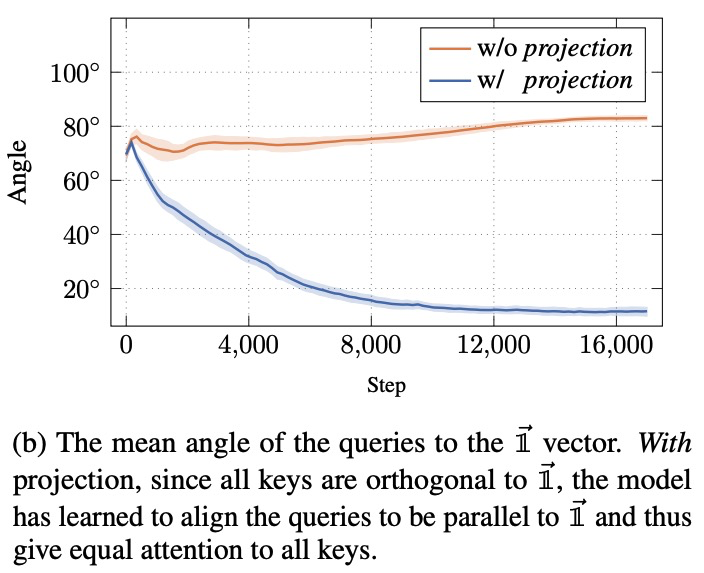
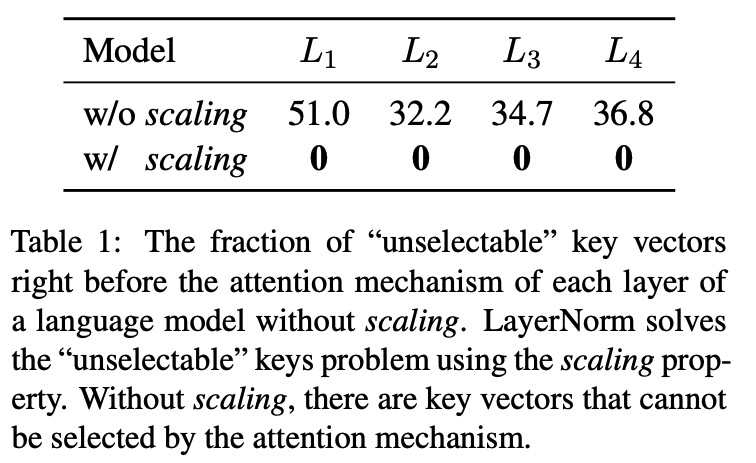
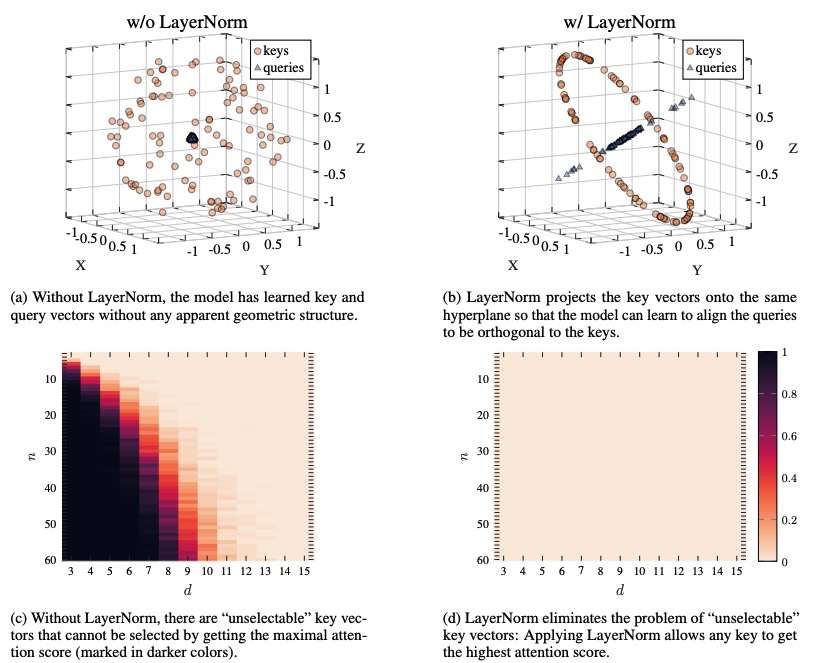
AK@_akhaliq
Amazon presents Question Aware Vision Transformer for Multimodal Reasoning
paper page: huggingface.co/papers/2402.05…
Vision-Language (VL) models have gained significant research focus, enabling remarkable advances in multimodal reasoning. These architectures typically comprise a vision encoder, a Large Language Model (LLM), and a projection module that aligns visual features with the LLM's representation space. Despite their success, a critical limitation persists: the vision encoding process remains decoupled from user queries, often in the form of image-related questions. Consequently, the resulting visual features may not be optimally attuned to the query-specific elements of the image. To address this, we introduce QA-ViT, a Question Aware Vision Transformer approach for multimodal reasoning, which embeds question awareness directly within the vision encoder. This integration results in dynamic visual features focusing on relevant image aspects to the posed question. QA-ViT is model-agnostic and can be incorporated efficiently into any VL architecture. Extensive experiments demonstrate the effectiveness of applying our method to various multimodal architectures, leading to consistent improvement across diverse tasks and showcasing its potential for enhancing visual and scene-text understanding.