
Uri Alon
367 posts
Uri Alon
@urialon1
Research Scientist @GoogleDeepMind
Pittsburgh, PA Katılım Nisan 2013
609 Takip Edilen3K Takipçiler

@Jonathan25734 אתה הראשון ששואל את השאלה הנכונה, אחרים מהרו לגנות ולקרוא לי רוצח וכו.
במקרה הזה החזקתי את הנייד לשניה כדי לראות אם הבת שלי מתקשרת (היה מצב חירום כלשהו) אבל אני מקפיד על בטיחות ולא הייתי עונה.
זה מה שרציתי לטעון במשפט.
להבהיר - לא שיקרתי ולא רימיתי, מימשתי את זכותי לערעור.
עברית
גר ב-LA ונתפס נוהג עם נייד ביד. חוטף משוטר דוח של 140 דולר.
קנס מיותר, כסף שנזרק לפח.
משלם באשראי ומבקש לערער בבימ"ש.
למה - כי אפשר. כי לפעמים שווה לקחת סיכון. כי זו אמריקה.
מופיע למשפט, השוטר דופק נפקדות.
השופט סופר לידי 140 ירקרקים ומתנצל על אי הנעימות שנגרמה לי.
#רק_באמריקה
עברית


@the_yaniv @oweissb AI כבר טוב מאד בתכנון תרופות
אני מעריך שהוא חתך שלבים פרקליניים לחצי זמן, והגדיל את סיכוי ההצלחה של phase I כמעט כפליים.
שום התקדמות בתחום הפארמה לא הייתה אפילו קרובה לזה
עברית

יש כאן משהו מאד עמוק.
אם ai היה כל כך טוב בתכנון תרופות (=מולקולות), המקום הראשון שהיינו רואים את זה, זה בסמים, איפה שלא לוקח 10 שנים להביא מולקולה חדשה לשוק בגלל רגולציה.
כרגע זה לא ממש קורה. מה שאולי מציע שזה לא תחום כזה טוב של ai.
(ותודה ל @oweissb שסיפר על זה).
🇬🇧🍗עוף טופיק🍗🇬🇧@oftopic_
מסתכל על מה שקורה במקסיקו וחושב לעצמי שראש קרטל סמים זה לא מקצוע שיוחלף בקרוב ע"י ai
עברית




יצא לי לדבר היום עם סטודנט שנה ג׳ למדעי המחשב באחת האוניברסיטאות המובילות בארץ.
המצב מאוד בעייתי. אין מטלה, עבודה, שיעורי בית שאי אפשר לפתור לכל היותר בדקה מול אחד המודלים. בתכנות, באינפי, באלגברה לינארית, בכל קורס.
הפיתוי גדול מדי ואם סטודנט נתקע על שאלה יותר מכמה דקות הוא פשוט פותח את הצ׳אט מצלם לו את השאלה ותוך דקה הוא יקבל תשובה מלאה. שלא לדבר על אלו שמלכתחילה פותרים עם הצ׳אט בלי לנסות לבד.
לא יודע מה הפתרון אבל אני לא מקנא באף סטודנט שצריך לחיות בעידן הזה. מרגיש כאילו עוד עשור או שניים כמות האנשים המשכילים במדינה ובעולם בכלל תרד בצורה דרסטית.
הדור שלמד בקורונה והמשיך למלחמה ומודלי שפה. איך משמרים השכלה אנושית במצב כזה?
עברית

@RodkinIdan גם אם יש וועד, יש איזון, אחרת כל הכסף הולך לבעלי החברה
עברית
[1/6] חמש תובנות על ai שיוציאו אתכם מהקונספציה שבה אתם חיים
>>>>
עברית
Uri Alon retweetledi

Two paths to AGI: fake it, or make it.
Fake it by generating massive data to hack benchmarks.
Make it by achieving breakthroughs in modeling and algorithms.
Label yourself.

English
@RunItBackPhilly @RunItBackPhilly DM me, I'll try to help (I can't DM you)
English

I almost fell for that one too! Luckily I screen shot it and pasted it in ChatGPT and it told me it’s fake and Google employees would never ask for info in an email thread 🤦🏼♂️🤦🏼♂️.
English
One of the craziest things about my business email getting hacked is that I contacted youtube support and got a FAKE email in return from maybe the same hackers disguised as youtube support trying to get me to give them my IP address and other email accounts through email. 🤦🏼♂️
English

קראו לי פה היום משפיענית, גורו, לא יודע חשבון של כיתה ג' וחרטטן. נראה לי יום מוצלח. כולו ציוץ על 4 ביצים וחצי חבילת קוטג'
עברית
כולנו צריכים לעשות גרסה כלשהי של סקוואט. היכולת לעשות סקוואט (לכרוע/לשבת) היא משמעותית מאוד לחופש שלנו לתפקד כמו גם השריר שהיא מאמנת (הארבע ראשי) גדול מאוד ומשפיע מאוד מטאבולית
מתן בסדר@Matan_banin
@IdoCharmDiet אם היית יכול לבחור תרגיל אחד לעשות, מה היית בוחר?
עברית
Uri Alon retweetledi
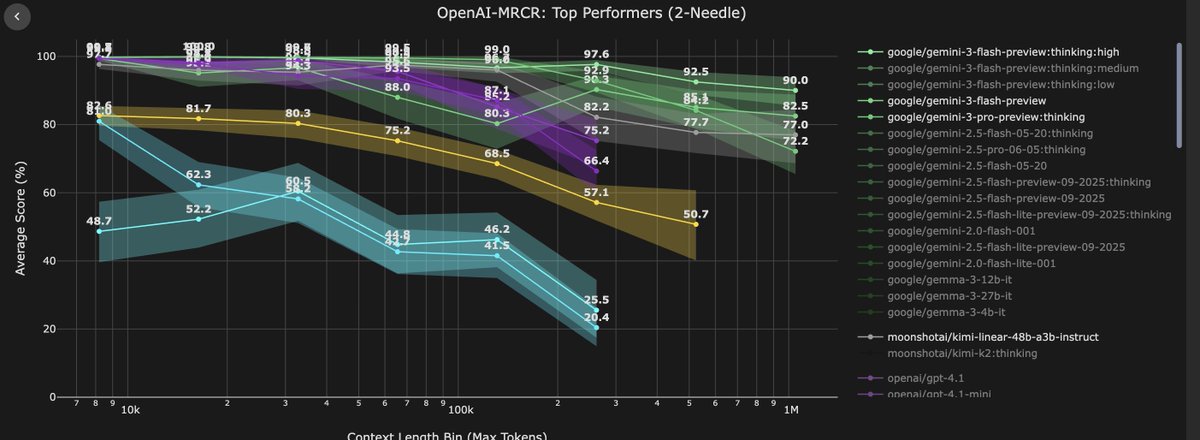
"Gemini 3 flash achieved 90% acc @ 1 million ctx. ... what black magic did they do?"
Yes, we've developed powerful new techniques for Gemini 3 long-context reasoning. Congratulations @urialon1 and the team!
bycloud@bycloudai
for more context on OpenAI's MRCR benchmark, curated at contextarena.ai by @DillonUzar , Gemini 3 flash achieved 90% acc @ 1 million ctx this performance is SoTA across all models, most SoTA models cant even go past 256k ctx at this length, you cant be using standard attention, it'll perform bad anyways, and ofc it'll be very expensive. (Gemini 3 flash is $0.5 in $3 out) Some sort of efficient attention is implemented, so thats why the price is hitting the same level as a linear/sparse attention model BUT linear attention (hybrid) is only good at long ctx bench, and suck at knowledge task. G3F is great at knowledge, even #3 on Artificial Analysis Index. they cant be using any SSM/mamba variants hybrid (at least w/ standard attn) either as those suck at long ctx. Same as sparse attention, as you can see from DeepSeek 3.2's DSA So what black magic did they do? guess i'll never find out :( (unless i join google...??) contextarena.ai/?models=cohere…
English
Uri Alon retweetledi

for more context
on OpenAI's MRCR benchmark, curated at contextarena.ai by @DillonUzar , Gemini 3 flash achieved 90% acc @ 1 million ctx
this performance is SoTA across all models, most SoTA models cant even go past 256k ctx
at this length, you cant be using standard attention, it'll perform bad anyways, and ofc it'll be very expensive. (Gemini 3 flash is $0.5 in $3 out)
Some sort of efficient attention is implemented, so thats why the price is hitting the same level as a linear/sparse attention model
BUT linear attention (hybrid) is only good at long ctx bench, and suck at knowledge task. G3F is great at knowledge, even #3 on Artificial Analysis Index.
they cant be using any SSM/mamba variants hybrid (at least w/ standard attn) either as those suck at long ctx. Same as sparse attention, as you can see from DeepSeek 3.2's DSA
So what black magic did they do?
guess i'll never find out :(
(unless i join google...??)
contextarena.ai/?models=cohere…
English
Uri Alon retweetledi

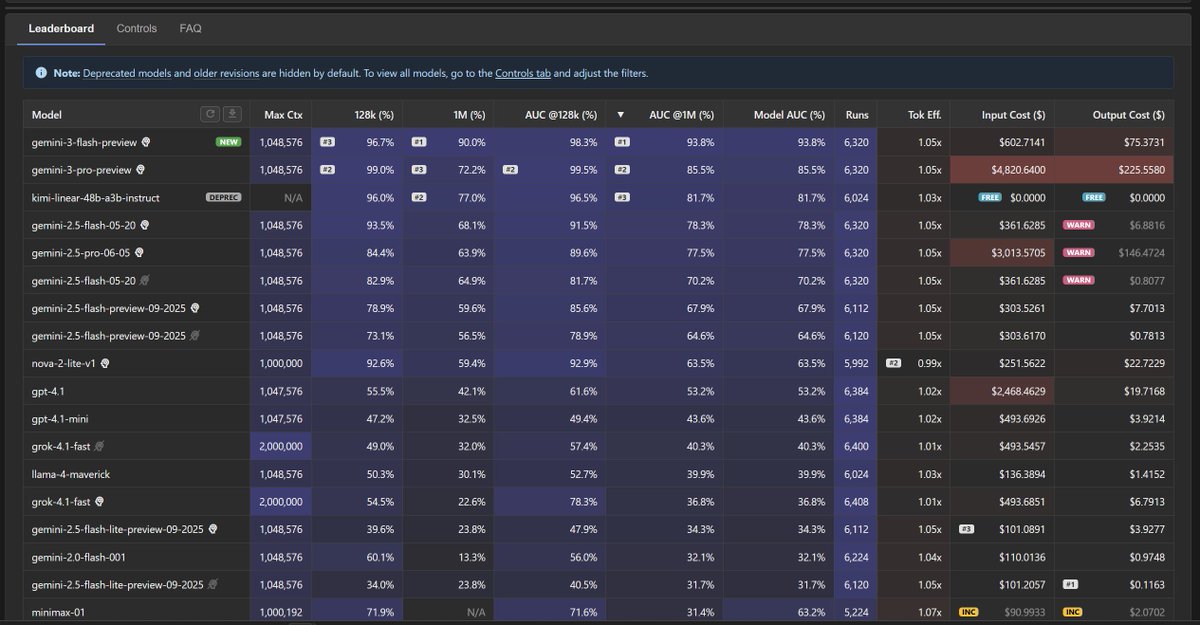
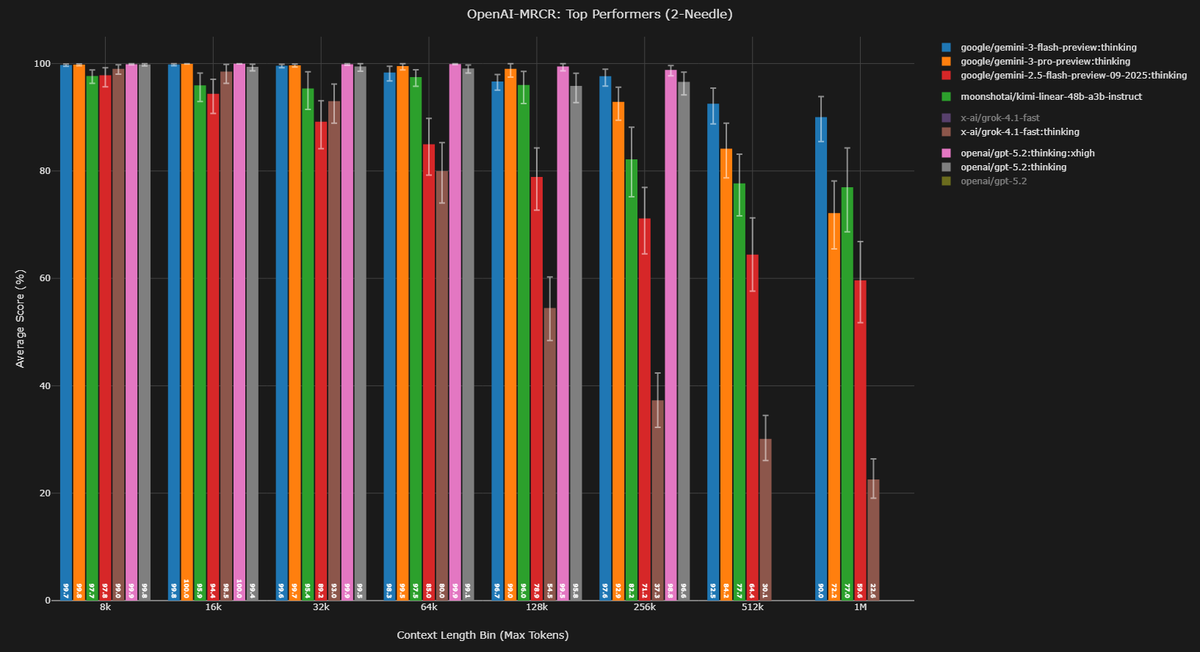
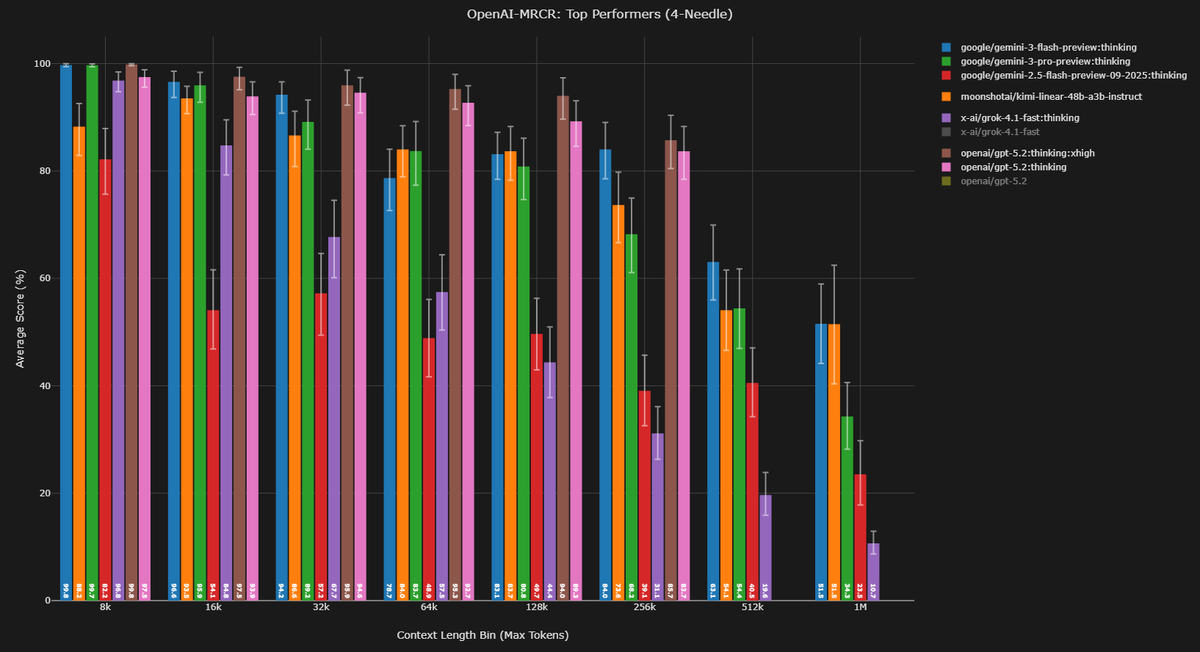
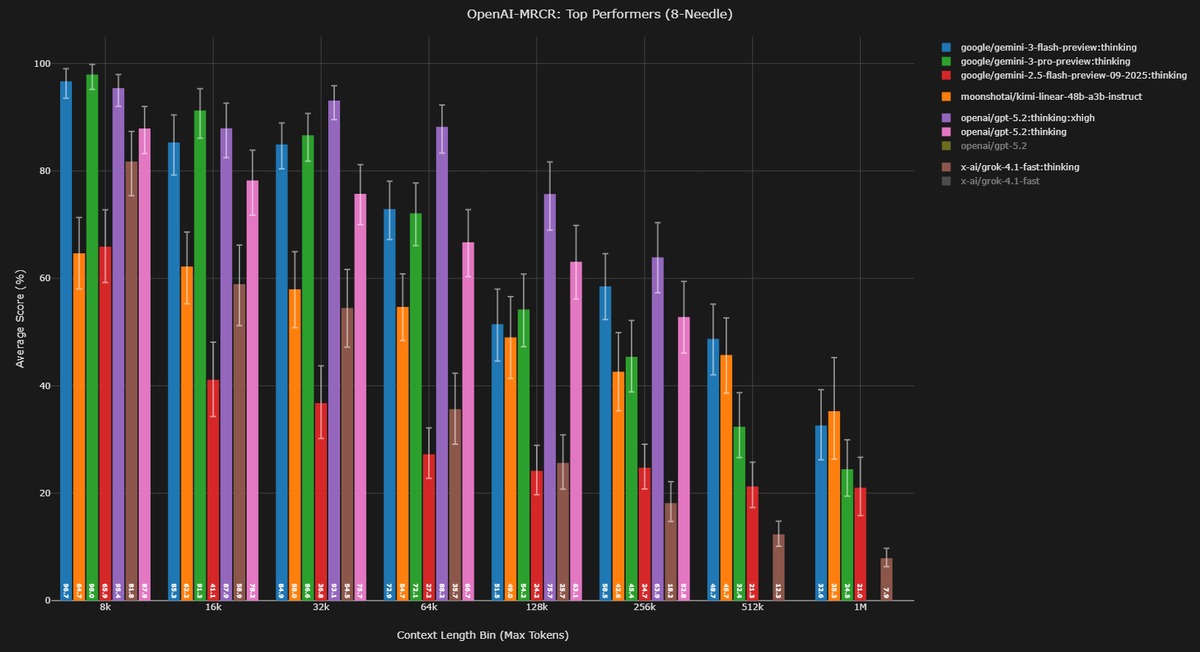
Context Arena Update: Added @GoogleDeepMind's Gemini 3 Flash Preview [12-17] to the OAI-MRCR leaderboards (2-, 4-, 8-needle)!
This sets a new bar for the efficiency tier. With reasoning set to High, Gemini 3 Flash is effectively matching and at ultra long context even beating its big brother Gemini 3 Pro!
On the harder 8-needle test, Flash hits 71.6% AUC @ 128k (Rank #3), near tying with Pro (73.0%). But at the 1M mark? Flash actually pulls ahead to take the top spot, scoring 49.4% AUC (Rank #1) while Pro drops to 39.0%.
I will be replying with the Minimal reasoning tests very soon (to be the "no-reasoning" version) to see the baseline capability. I've also been testing Medium/Low, and might release if there is a clear difference, stay tuned.
gemini-3-flash-preview:thinking results:
4-Needle Performance (@ 128k / @ 1M):
AUC: 85.5% (Rank #5, vs Gem 3 Pro: 85.8%) / 68.0% (Rank #1, vs Gem 3 Pro: 57.3%)
Pointwise: 83.1% (vs Gem 3 Pro: 80.8%) / 51.5% (vs Gem 3 Pro: 34.3%)
8-Needle Performance (@ 128k / @ 1M):
AUC: 71.6% (Rank #3, vs Gem 3 Pro: 73.0%) / 49.4% (Rank #1, vs Gem 3 Pro: 39.0%)
Pointwise: 51.5% (vs Gem 3 Pro: 54.2%) / 32.6% (vs Gem 3 Pro: 24.5%)
Full data: contextarena.ai
Congrats to @GoogleDeepMind! Enjoy.
NOTE: I have some updated Gemini 3 Pro scores, fixing some API error results, however, this doesn't change this post.
@GoogleDeepMind @googleaidevs
@OpenAI @OpenAIDevs
@Kimi_Moonshot
@xai
English
Uri Alon retweetledi

Gemini 3 Flash is live. ⚡️
We’ve packed Gemini 3’s Pro-grade reasoning into a leaner model with Flash-level latency, efficiency, and cost.
It's my favorite model to use – the latency feels like a real conversation, with the deep intelligence intact.
Available in the API, Gemini App, and Search. Give it a spin.
bit.ly/4pTo5YU
English
Uri Alon retweetledi

We’ve pushed out the Pareto frontier of efficiency vs. intelligence again.
With Gemini 3 Flash ⚡️, we are seeing reasoning capabilities previously reserved for our largest models, now running at Flash-level latency. This opens up entirely new categories of near real-time applications that require complex thought.
It’s available in the API, and rolling out today as the default model in AI Mode in Search and Gemini app globally.
Read more on the blog at: bit.ly/4pTo5YU
More in thread ⬇️
English

הנה משהו שיותר אנשים צריכים לדעת: להיות עני בישראל זה לא סתם באסה אלא גם ממש, אבל ממש יקר. אדם עני כמעט תמיד יידרש לקנות את המוצר הכי פחות משתלם -אין לו כסף למוצר החסכוני יותר בחשמל, אין לו כסף למקום אחסון שיאפשר לו לקנות את החבילות הגדולות והזולות יותר או שפשוט הוא לא יכול להרשות לעצמו אותה. הוא יסחב, כדוגמה וכמשל, במשך שנים אוטו מתפרק שכל פעם צריך לתקן ושאוכל המון דלק פשוט כי החלפה לרכב חסכוני היא מעבר למה שהוא אי פעם יוכל להרשות לעצמו.
הוא תמיד ייאלץ לסחוב אחריו בריבית כל הוצאה גדולה - כי אין לו את הכסף לשלם בתשלום אחד ולכן יידרש לקחת הלוואה (בין אם כאשראי צרכני או בצורה אחרת).
בכל פעם שיעמוד בהתמודדות מול הממשלה, הוא יוכל להרשות לעצמו רק את הטיפול הזול והבסיסי ביותר (אם בכלל). הוא לעולם לא יוכל להרשות לעצמו את העו"ד או הרו"ח או סוכן המשכנתא שיחסוך לו הון.
אלו סתם דוגמאות לתופעה רחבה יותר. אנשים ממעמד ביניים גבוה מסתובב בעולם עם איזו תחושה שמה שמפריד בינם לבין השכן העני הוא בעיקר 'ידע' קסום כזה או יכולות כשבפועל הם פשוט מתחילים מנקודת פתיחה טובה לאין שיעור. ביני לבין אבא שלי יש היום, בהערכה גסה, 4-5 עשירונים. יש שורה מאוד ארוכה של דברים שאני מוציא עליהם פחות ממנו *בגלל* שאני עשיר יותר. ככה זה. עוני זה יקר.
עברית
Uri Alon retweetledi

Today we entered the Gemini 3 era, our next step on the path toward AGI. ⚡
Gemini 3 is our most intelligent model that combines capabilities like multimodality, long context and reasoning, so you can bring any idea to life.
Explore more of what you can do and build with Gemini 3 🧵⬇️
English
Uri Alon retweetledi

This is Gemini 3: our most intelligent model that helps you learn, build and plan anything.
It comes with state-of-the-art reasoning capabilities, world-leading multimodal understanding, and enables new agentic coding experiences. 🧵
English

חדשות מדיניות AI: הוועדה הלאומית להאצת בינה מלאכותית (ועדת נגל) הגישה אתמול בלילה את מסקנותיה. אמ;לק - המצב גרוע. אין תכנית לאומית מסודרת. ישראל מפגרת מאחור. הסביבה הרגולטורית עוינת. אין מספיק מחקר וכוח אדם לתמוך בהובלה בתחום. נדרשת הקמת מטה מרכזי עם סמכויות חקיקה וביצוע >>
עברית
@sarahookr Does generated code really have any effect on the discipline of computer science?
English

I think it is very okay that computer science as a discipline is radically changing because of generated code.
The goal of education should be to teach how to think about problems, and to know enough to know what is useful to ask.
English

taking it a step further, I'd say in many cases using the algebra jargon is harmful to understanding, and its better to just describe whats really going on. ie, "we add an L2 penalty term" --> want the sum of squares to be small. "project to vocab space" --> compute similarity to each vocab item.
(((ل()(ل() 'yoav))))👾@yoavgo
i'll elaborate: a common computation pattern in DL happens to coincide with a known operator in linear algebra (matmul), and so we conveniently borrow linalg notation and terminology (matrices, vectors, ranks, norms). but this is just jargon. the algebric properties arent needed.
English