@sidgairo18 This is exactly the mess that TMLR solved. There are no scores in round-1 of reviews. There is only yes/no decision after rebuttals. There are enough reasons why every system needs to converge to this.
English
Anirbit
172 posts

@anirbit_maths
Lecturer in ML, The University of Manchester Action Editor @ TMLR Associate Editor @ ACM-TOPML


📢 Open-sourcing the Sarvam 30B and 105B models! Trained from scratch with all data, model research and inference optimisation done in-house, these models punch above their weight in most global benchmarks plus excel in Indian languages. Get the weights at Hugging Face and AIKosh. Thanks to the good folks at SGLang for day 0 support, vLLM support coming soon. Links, benchmark scores, examples, and more in our blog - sarvam.ai/blogs/sarvam-3…


it always disappointed me that such a small subset of mathematical ideas matter for AI i miss doing real math
Demis Hassabis’s “Einstein test” for defining AGI: Train a model on all human knowledge but cut it off at 1911, then see if it can independently discover general relativity (as Einstein did by 1915); if yes, it’s AGI.
🚨My God ! I was not understanding why this Video is Viral , the Prof is just giving a Lecture normally shifting from one language to other. Then I come across the post by @thebetterindia . And I came to know that it was a Realtime translation.





One of the best visual explanations I've ever seen for why scaling Transformers works, but is suboptimal, as it's just brute-forcing things, by @YesThisIsLion (co-author of the Transformer) on @MLStreetTalk "In the (rejected) paper "Intelligent Matrix Exponentiation", they show the decision boundary of a classic MLP with a ReLu/Tanh activation function on the classic Spiral dataset." "You can see they both technically solve it with great scores on the test set. Next, they show the decision boundary of the "M-layer" they propose in the paper. And it represents the spiral ... as a spiral!" "Shouldn't we? If the data is a spiral... shouldn't we represent it as a spiral?" "If you look back at the decision boundaries of the MLP, it's clear that you just have these tiny, piecewise separations without learning the concept of a spiral. That's what I mean!" "If you train these things enough, it can fit the spiral and get a high accuracy. But there's no indication that the MLP actually understands a spiral. When you represent it as a spiral, it extrapolates correctly, cause the spiral just keeps going out."

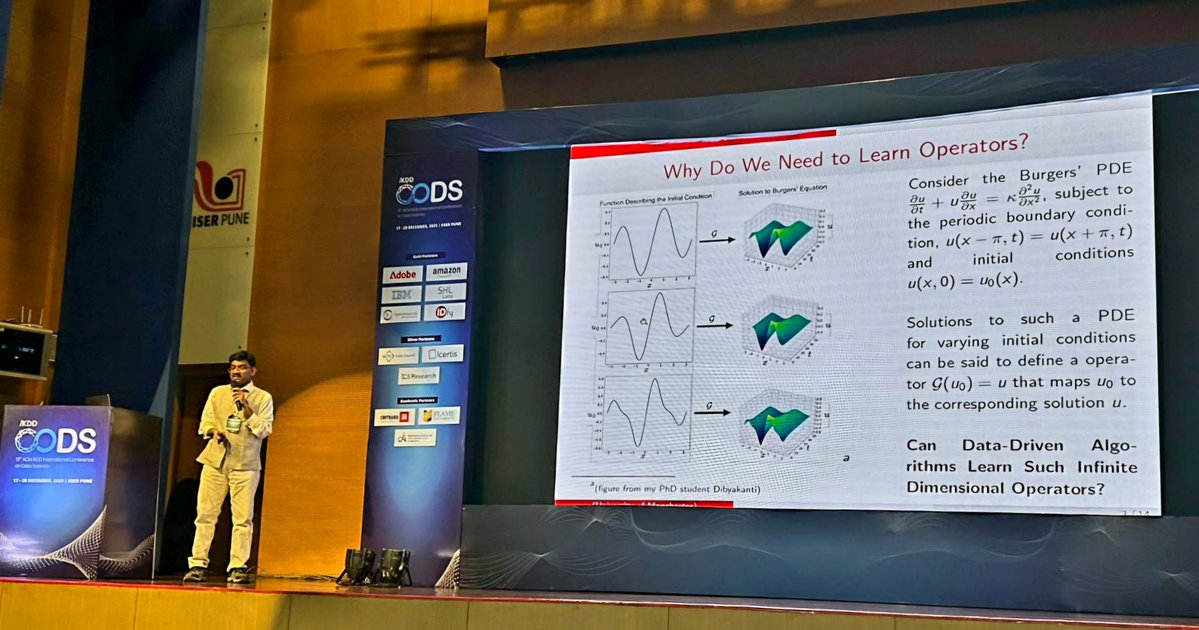
Gave my "new faculty highlight" talk at the ACM IKDD #CODS 2025 - where I outlined a vision for neural operator research - and reviewed our 2 #TMLR papers from 2024, in the theme.


At the #Neurips2025 mechanistic interpretability workshop I gave a brief talk about Venetian glassmaking, since I think we face a similar moment in AI research today. Here is a blog post summarizing the talk: davidbau.com/archives/2025/…