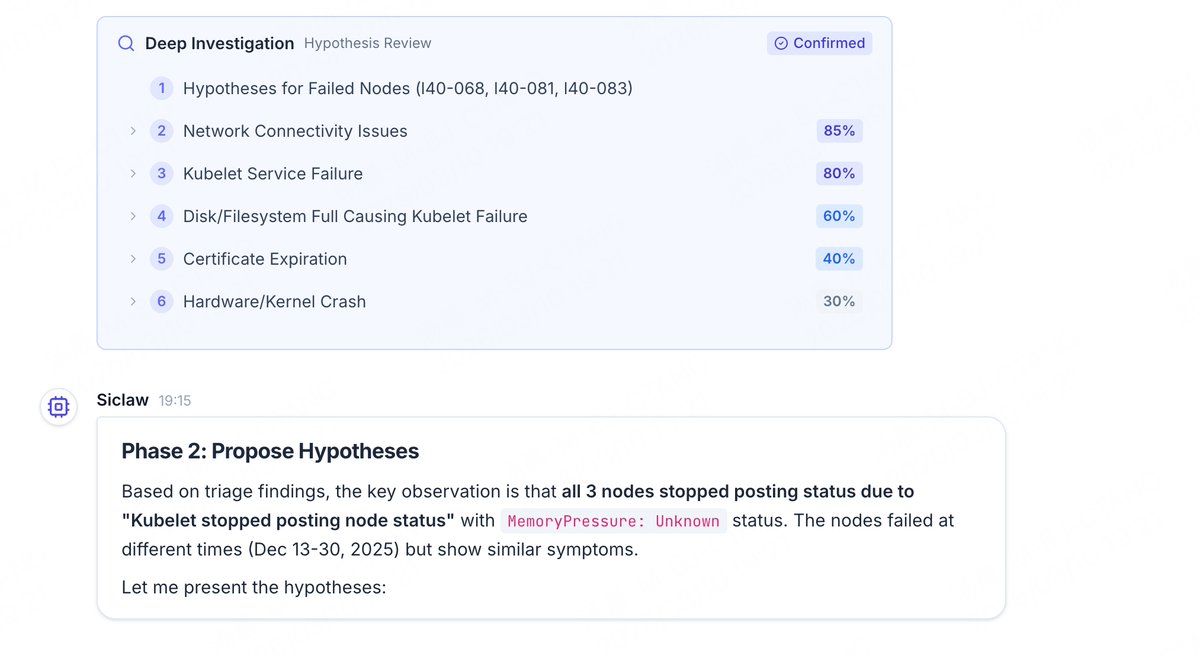
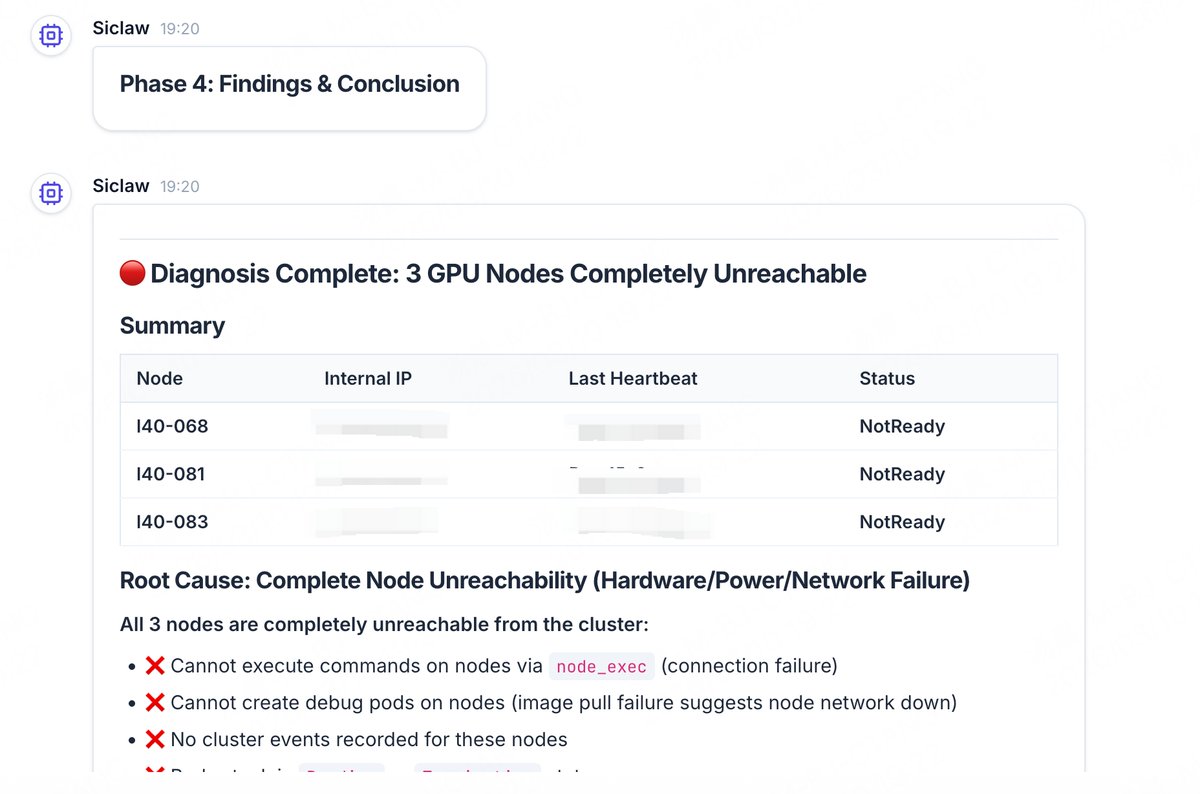
🔍 Deep Diagnostics
A hypothesis-driven 4-stage diagnostic engine: Context collection → Hypothesis generation → Parallel validation → Root-cause conclusion.
Bringing “Deep Research” capabilities into real-world operations.
💬 Join our community:
join.slack.com/t/siclaw-sciti…
English
🚀 We’re building SiClaw, an open-source AIOps platform based on Pi-Agent.
SiClaw focuses on Intelligent Infrastructure, DevOps Automation, and Dev–Ops Collaboration.
We welcome developers to try it out, share feedback, and contribute!
🌐 Website: siclaw.ai
💻 GitHub: github.com/scitix/siclaw
#AIOps #DevOps #OpenSource
English
If you want to understand AI, you need to look at the entire system, not just the model. 🔔
AI workloads rely on a layered technology stack that spans compute, data, software, and orchestration.
Performance emerges from how these layers work together.
#AIInfrastructure

English

3 counter-intuitive ways to boost GPU utilization 🚀
Improving GPU utilization doesn't always need more hardware.
1. Tune Batch Sizes: Don't stick to defaults.
2. Embrace Mixed Precision: Use FP16/FP32. It’s faster, saves memory.
3. Co-Locate Compute: Latency kills throughput.

English
We hope you can join us as we kick off the year with a thoughtful conversation!
🔗 Registration is open here: scitix-ai.com/Beyond-the-Wai…
English