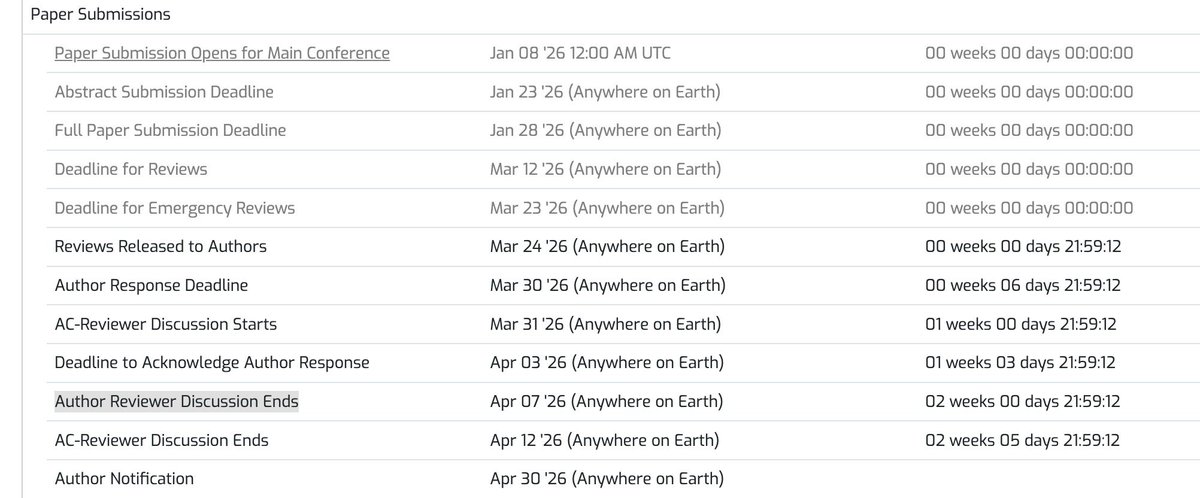
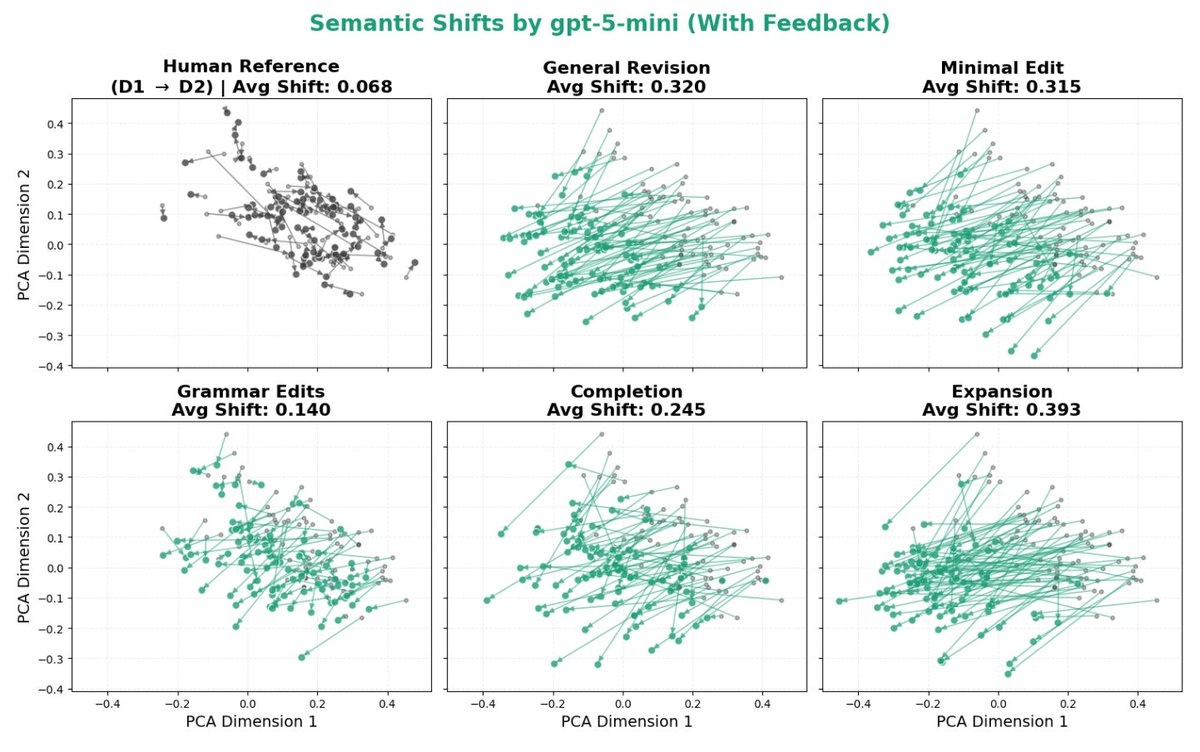
Sabitlenmiş Tweet

🚀New preprint: DAVE — Distribution-aware Attribution via ViT Gradient DEcomposition.
1/11 🔍 What’s new:
We fix a persistent issue in ViT explainability: unstable, artifact-heavy pixel attributions. DAVE yields fine-grained pixel-level maps without patch-grid saliency.

English