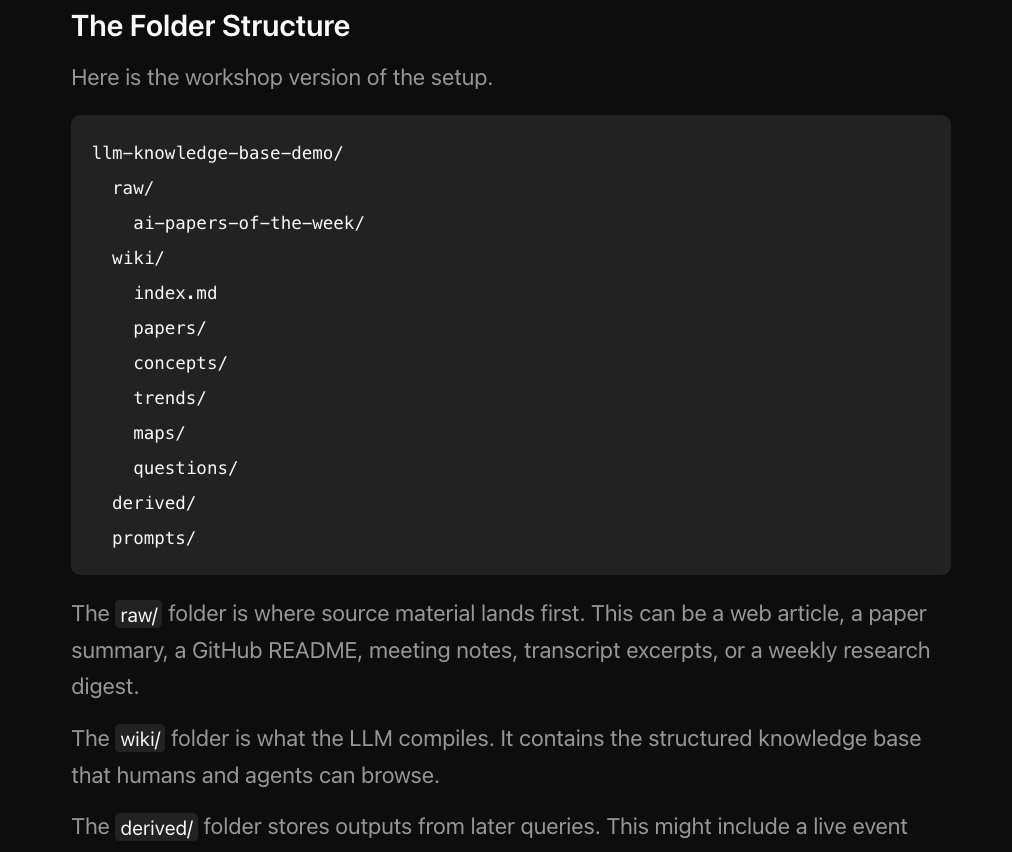
D. R. Arthur retweetledi

The Besties React to Greg Brockman’s Diary in the Elon/Sam Altman Trial 😂
Jason:
“ Greg Brockman, the co-founder (of OpenAI), was journalmaxxing apparently.”
Friedberg:
“I just don’t know why Greg Brockman's got a friggin’ diary where he's literally documenting… I mean, I love the guy, but what the f**k is he thinking?”
“You're just sitting here at home like, let me write about the crime I'm committing, and let me record it, and by the way, let me never delete it.”
Sacks:
“It's not just journalmaxxing, it's discoverymaxxing.”
Jason:
“It’s like that scene from The Wire!”
English