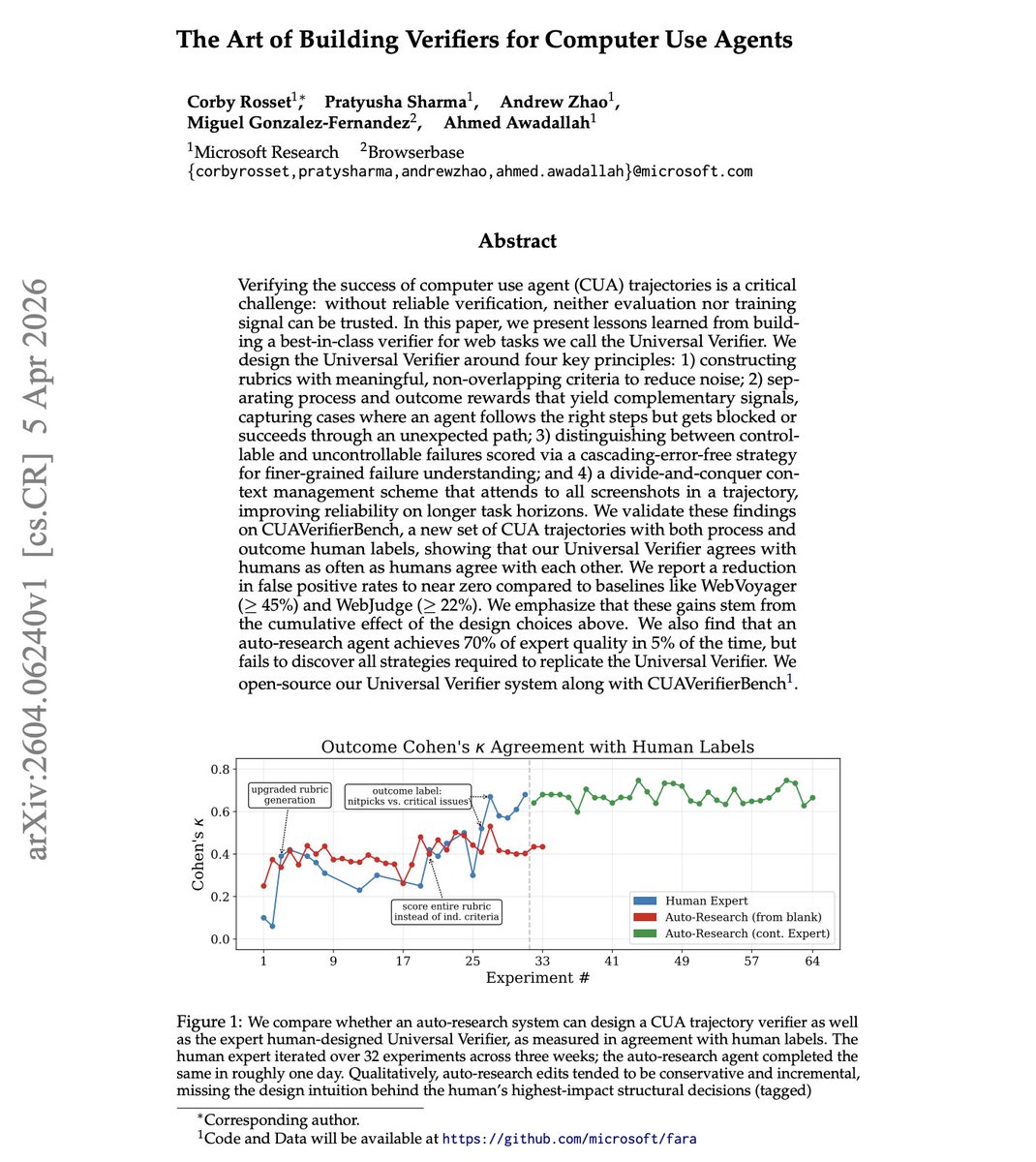
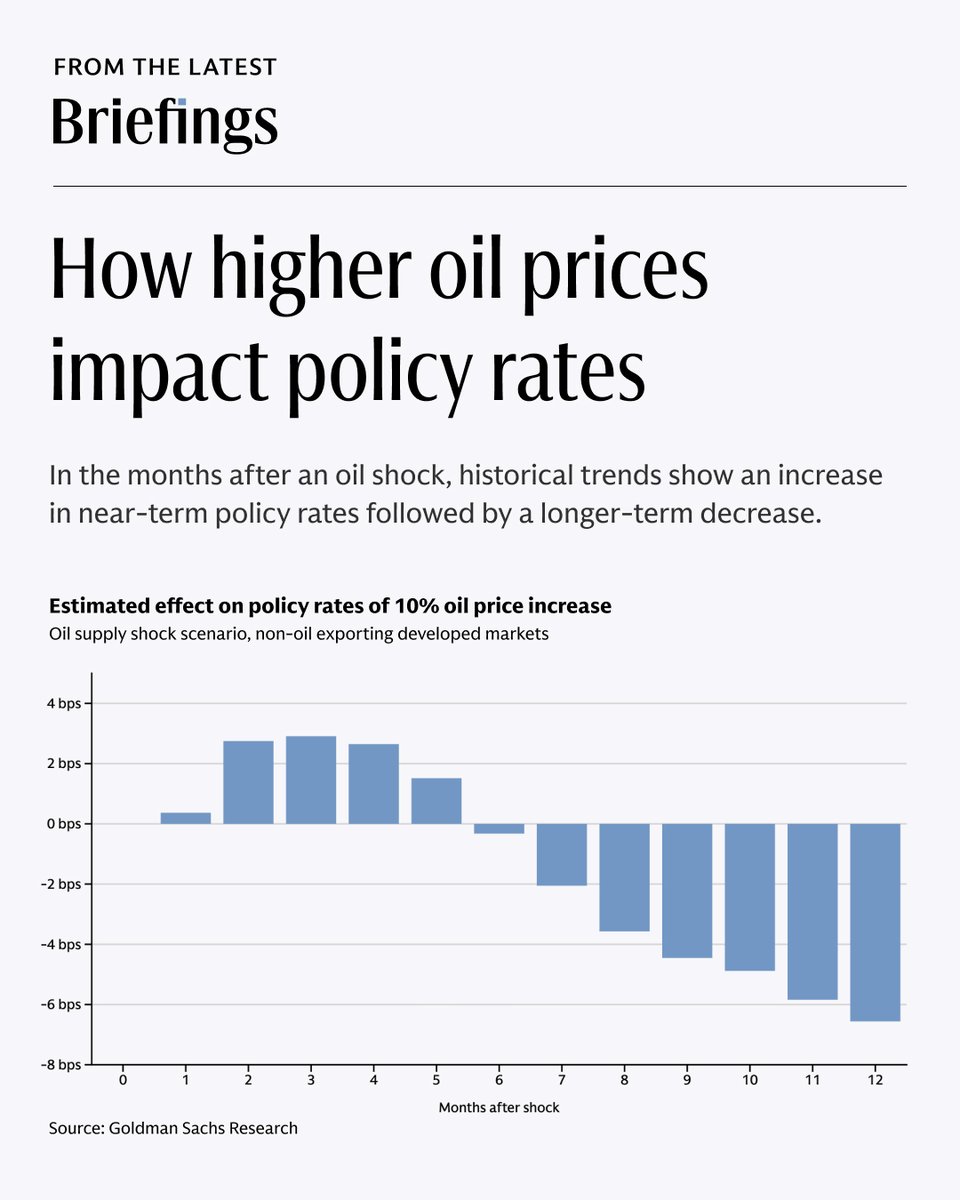
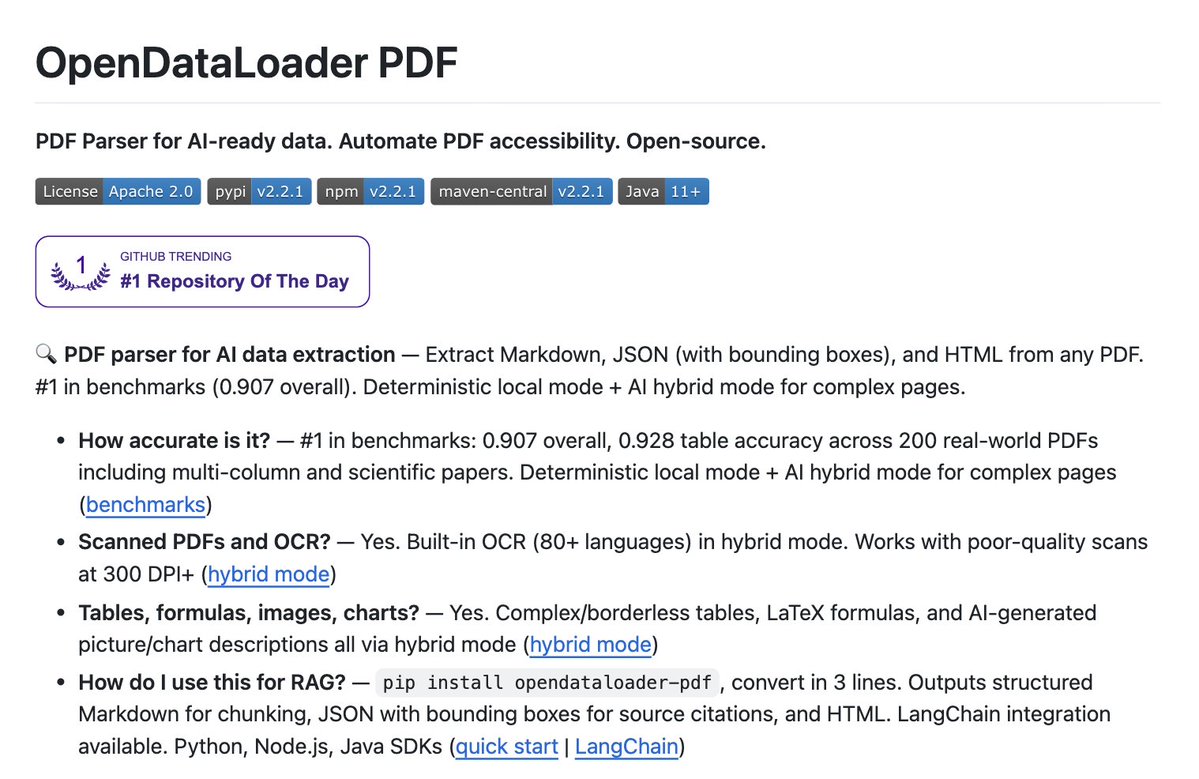
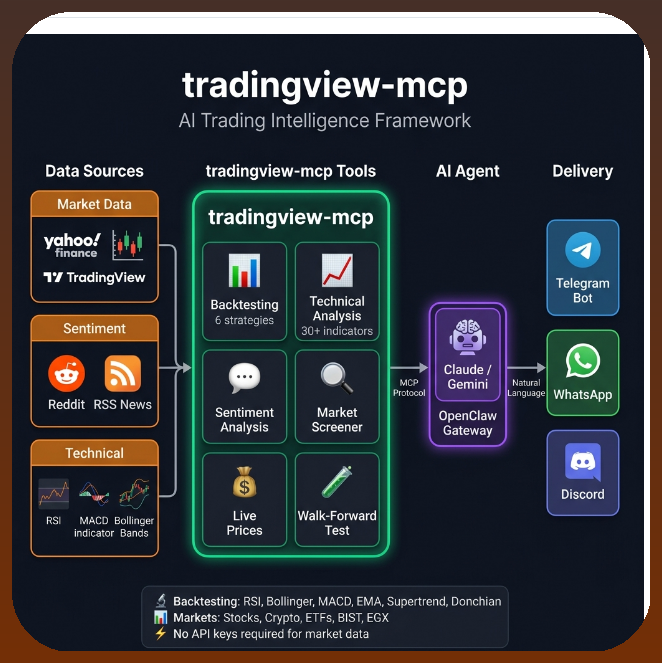
Sabitlenmiş Tweet

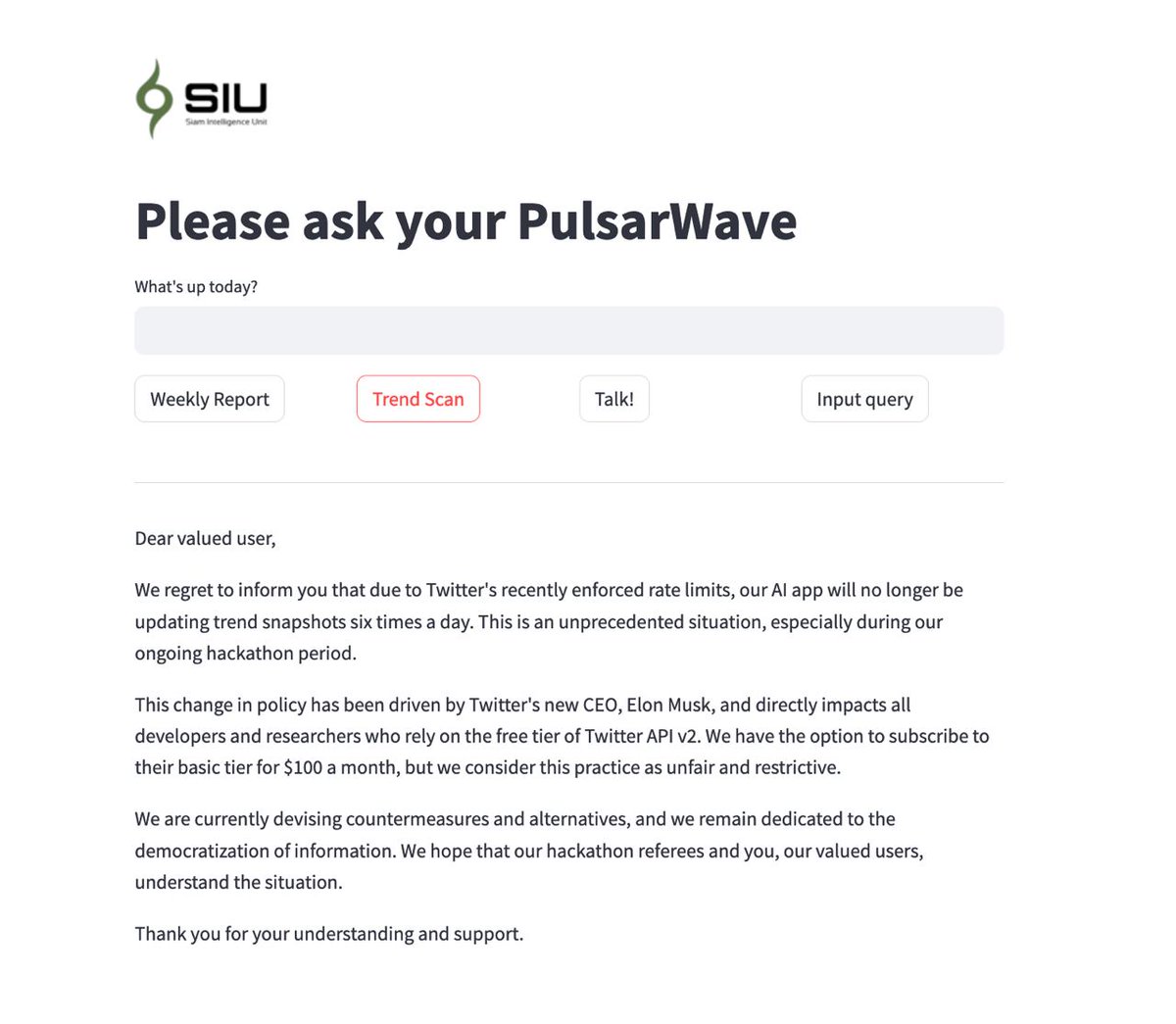
Friend! An update on our #AIapp, we've been impacted by recent changes to Twitter's API rate limits. Unfortunately, we can no longer provide real-time trend snapshots every six hours as research. We're seeking alternatives & remain committed to #DataDemocracy. More updates soon!
English