
/MachineLearning retweetledi

The new Codex Goals feature is able to pursue tasks indefinitely, so how useful is it?
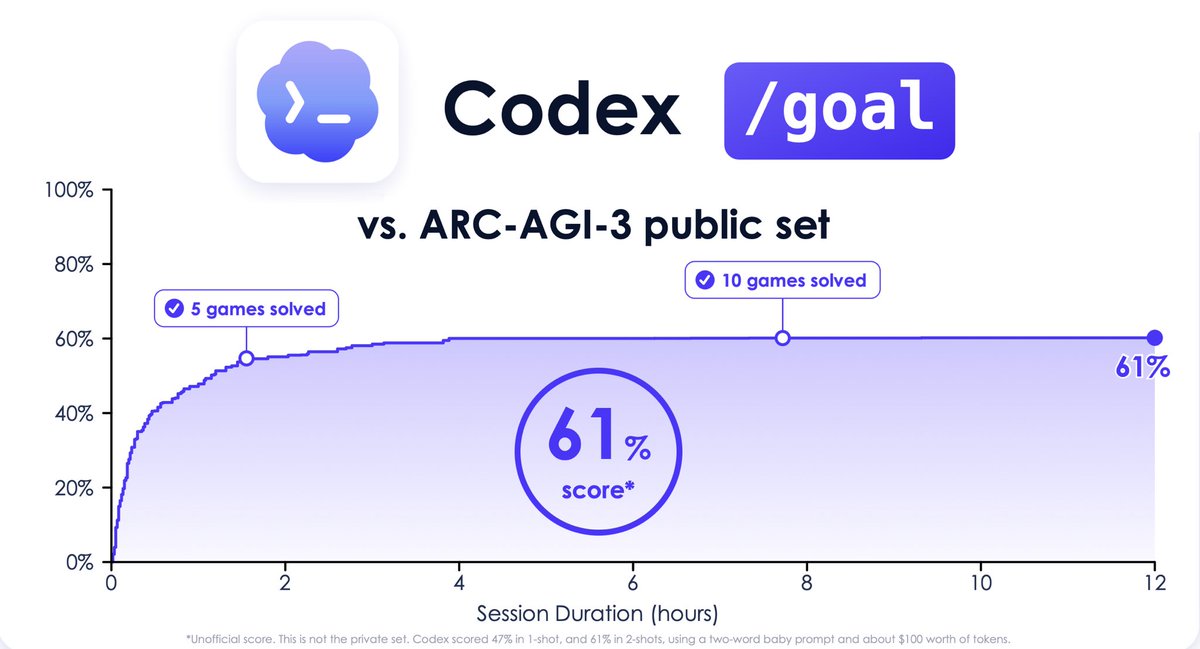
I ran it on the public ARC-AGI-3 games. After 160 hours and 30k actions it scored 61%
Codex gets the most work done within 4 hours. Afterwards, it begins to stagnate, and wait times increase
I am crestfallen it scored so well. I used a two-word baby prompt to “reverse engineer” the games during play. It had no prior knowledge of how the games worked
Due to the reverse engineering process, it scores well on its first play through. But once it beats a game, it can score perfectly on its next play through
On a few occasions I caught Codex trying to search for solutions on my computer and online. It follows your prompt closely, but if you’re not careful it will find loopholes when it’s frustrated
For example, when trying to solve Erdos problems, if it becomes faintly aware the problem is from Erdos, it does not hesitate to give up and say “the problem is listed online as Open, so it cannot / should not be solved”
Overall Codex Goals is fascinating, I can appreciate that it works for an unlimited amount of time. People shall value the virtue of patience once again 💺
It makes me wonder how well Codex Goals can do on the private set of ARC-AGI-3. I believe it’s possible to create benchmarks that can mog even the most devilish harness. In the coming weeks, Maze Bench will knock those scores down to 0% where they should be, ne’er to rise again
Arcprize Scorecard: arcprize.org/scorecards/6f4…
English


















