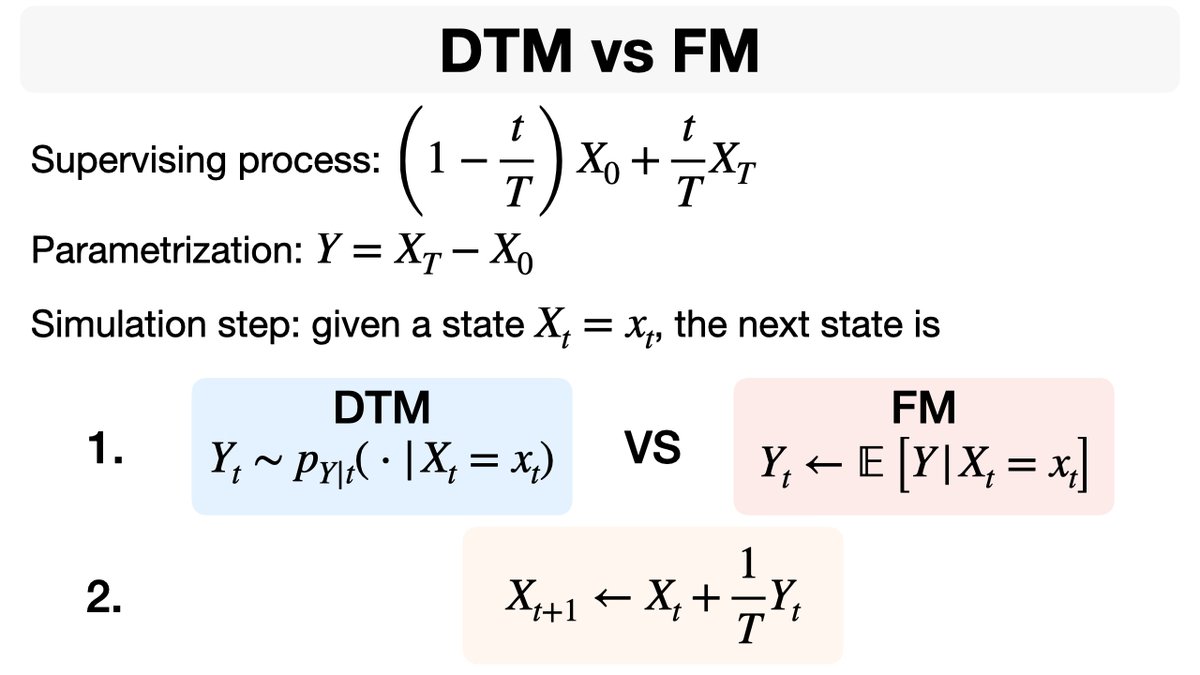
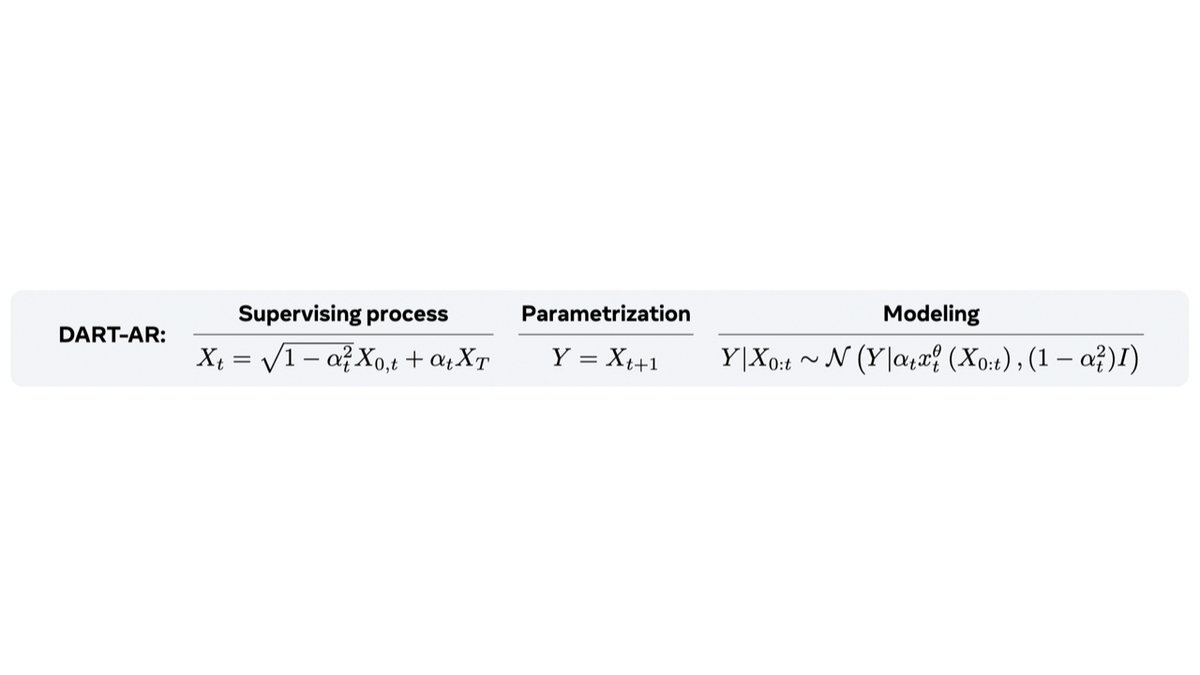
After multiple requests for the code of the visuals from my talk about Transition Matching, I made a notebook that reproduces the DTM vs. FM GIF!
This demo is a good way to build intuition on how TM and FM differ.
github.com/neta93/visual-…
@urielsinger
English