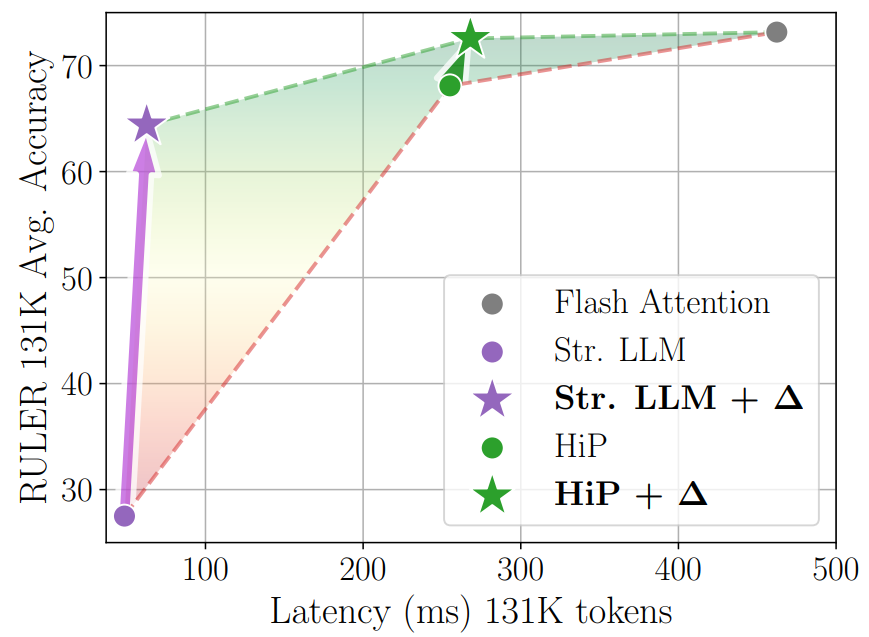
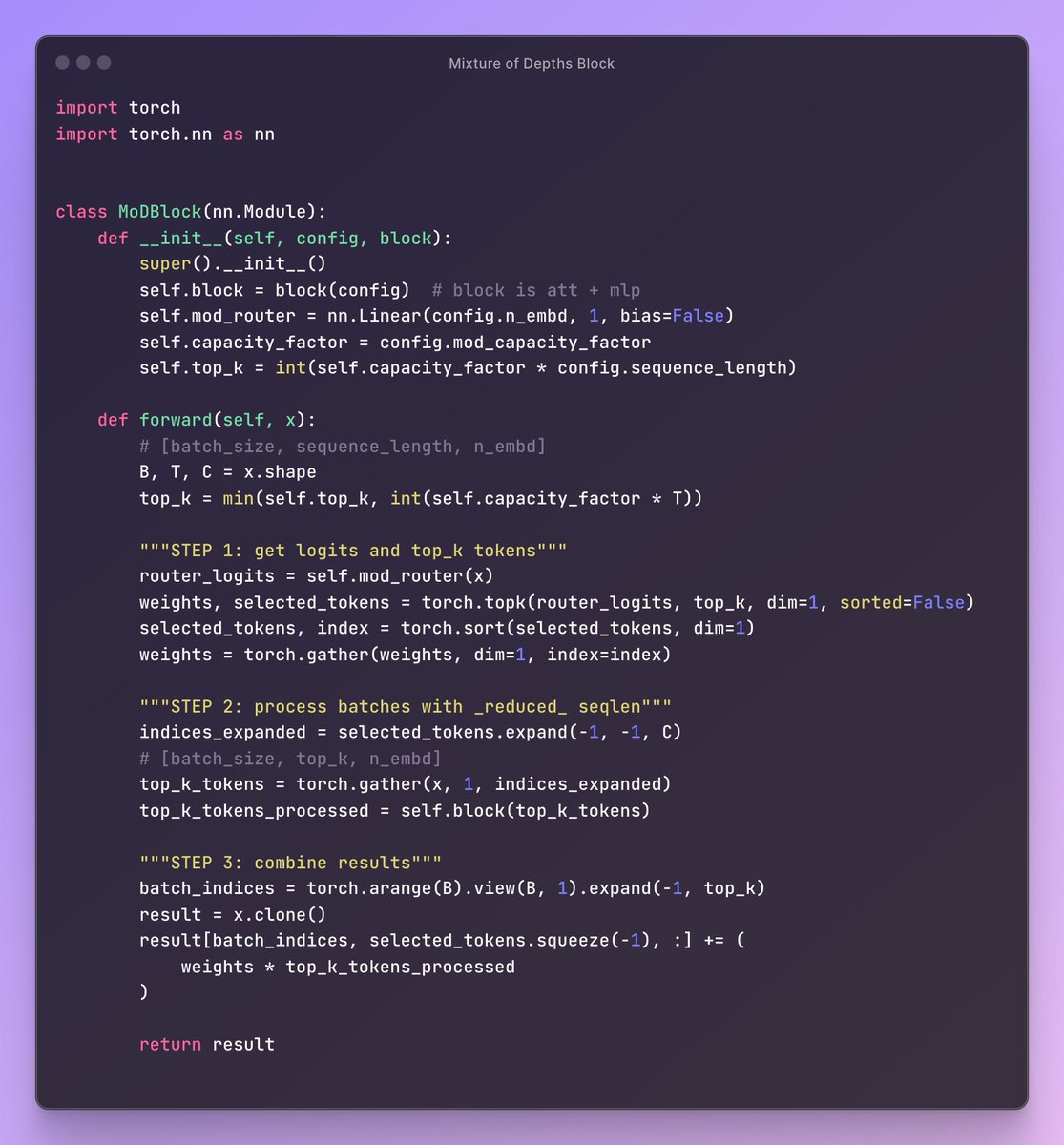
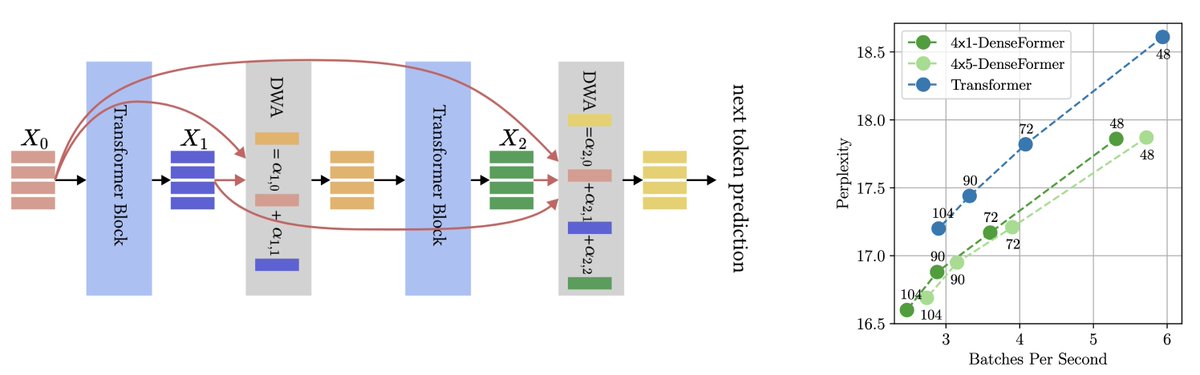
Sabitlenmiş Tweet

🚨 New paper! We propose HarmAug, a data augmentation method that distills large safety guard models into a 435M-parameter model. It detects harmful prompts with LLMs, cutting computational costs by 75% while matching performance of 7B+ models!
English