Sabitlenmiş Tweet

we just released our first model: SID-1
it's designed to be extremely good at only one task: retrieval.
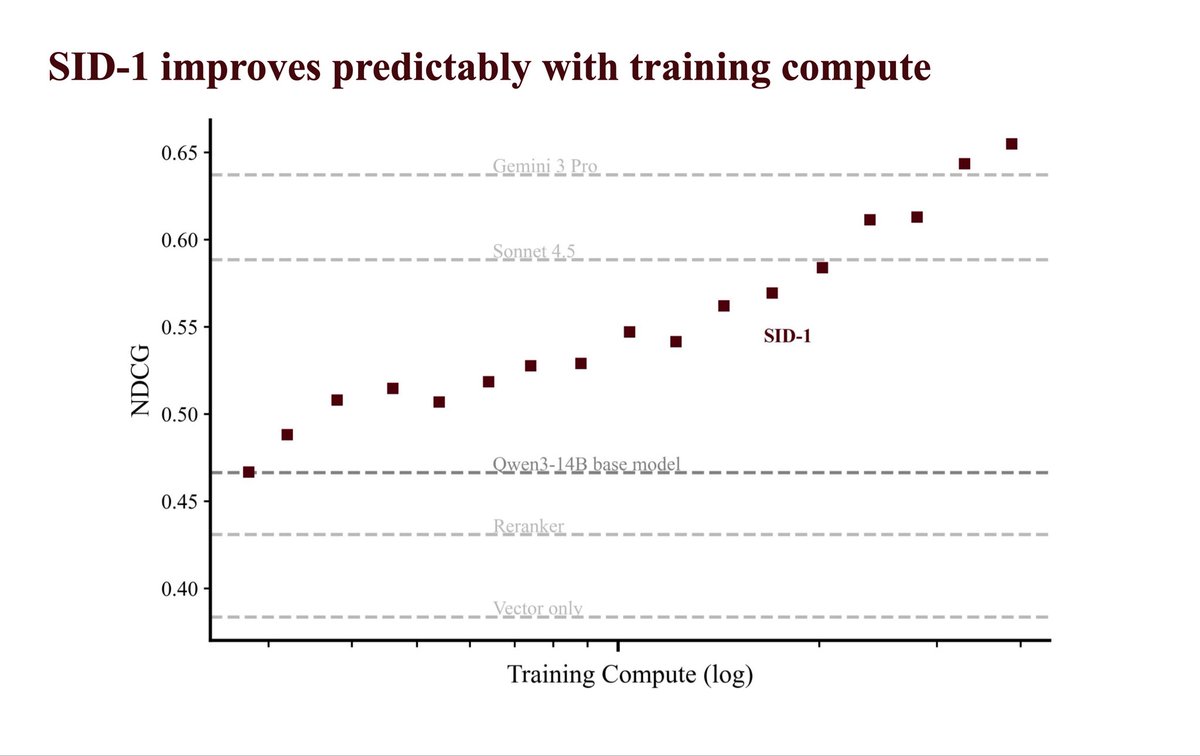
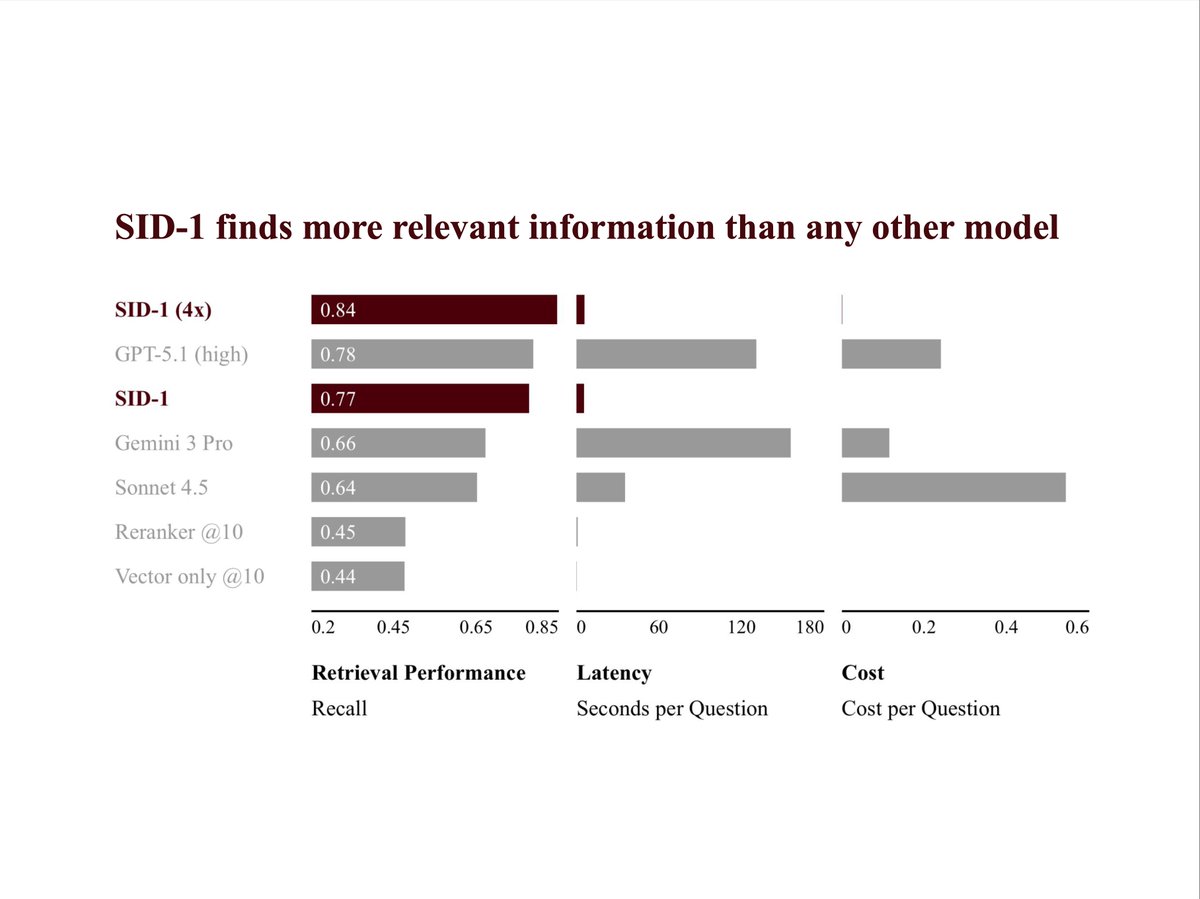
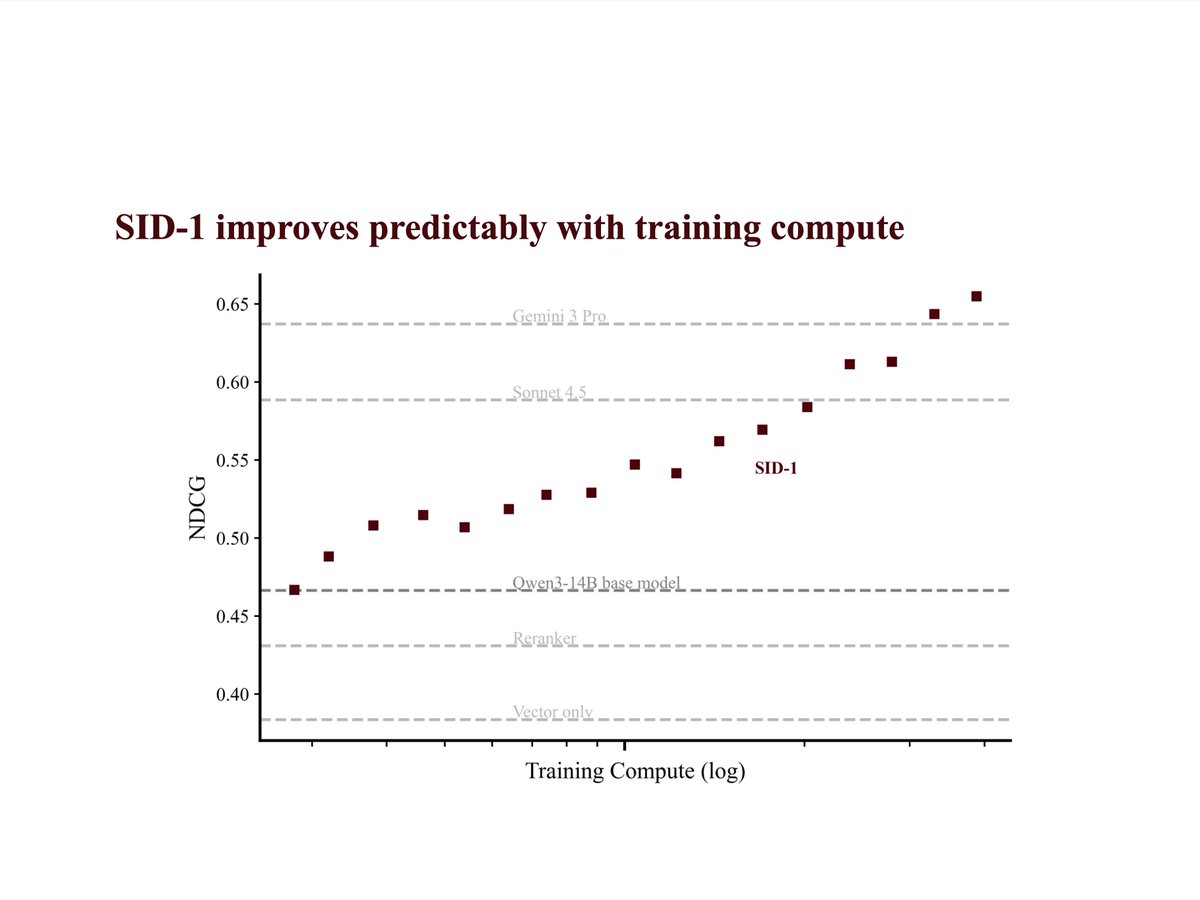
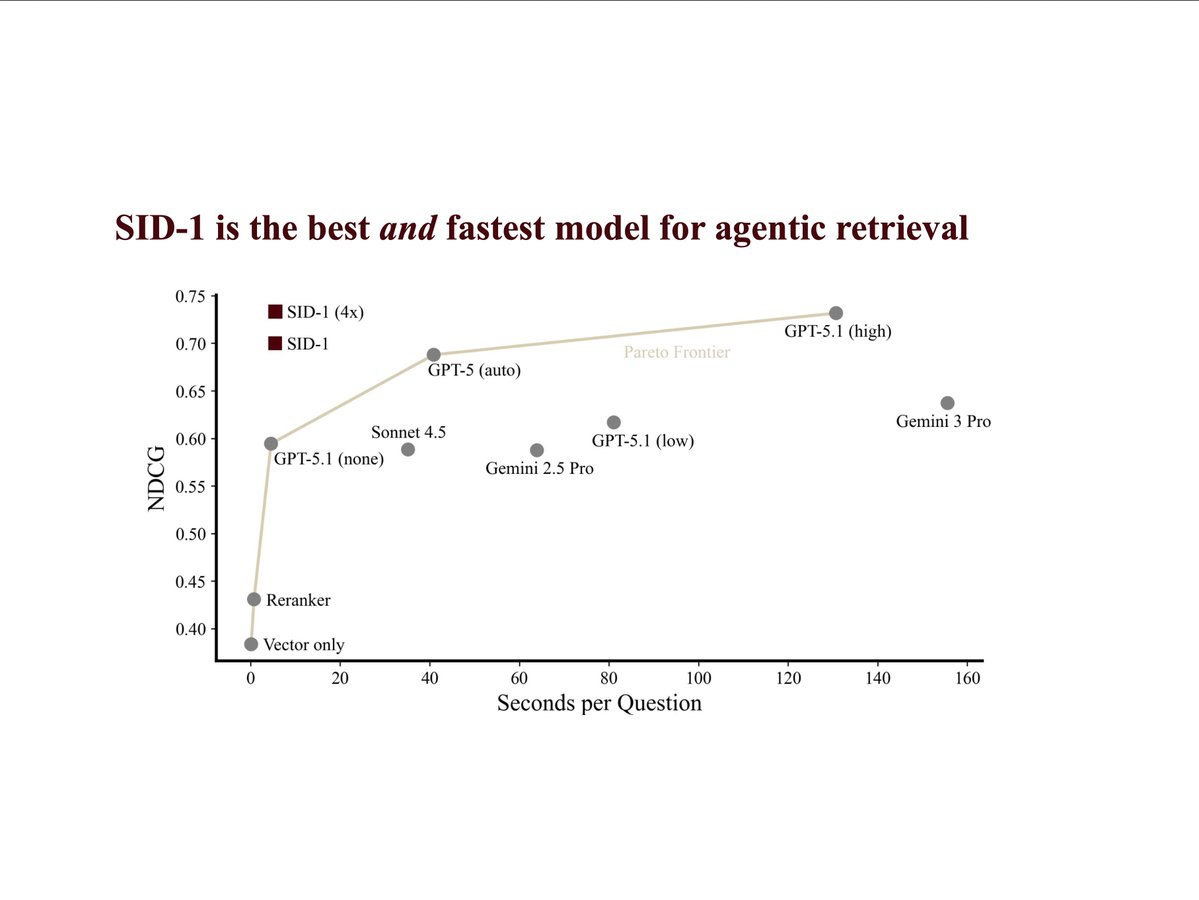
it has 1.8x better recall than embedding search alone (even with reranking) and beats "agentic" retrieval implemented using all frontier LLMs, including the really large and expensive ones (see chart).
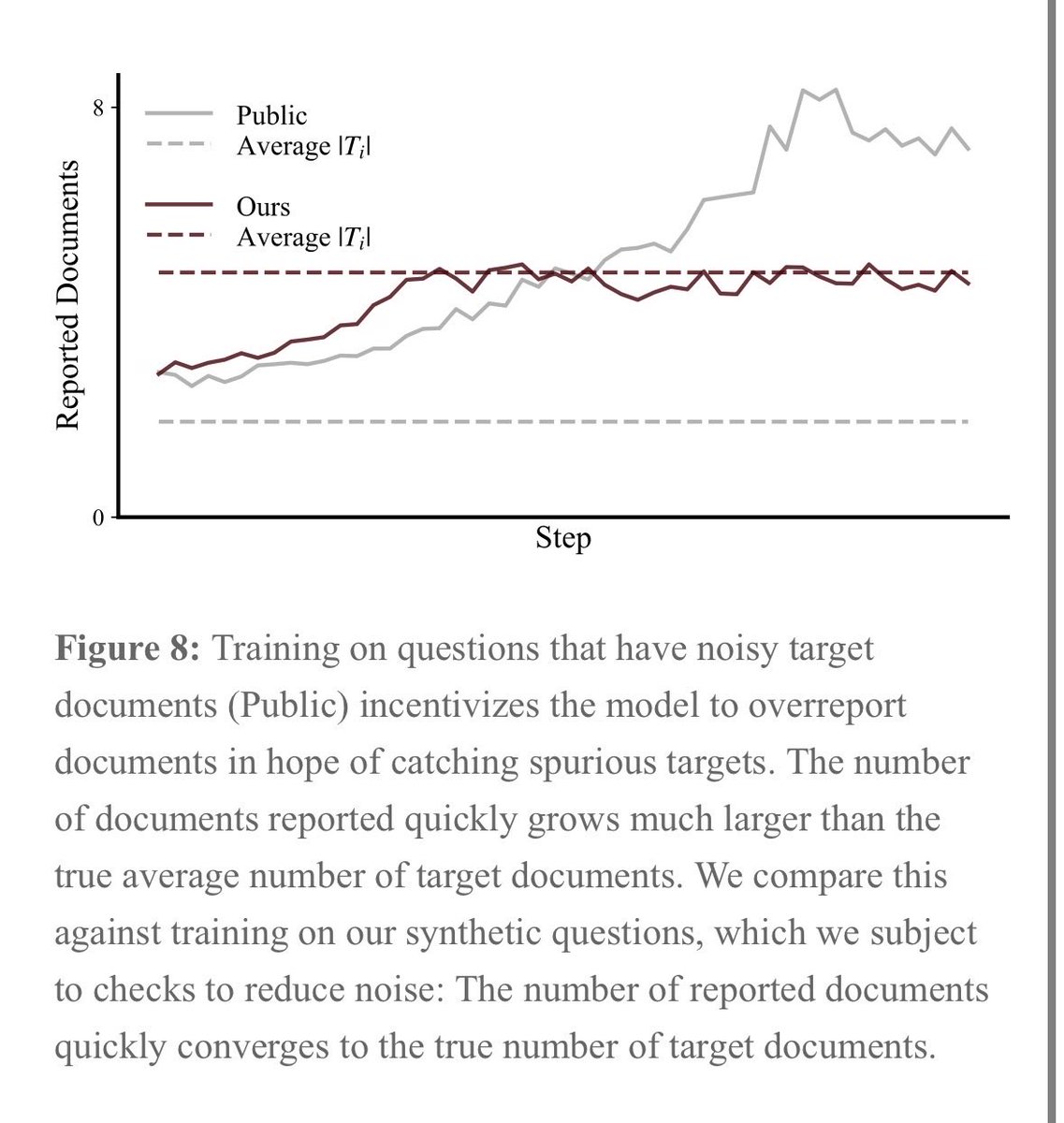
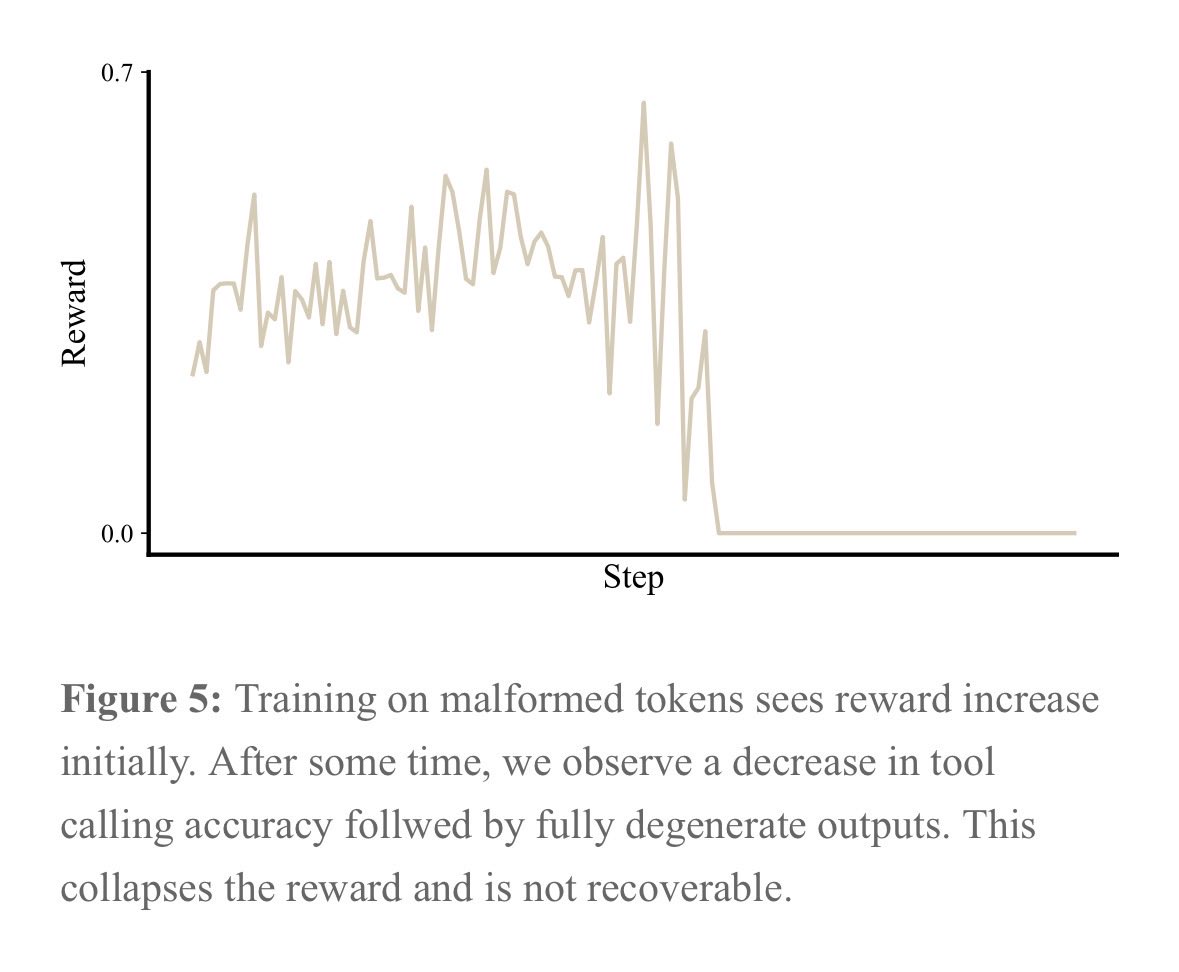
we trained SID-1 using multi-environment, multi-turn RL on Qwen. it was a lot of work (a lot of which is documented in our tech report -- see pinned tweet).
our RL environments build on the idea that humans with search tools can find almost any information given sufficient iteration. like humans, SID-1 makes a first search, read the results, and adapts its strategy.
and it can do this much faster *and* better than frontier LLMs: 24x faster than GPT-5.1, 27x faster than Gemini 3 Pro.
the better part is critical! if a model is fast and wrong, it's just wrong. that's why we trained SID-1 until it was the most likely to deliver the correct results. bar none.
we're partnering with a small number of companies today and have a waitlist for everyone else. (we don't have enough inference compute for everyone yet).

English