
Uriel Singer retweetledi

New research from @bfl_ml 🥳
Meet Self-Flow: our self-supervised framework for image, audio, video & world models 🤖
bfl.ai/research/self-…
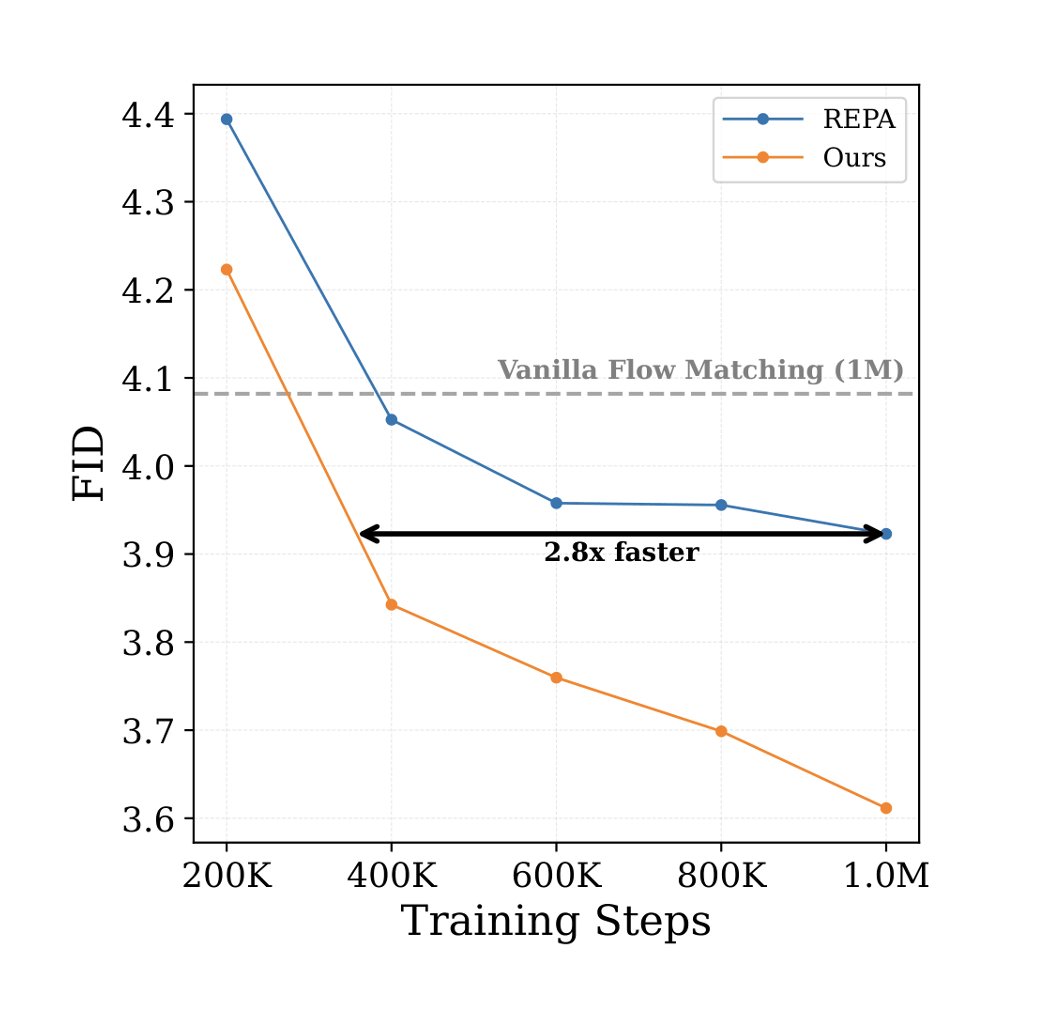
Do generative models really need DINO to learn strong representations? We propose teaching them directly via a joint framework instead 🧵
English









