
We're organizing a visual Q&A benchmark challenge at KDD, focusing on the Multimodal RAG task. Join the CRAG-MM Challenge! More details here:
aicrowd.com/challenges/met…
English
Seungwhan Shane Moon
25 posts
@shane_moon
| Research Scientist @ Facebook | | PhD @ LTI SCS, CMU |




AnyMAL: An Efficient and Scalable Any-Modality Augmented Language Model paper page: huggingface.co/papers/2309.16… present Any-Modality Augmented Language Model (AnyMAL), a unified model that reasons over diverse input modality signals (i.e. text, image, video, audio, IMU motion sensor), and generates textual responses. AnyMAL inherits the powerful text-based reasoning abilities of the state-of-the-art LLMs including LLaMA-2 (70B), and converts modality-specific signals to the joint textual space through a pre-trained aligner module. To further strengthen the multimodal LLM's capabilities, we fine-tune the model with a multimodal instruction set manually collected to cover diverse topics and tasks beyond simple QAs. We conduct comprehensive empirical analysis comprising both human and automatic evaluations, and demonstrate state-of-the-art performance on various multimodal tasks.
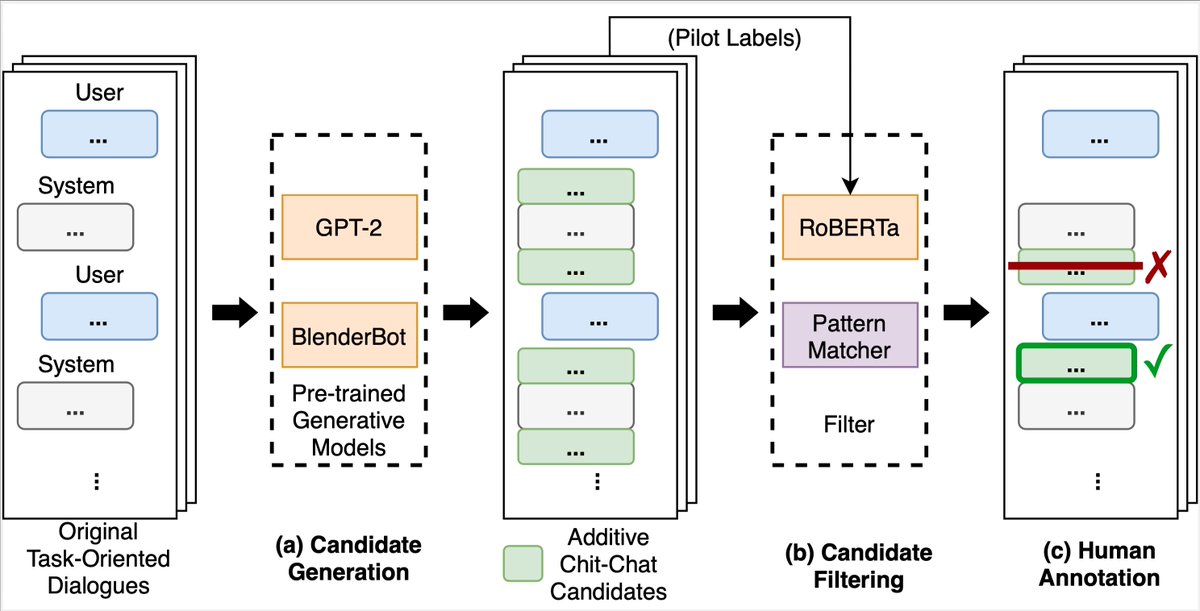
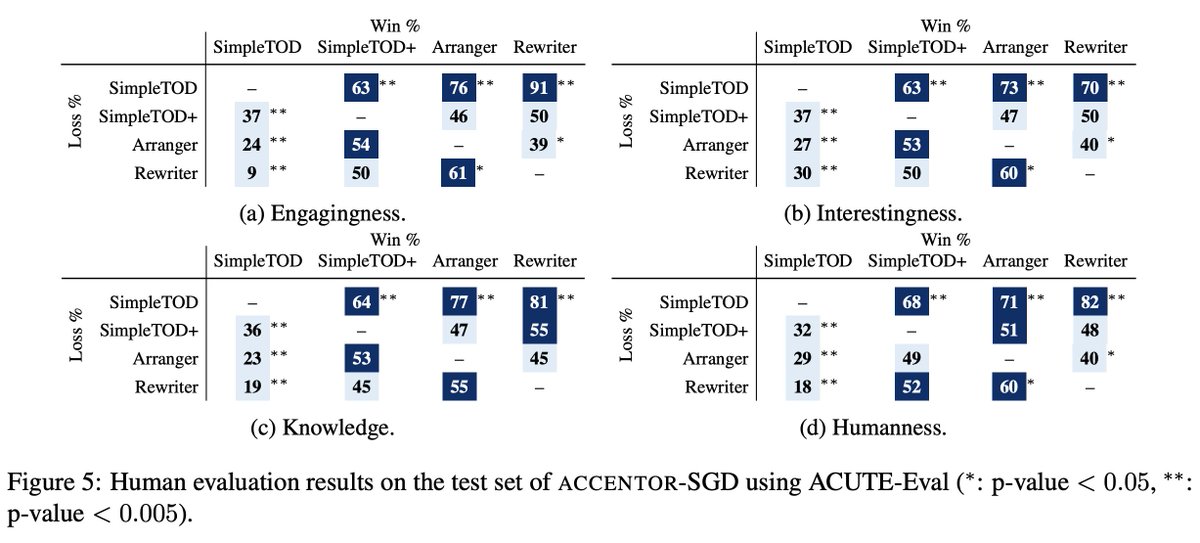
We are releasing ACCENTOR, a new data set that combines contextual chit-chat and traditional task-oriented dialogs. Automatic & human evaluations show our models can code-switch seamlessly, making virtual assistant conversations more natural & interactive. github.com/facebookresear…
Hey <wake-word>, tell me about Punta Cana🇩🇴. Our #emnlp2020 paper introduces a conversational information-seeking dataset on geographic entities. 📜Paper + 📁Dataset + 💻Code: curiosity.pedro.ai Gather 5H: Nov 18 18UTC w/Paul Crook, @shane_moon, Stephen Wang 1/4
We’ve released SIMMC, a data set on situated and interactive multimodal conversations, to help conversational AI researchers ground conversations in a co-observed and evolving multimodal context. A challenge track at DSTC9 around SIMMC is currently live. ai.facebook.com/blog/simmc-a-d…

