Sabitlenmiş Tweet

Today we present Morpheus, a persistent enterprise simulation platform designed to make Continual Learning a reality. Morpheus is the world’s first real world Reinforcement Learning environment.
Every Reinforcement Learning environment operates in the game world. Benchmarks like Atari, OpenAI Gym, MuJoCo, and Procgen are all small, game-like worlds that reset every few minutes.
But the real world never resets. A business keeps running and evolving everyday.
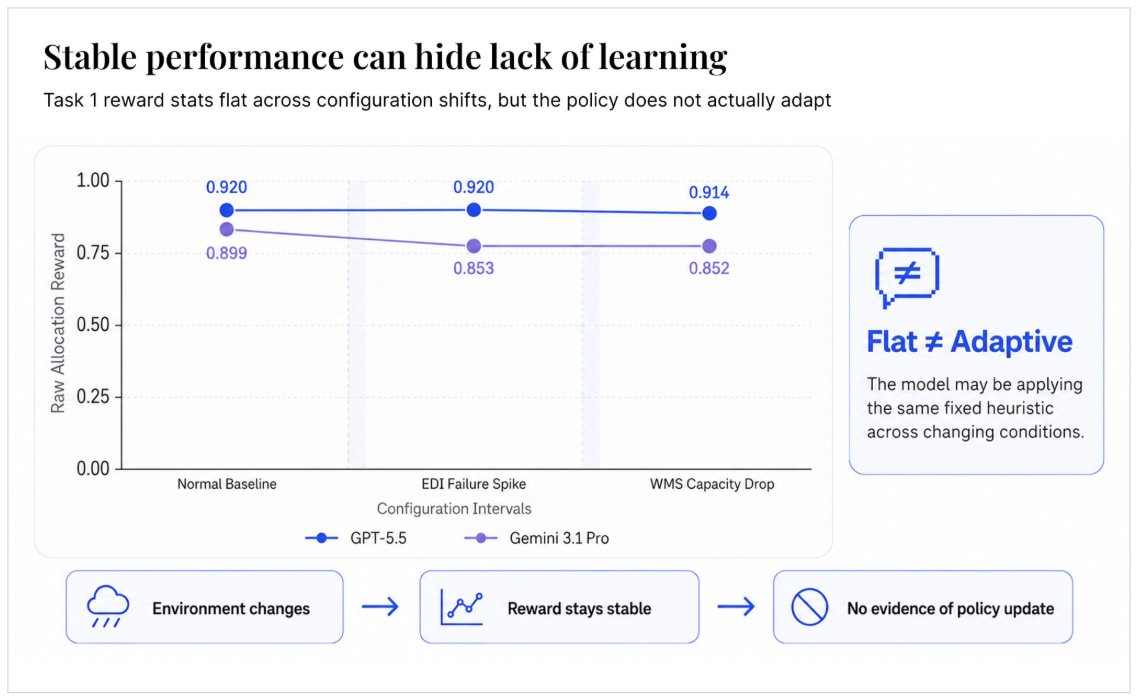
We tested how frontier LLMs would perform in realistic and dynamic business environments 🧬on Morpheus. The main conclusion was that LLMs are not continual learners.
🧵Here’s how we did it and what we learned:
English