
10
16 posts



今天在朋友的 Tesla 维修站拆下的 HW3,图中红线圈出的地方,就是等效面积的 AI5 芯片!
- 单个 AI5 的真实算力是双 AI4 的五倍;8 倍的计算能力,9 倍的内存和 5 倍的带宽;
- 但颗 AI5 的工作负载与 Nvidia H100 相当,双芯片能达到 Blackwell 的性能,但成本和功耗要低得多;
- 针对边缘人工智能推理(INT4/INT2/FP8焦点)进行了彻底的简化和优化,非常适合 EV 与 Optimus;
- 完整的 AI5 计算目标为 2,000-2,500 TOPS(与 AI4 的 300-500 相比);
就像 Elon 说的:“AI5 将使汽车几乎完美,并大大增强 Optimus” AI5 将在美国(亚利桑那州的台积电+德克萨斯州的三星)建造,随着 Terafab 扩大生产规模!

中文
@fi56622380 @fin 多谢,fin老师是我这么多年遇到对行业和投资认知最有深度的牛人。大开眼界。半导体就2016年后日子好过一点,16年前没投资人看半导体。
中文

@smooth_shun @fin 生态还不行
另外,RISCV强调性价比,那么就无利可图,无利可图就吸引不到人才,没人才就发展不起来。你看sifive多少年了,还是只有那么可怜的估值
riscv的未来在中国
中文
今天芯片圈最大的新闻,莫过于Gerard在创立Nuvia CPU被高通收购五年之后,重新出发,新创立了ARM CPU公司,名字也跟之前非常像,叫Nuvacore
现在这个时间点做数据中心CPU,确实是赶上了CPU十年来最好的时代:
AI agent带来CPU短缺潮已经经隐隐浮现,AWS多个客户都提出要包揽所有Graviton ARM CPU产能
------------
这个消息对硅谷的芯片打工人吸引力是巨大的,Nuvacore这次的阵容都是功成名就的明星阵容,以前Nuvia创始团队重新集合,拿了红衫的投资,做面向 AI 基础设施/agentic computing 的通用ARM CPU。当年还是一个尚未完全被验证的大方向都能大获成功,而现在ARM CPU服务器正在风口浪尖上,前景和想象力和2019年Nuvia比起来大了太多了
上一次Gerard把Google,苹果platform architecture组的架构大佬挖了好多过去,这次的号召力只会强得多,240m的融资,已经验证过的路径和创始团队,肉眼可见的下一个增长风口,一定会让Nuvacore成为湾区最热门最受追捧的芯片startup,没有之一。毕竟这是一个肉眼可见能财富自由而且风险收益比极好的机会
----------
遥想当年Nuvia第一代CPU的发布赶上苹果M2时代,还是挺震撼的,Nuvia让高通在一年的时间CPU跑分进步了整整三代,单核跑分从2300变成3200,竟然超过了苹果M2 max一大截
可惜Nuvia Phoenix core从发布到最后上市拖了太久太久,中间苹果把牙膏挤爆了连着上市了M3/M4,于是Nuvia CPU上市之后从跟M2比较变成了跟M4比较,从期待中的C位变成背景板了
当年Nuvia的眼光非常超前,在2019年ARM CPU服务器市场占有率几乎为零的情况下,就是想从零开始打通这个市场,2021年被高通14亿美元收购之后,高通也给了无限的资源支持,扩招力度很大,给的薪水都是市面上最高一档的。
可惜大环境在2022年恶化的很快,加上高通的管理层战略眼光实在太差太短视,在业界ARM服务器生态都开始有起色的时候,为了股价节约开支,竟然再一次把自家的Nuvia CPU 服务器团队解散了(算上2015年已经解散过一次ARM服务器团队)
直到2025年,Nvidia的Grace ARM CPU都已经发布四年了,Vera ARM CPU都已经自研好久了,Amazon的ARM CPU Graviton都快占据CPU服务器新出货的50%了,高通才后知后觉谨慎的重启ARM服务器项目
所以这次Gerard从高通的高管位置把之前的创始团队拉出来自己干,可能是因为高通高层战略眼光实在太差屡屡错过机会,上次Nuvia想做ARM服务器,高通的承诺也因为大环境恶化没做数,结果被收购之后被高通取消了项目直接改做了laptop芯片和手机芯片
加上高通今年在手机销量上因为内存和存储历史级的巨额涨价,可以预见要受到重创(市场萎缩30%),能拿出的扩张预算有限,在高通能拿到的资源是受到掣肘的
而在创业公司里比在 Qualcomm 这种大平台里更容易拿到足够快的决策速度、团队纯度、产品定义权和资本叙事,于是选择在窗口已经被验证时重新集结老班底
但更可能因为,AI时代的CPU前景想象力真的太广阔了,完全值得重新投入一次,不是Gerard变了,而是外部市场变了
------------------------
进入2025年之后,AI agent的出现,隐隐让CPU重新变成了瓶颈
CPU服务器重新步入增长轨道,而且潜力巨大,有好几个因素:
1. 随着推理时代的到来,GPU演化到针对推理的系统级新架构,CPU 是永远在忙的总指挥orchestrator, 因为要追求token throughput,所以异构计算阶段变多 + 批处理数量batch越来越大,scheduling/routing/data flow复杂度变高,对orchestration要求也变高
所以在系统级异构推理架构里,AI加速器和GPU在CPU:GPU的配比上,也变得更为激进,从以前的1:4到Grace Blackwell的1:2,以后是很有希望达到1:1的比例的。Google TPU配Axion,Amazon Tranium配Graviton,Nvidia Rubin配自家Vera CPU
这条在我的去年11月半导体年终回顾写过,基本上在2026年成为了共识,虽然这部分主要是各家AI 芯片自研,并不是纯粹的CPU服务器,其实不算是外部CPU服务器的机会
2. 也是同一篇年终回顾里写到的:
从CPU视角去看agentic workload,routing和工具处理都在CPU上,如果把常用的agentic框架做profiling,比如SWE-Agent, LangChain, Toolformer,CPU最长可以占到90%的E2E端到端延迟,throughput瓶颈也更多的卡在CPU,CPU甚至能耗也超过了总能耗的40%
Agentic AI目前是一个CPU瓶颈更多的事情,Agent管理很多个CPU,再加上agent经常要开sandbox,很可能会成就CPU需求的新一波回暖
现在回看去年写的这个逻辑,潜力是非常大的。但其实年初可能并没有很大规模发生,年初的CPU增长和各家渲染的CPU短缺潮和这个逻辑暂时关系不大,更多可能是前几年的capex投入GPU的比例太大,造成传统CPU服务器投入不够,所以需求上升是一个回补之前传统服务器投入不够的部分。
但到了下半年甚至2027,agent会开始更广泛的铺开,比如智能导购和客服,已经占到了Amazon去年年底100万CPU采购的相当部分比例,这部分的增长是很快的
前两个逻辑,基本上是今年主流叙事在讲CPU潜力的共识,但是我的感悟是,还有另外两个逻辑被低估了:
3. 造成CPU服务器潜力更大,更长线的主逻辑,可能和agent本身没有直接关系,而是code agent带来的副产物:
coding门槛和速度的大幅优化,让“构建软件 + 连接软件 + 调用软件 + 自动化软件”这整件事便宜了一个数量级,Jevons 悖论在software供给端的展开,最终把世界推向更高的软件密度和 API 密度,这直接带来了CPU传统workload的线性上升
从2025年年底开始,coding agent迎来了质变,Claude code迎来了爆发式增长,三个月的token营收增长了三倍,那么导致的下一步必然是Code量的十倍增长,以及App数量的巨量增长
即便是在大厂,每天1m token消耗只能算是个平均水平,人均coding量必然是翻倍的(小厂就是翻十倍了),code供给量暴增,不会只停留在 repo 里,而会逐步变成更多长期运行的软件资产,长期存活的feature变多,product变多,microservice变多,API变多
长线来看,App/API所有的生产成本和生产周期会变成原来的10%,API实现极大富足。那么API的Usage就会大量的上升,这就会造成传统CPU Workload或者说CPU Seconds大量的上升,这甚至和agentic没有直接关系
时间维度上,这个逻辑并不是短期性质,Claude code的爆炸是这几个月刚发生的事情,那么产品上线,microservice,api上线,可能都要向后延迟。当软件变便宜,社会不会少用软件,只会把更多事情软件化
所以也许到下半年甚至更久才会看到,传统cpu云的需求又莫名其妙增加了,表面上看,甚至和AI agent没有直接关系
4. CPU是一个技术上很难通缩的东西,不像内存/存储有很多压缩算法会降低单任务对存储的用量,CPU workload增长转化成硬件需求增长是实打实的
比如说kvcache其实每年都有各种压缩技术出现,老的压缩技术比如kvcache的multi-head它会share一个head(GQV),这个大概会相当于4倍的压缩,再比如说去年turboquant这个技术也会新带来几倍的压缩。然后加上数据精度从FP16到现在的下一步要到FP4,精度的下降都会带来kvcache的压缩,从而带来存储方面的技术通缩。
但CPU是一个技术层面上通缩量很小的事情,目前任何的agentic的cpu workload(CPU seconds)增长都是硬件需求增长,它通缩的方面只有每年每一代跑分提高的10%到15%。如果说另外通缩因素,比如云的五倍六倍的超卖会不会影响?不会,因为它一直是超卖的,所以说超卖/利用率低这个CPU技术通缩的因素不会继续扩大了,每个增长的CPU seconds都是不怎么带打折的硬件线性增长
ARM的指引是CPU的供需缺口可能会到30%以上,这几个原因的叠加,加上AI服务器对CPU服务器产能和订单的挤压,可能会让缺口更大,各个hyperscaler的反应可能是会滞后的
------------------
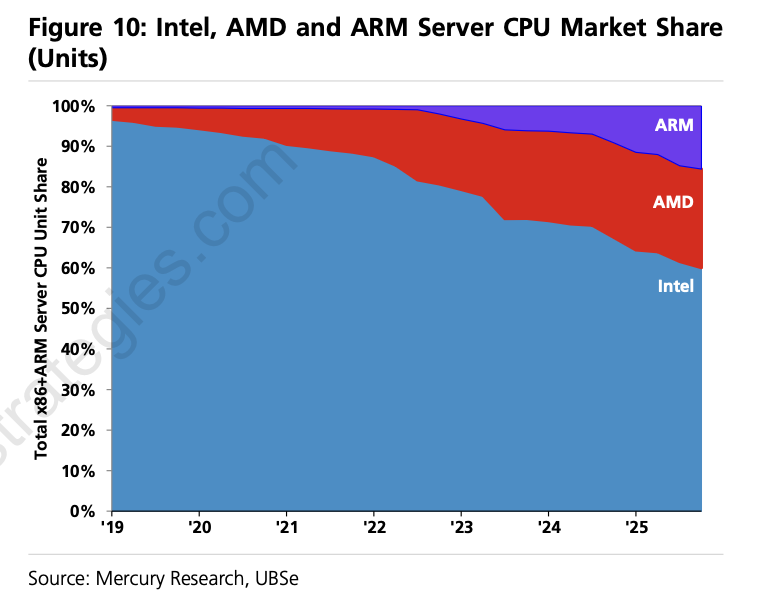
CPU整体需求潜力增长的同时,ARM服务器CPU也赶上了历史上最好的时代:
Hyperscaler为了节省成本,接近50%的新增传统server CPU都是ARM,Google的Axion,Amazon的Graviton,Microsoft的Cobolt,Graviton甚至2026年的产能已经全部卖完,瓶颈成了产能
Google TPU配Axion,Amazon Tranium配Graviton,Nvidia Rubin配自家Vera CPU,这部分CPU为什么会集体转向ARM,除了成本因素之外,也因为推理系统为了追求token throughput,batch越来越高越做越复杂,自研ARM CPU以及系统性软件硬件的co-design会更方便,比如Nvidia是Dynamo去控制Vera和Rubin之间的协同
Nuvacore的规划上来看,不仅仅满足于做IP,也要做成品,因为在招聘网站上出现了validation engineer的职位
但是这次Nuvacore面临的挑战也不小:起步太晚了,无论是市场上,还是技术上,竞争都激烈了很多。CPU服务器和七年前比,已经复杂了很多,已经不再是单片CPU的竞争,而是rack系统级别的复杂度
现在开始做2028~2029年上市的CPU,要做到rack级别有竞争力,规模要大很多,基本上要几十个chiplet,500+个core拼起来,还要考虑如何适配AI agentic workload,工作量比以前明显要大的多,对一个startup的挑战比七年前也大得多
----------------
上次Nuvia在成立两年之后成功的以14亿美元出售,这次市场热度比五年前高了一个数量级,Nuvacore之后的路会怎么走呢?
如果是被收购路线,其实买家可能比五年前比并没有更多,这五年里,Google有了Axion,微软有了Cobalt,Amazon有了Graviton,Nvidia自研的Vera CPU已经成型,连ARM也打破了35年来只做IP的常规,开始做自己的AGI CPU芯片
最有可能的是Softbank系,softbank已经在ARM CPU服务器生态上布局深耕了多年,65亿美元收购了Ampere,再收购Nuvacore是很正常的事情,这个市场想象力足够大
其他的选择也可能是Meta,因为几家互联网公司里,只有Meta的silicon house没有稳定可靠的CPU服务器,有限的资源在MTIA都做AI加速器去了
但是Meta的问题在于稳定性极低,决策每个月都在变化,注意力非常短期化,项目随时取消,对Nuvacore来说完全无法兑现潜力,是一个非常糟糕的买家
但总体来说,Nuvacore的选择肯定比五年前宽了太多了,对ARM CPU服务器的潜力大家的共识都很明确,融资的难度要小很多,自己运营扩张起来,阻力比以前小很多,合作伙伴的配合程度上也因为未来预期,会容易很多
完全可以自己做大到比Nuvia当年更大的规模再考虑出路,根本不着急卖



中文
GTC 2026 preview: 从Groq生态位看AI异构推理(Heterogeneous Inference)新时代
Groq的SRAM路线的生态位在哪里?SRAM会不会替代HBM路线?
Nvidia如何整合groq到现有的产品线?是技术整合还是产品线整合?收购之后会给groq LPU产品带来怎样的升级?
这里尝试从基本原理出发去拼凑一个逻辑链
—--------------------------------------------
先从first principal说说groq的设计哲学开始:groq本质上是一个compiler first走到极致的路线而不是SRAM first路线,SRAM路线只是副产品
相对于CPU针对通用workload的设计不同,AI 推理workload的特征在于确定性(deterministic)更高,基本没有data-dependent branching,tensor shape固定,memory access pattern确定
当Groq带着这个新特征重新审视 hardware-software interface,去问"什么应该在编译时做,什么应该在运行时做"。对于 AI 推理这个 workload,答案是:几乎一切都可以在编译时做
这就是Groq最疯狂而独特的地方:完全确定性编译器(fully deterministic compiler),compile精确到每个时钟周期,完全精确带来极致的效率。在编译的时候就需要考虑到硬件在运行的每个时刻的所有状态,扮演一个全知全能的上帝,就可以避免硬件资源的浪费,而要做到这一点,必须要做到极致的确定性,也就是说,LPU里每一个计算,访问存储,通信的延迟,都需要精确到clock cycle,这对compiler来说是非常复杂的
AI workload更高的确定性,以及groq的完全确定性编译器优先路线很自然的避免了VLIW的弱点(内存行为以及branch行为不可预测),放大了VLIW的优点。那么下一步要提高效率和并行度,VLIW 式的编码格式就是一个自然推论—既然编译器要控制每个功能单元每个 cycle 做什么,那指令格式当然就是一个宽指令里打包多个 指令会得到更高效率,这就是 VLIW
在groq的芯片里,不做乱序执行/speculation,大幅简化硬件(instruction dispatch仅占<3%面积),把复杂度移到静态compiler上,这正是VLIW思想的精髓
既然要让编译器做确定性的 cycle-accurate 调度,那么硬件里所有不确定的因素都要消除,比如arbiter,crossbar, replay,这些有自主算法在运行时决策的部分都砍掉
memory latency 也必须是确定的,所以一切 cache 和 DRAM都是要砍掉的,cache也要换成scratchpad SRAM,因为cache replacement 策略是runtime决策的,不确定,必须换成软件控制的scratchpad,地址映射完全由compiler控制,保证确定性
通信也必须精确到cycle,发送和接收指令就是软件协调好执行的时刻,并没有传统的“我要发一个包给你,请分配好内存”这类操作,而是同步地根据一份时间表严格执行SRAM 的分配和收发操作,这个时间表是compiler已经决定好的,硬件只需要执行就行了
完全确定性compiler也带来了芯片节点之间互联通信overhead的极低延迟,这可能是groq确定性架构最被忽视的最大优势,毕竟传统互联架构里Packet Routing、Arbiter Contention 和 Buffer Queuing,这些是延迟波动的重灾区
这就是为什么说,groq其实并不是一个native SRAM first的技术路线,也不完全算是VLIW first的技术路线,而是compiler first的技术路线,更准确的说,完全确定性compiler是整个groq架构的核心
只是因为确定性compiler的原因,所以在核心decode阶段无法使用HBM/DRAM带来的不确定性,SRAM only成为了必然的选择。这也是为什么说Groq更像是compiler first路线。
—--------------------------------------------
groq被收购之后最直觉的第一反应:
groq确定性compiler技术路线有没有可能用在Nvidia现在的GPU+HBM体系上?
不能
原因有两个:
1. HBM/DRAM的物理特性和带宽优化决定了它天生带有不可预测的延迟,无法和deterministic compiler兼容
2. Nvidia的SIMT路线和Groq的VLIW/compiler first的哲学本质是有冲突的
DRAM为什么充满了不确定性
1.refresh操作每隔一段时间tREFI就会刷新一次cell上的电量,阻断bank访问,这是由DRAM cell物理特性决定的。而这个操作会随着温度的变化,refresh的频率也会变化
2. 为了最大化利用DRAM带宽,controller会做很多优化,最典型的是batch scheduling:把同一个page的traffic都放在一起减少page miss,同时让读写尽可能接触更多的bank,以及尽可能减少read和write switching
这些动态优化都是real time发生的,基本不具备可预测性
3. system上对DRAM的优化,比如bank address hashing,让compiler静态提前定位某段data难度太大,落实cycle确定性的复杂度太高
其实这些不确定性也是能解决的,代价就是放弃大部分的优化策略,大幅降低DRAM的efficiency和利用率。groq自己其实也对这方面做过探索,他们曾经做过一个确定性DRAM的专利,但工程上的实现是不现实的,这也是groq选择SRAM-only的核心原因之一。
所以确定性compiler技术路线用在DRAM上不是一个yes or no的问题,而是这不是一个好的选择,因为这意味着HBM的efficiency和BW都要大打折扣,而且是结构性无法避免的损失。
这几乎意味着要用compiler去重写一个完整的memory controller,因为确定性dram本质上是compiler software defined memory controller,这个SW controller会非常难做,复杂度极高,而且每一代memory迭代都要大幅更新compiler里的结构,在工程资源上是不现实的。而且每一代DRAM,每一家DRAM 供货商都需要调试 ,这在验证和validation上是一个nightmare
---------
为什么Nvidia的SIMT路线和Groq的VLIW/compiler first的哲学本质是有冲突的
这两套体系对同一个问题给出了相反的回答:运行时的不确定性,Groq是compiler阶段直接消灭所有不确定性,Nvidia选择了用warp switching去隐藏不可预测的延迟
Nvidia GPU 建立在 SIMT(单指令多线程)和硬件层线程调度器(Warp Scheduler)上。当一个warp因为访存而stall的时候,硬件warp scheduler立刻切换到另一个ready的warp继续执行,把stall的延迟藏在其他warp的计算里。这整套机制的前提恰恰是:延迟是不可预测的,所以需要足够多的并发线程来统计性地填满pipeline
如果要用确定性的编译器去接管,等于把 Nvidia GPU 里面最核心的硬件调度单元全盘废弃:如果你不需要多warp轮转,你也不需要那么大的register file
实际在历史上,AMD从TeraScale(VLIW)到GCN(scalar SIMT)的架构转型,正是GPU领域一次大规模的VLIW→SIMT迁移:当workload变得不够可预测时,VLIW的compiler负担太重,应该把调度权还给硬件
所以在原架构上引入确定性compiler应用到Nvidia现有的技术路线,是很难融合。这不是compiler能不能改的问题,是两套架构从第一性原理上就走了相反的方向。
所以说,Groq在Nvidia的唯一出路,就是独立的面向low latency decode的专用产品。
—--------------------------------------------
Nvidia收购Groq之后,就引出了第二个问题:
Nvidia会给Groq带来什么样的新提升?
那么首先看看groq的瓶颈在哪里,简单的说
1. SRAM容量太小,无法容下大模型的参数量+kv cache
2. 推理decode主要瓶颈不在SRAM 80T/s的速度而在于interconnect延迟(占80%)
3. 对于Prefill这样的compute bound task速度较慢
groq的主要架构基本上是17~18年就完成了,那是CNN的时代,架构也是以CNN/LSTM为主要的target,当时测试benchmark都是ResNet50,SRAM容量是绰绰有余的
但是进入LLM时代,单个TSP计算卡230MB SRAM就显得不够看了,一个LLAMA 70B模型的参数量占内存就相当于3000个ResNet50,再加上因为上下文long context日益膨胀的KV cache,scale out就成了唯一的出路
于是一个70B模型的推理就需要576卡的集群,采用16个Pipeline并行 (PP)和36个tensor 并行 (TP),80层的大模型切成16级流水pipeline串行,每级横向5层MLP分给36个卡并行推理
16级流水pipeline串行(PP),每级流水到下级流水的通信overhead延迟就要 X16。实测中PP和TP之间的通信延迟占据了80%以上的总延迟,特别是PP延迟,占据了50%以上的总延迟,通信延迟成为了主要瓶颈
Groq计算卡对decode阶段的memory bound很友好,但是片上巨大的SRAM也挤压了compute的面积,导致prefill阶段耗时很高。融入Nvidia产品线之后,Groq产品完全可以扬长避短,只做自己擅长的decode部分,避免prefill阶段的短板
Nvidia带来的最重要的提升,可能是通过工艺的提升,以及hybrid bonding技术(类似AMD 3D V-Cache),扩大Groq LPU SRAM的容量,比如光是14nm到3nm的工艺提升,SRAM就能从230MB扩大到500MB,如果以后引入3D SRAM,容量还能翻倍
SRAM变大之后,原来576个LPU能完成的70B模型推理,现在只需要256个LPU了。猜测也许可以用32个tensor并行 X 8 个流水pipeline串行,pipeline interconnect延迟能直接减半。
所以Nvidia能带来的主要提升可能是,通过扩大SRAM的容量,减少scale out卡数,从而减少通信延迟时间,提高token速度
—--------------------------------------------
Groq的SRAM路线专用产品进入Nvidia产品线,引出了第三个问题:
SRAM路线会颠覆HBM路线吗?
不会。
SRAM路线本质上是用十倍的成本换几倍的速度,只能适用于一部分愿意为低延迟付出高额溢价的市场。AI硬件市场的主旋律仍然是比拼TCO(total cost ownership)成本
做一个简单的成本核算就清楚了
以LLAMA 70B模型为例,算上KV cache,Groq需要576张计算卡组成集群。Groq计算卡零售价大约是每颗2万美元(groq CEO说实际售价远低于,那就按2000美元算),576卡就是超过110万美元的硬件成本。而2张H100就能跑同样的模型,成本不到10万美元。成本差距是一个数量级。
Groq于是转而卖token服务,Groq的API定价确实便宜,但这是因为两个原因叠加:
第一,Nvidia的GPU云服务商通常在硬件成本上加倍的margin卖出去;
第二,Groq自己是在亏钱运营的。2025年全年,Groq用LPU做大模型推理、对外卖API的业务,营收大约4000万美元,成本却是6000万美元,毛利-50%。Groq的便宜token价格不是因为SRAM的经济性更好,而是因为VC在补贴。
那么有人愿意为速度付溢价吗? 有。
Claude Opus 4.6 Fast模式就是一个很好的市场信号:输出速度提升2.5倍,定价直接从$5/$25涨到$30/$150 per million tokens,6倍的价格,估计是牺牲了batch带来的速度提升。
所以这部分市场是真实存在的,SRAM路线在这里有它的生态位。
但这个生态位有多大?要看ML workload的分类。不同的workload对硬件的侧重点要求差距巨大:
推理的Prefill阶段对带宽要求低但算力要求高,推理decode阶段则是反过来。R&R(Ranking & Recommendation)对算力和带宽要求都不高但对存储的容量要求巨高
(见附图)
对延迟敏感的推理workload,decode阶段对Memory bandwidth要求高,是SRAM路线的优势领域(图中红色线),主要是real time/interactive LLM:chat、copilot、agent这类需要实时响应的场景。
特别是reasoning model,SRAM路线带来的极致体验是很夸张的:H100要两三分钟跑完一reasoning,cerebras十秒就搞定了
这部分注重极致推理速度的市场有多大,我暂时没有找到一个详尽的调研,看到一个Hyperscaler的说法目前是10%左右
但是agentic flow workload,常用的agentic框架做profiling,比如SWE-Agent, LangChain, Toolformer,CPU最长可以占到90%的E2E端到端延迟,throughput瓶颈也更多的卡在CPU, 这些加起来通常远大于单次decode的延迟,SRAM路线速度优势被削弱。
而更大体量的workload:batch inference、offline processing、ranking、recommendation对延迟没有那么敏感,throughput和cost per token才是唯一的指标。这部分市场SRAM路线完全没有成本上的竞争力
H100/B200相当于大巴车,装的人多(batch processing),每个人的车票钱很便宜,但是慢悠悠。 Groq/cerebras相当于是法拉利,极致的速度体验,但是装的人少,人均票价是大巴车十倍甚至以上。
长期来看,SRAM的成本劣势是结构性的,不会随时间收敛。6T SRAM cell天然比1T1C DRAM cell贵,这是物理决定的,和工艺无关。而且SRAM scaling已经慢了下来,从N5到N3E,SRAM单元面积几乎没有缩小
即便是速度优势,SRAM路线的缺陷在于访问速度已经接近工艺极限,很难跨代提升。特别是HBM的速度每代都在指数上升的情况下,SRAM 80T/s的速度优势很难长久维持。十年前这个路线刚刚兴起的时候,SRAM速度比HBM快了两个数量级简直是降维打击,但现在的速度差已经不到一个数量级(Rubin HBM4 22TB/s),再过十年,两者的速度可能拉不开差距了。
所以结论很清楚:SRAM不会颠覆HBM,但它在低延迟、低batch、实时推理这个细分市场里有不可替代的价值。但长远来看,随着HBM速度指数上升的背景下,SRAM优势也会逐渐慢慢越小。
—--------------------------------------------
写到这里,也许我们可以把这些碎片拼凑出Nvidia收购Groq之后计划的下一步雏形: 异构推理的新时代开启了
以后的推理workload本身已经分化,无法再用单一架构的最优点覆盖,体系结构最重要的是tradeoff,是尺度范围。一个架构形态在合理的tradeoff以及特定workload下可能惊为天人,用多个架构形态去迎合不同种类的workload,就是异构计算的思想
2026 GTC的最大主题,就是异构推理的系统化。推理不会由单一硬件统一完成,而会被拆成 几个部分:
控制和调度/agent runtime层交给Vera CPU
针对long context的prefill交给CPX (Content Phase aXcelerator,一个专门为prefill的compute bound特性设计的计算模块)
小模型/低延迟/low batch decode交给SRAM路线的Groq LPU,256块LPU集群
高吞吐/高并发batch decode,HBM GPU仍然是主力
以及可能会被忽略的ICMS:inference context memory storage, kv cache已经是核心基础设施,以前的异构更多是计算异构,现在的异构已然延申到了缓存异构memory hierachy heterogenity(似乎改名成了CMX: context memory storage)
LPU和GPU的分工,更可能成为 inference stack 里两个不同的tier,小模型/低延迟/low batch都交给LPU,长context/high batch交给HBM GPU
目前CPX什么方式和LPU/GPU连接还尚不清楚,整个工作流程大概是,CPU做控制和调度,CPX Prefill 跑完得到几十 GB 的 KV Cache, 分配到 Groq LPU阵列SRAM,或者分配到HBM GPU,开启Decode流程
其实还有一种更大胆的猜想:如果引入speculative decoding,那么LPU完全可以跑通常尺寸较小的草稿模型,在LPU上速度极快,HBM GPU作为主力去验证草稿模型即可,这样的异构推理结构,可以让token rate大大加速,在某些场景下翻倍也是没问题的(比如代码任务模式固定,小模型很容易猜对语法,所以加速效果很好)
当 Nvidia 的眼光越过GPU,走向整个 Agentic 流程的系统级优化时,追赶它的难度已经不在一个单一维度了。以前 Nvidia 步子迈得大,靠的是 GPU 架构和参数的单点暴力跃升;而现在,随着CPX,LPU,ICMS加入异构推理,它是从“数据中心即一台计算系统”的系统视角出发,从Agentic flow的角度做底层的异构编排。
无论是系统的复杂度,还是软件栈的工作量(Dynamo/ICMS/CMX),Nvidia 迈出的这一大步,直接把竞争门槛从“做出一颗好芯片”拉高到了“定义一整套异构系统来做普适加速计算解决方案“
—-------------------------------------------------------
不由得感慨,每一次计算范式的改变,半导体都会带来一波新的startup热潮,但当软件/应用形态逐渐收敛,最后还是变成了大厂通过收购把功能做大做全,参数做的更高,系统深度整合的更好更全面,成本更低,功耗和跑分更优秀,让startup慢慢失去独立生存的空间
比如移动互联网时代早期,也是群雄并起,有做AP应用处理器,独立基带芯片的,ISP的,GPU的各种小公司。但最后的赢家,都是从到后来把GPU,ISP,modem全都做进SoC,并且完成系统级整合的异构计算平台。
苹果收购PA semi的CPU,英飞凌的modem,掏空Imagination的GPU;高通收购ATI的mGPU,Atheros的Wifi,Nuvia的CPU,CSR的蓝牙/DSP,都是典型例子
异构推理的复杂度越来越高,能做系统级整合的公司会更有优势,这和移动SoC时代的逻辑一模一样。AI时代nvidia收购arm(失败),收购Mellanox,收购groq,只是这个新历史轮回的开始

中文


一夜盈利超150W!马上沪油开盘将全部跌停!
今天还没来得及加仓就跌下来了,如果2000W仓位开满,盈利超300W!
我不喜欢长篇大论的分析,
因为我是交易员,而不是分析师,不是新闻解读员,更不是KOL搞流量。
但总有韭菜觉得,不分析,是我菜,
他们喜欢看那些长篇大论的废话,觉得字越多,越牛逼。
我直接开仓,字少,是跳大神,是赌,是瞎玩。
殊不知,我说的,我做的,才是交易的本质。
很多人都亏完了,都还没明白,
交易最重要的是敢开仓,而不是分析。
分析来分析去,哪个观点是自己的?
你真有自己的想法吗?
你有个几把想法,还不是网上到处看来的一些垃圾自媒体观点?
说不定对方就是卢克文这样的中专生。
一堆中专生生产的垃圾自己吃的津津有味,消化之后还跑到网上到处拉给别人吃。
那么喜欢分析,你也去做KOL搞流量接广告就好了啊,自己做个几把交易呢。
你连做自媒体都没脑子,还不如中专生卢克文呢,哪来的“自己”的观点。
交易很简单,多空就两个方向,各50%,直接选一个方向开仓就行了,有什么好分析的?
托尼老师交易之路的成功,就在于:
不会分析,只会开仓!
不会分析,只会开仓!
不会分析,只会开仓!
Shut up! Show me your position.
中文

历经数月,费了不少功夫跑出来的行情分析软件,今天已经完成度80%
重要的是GPT金牌认证过,现在开放测试版,快来给这个软件做数据小白鼠吧
后面会不断优化,争取成为T1级别的行情分析工具
Ps:为了节省数据调用成本和云成本,每个人是有使用次数限制的
测试群:t.me/+JmfqYx1_dKwwM…
限时关闭



中文

We present HIL-SERL, a reinforcement learning framework for training general-purpose vision-based robotic manipulation policies directly in the real-world. It effectively addresses a wide range of challenging manipulation tasks: dynamic manipulation, dual-arm coordination, contact-rich/flexible object manipulation. It achieves a success rate of 100% across all tasks within just 1 to 2.5 hours of training.
English

🎓 Excited to defend my PhD thesis “Learning Universal Humanoid Control” at CMU this Friday!
From scalable motion imitators to visual dexterous whole-body policies — it’s been a wild ride 🤖✨
📅 April 25, 2025
📍 CMU RI & online
🔗 cs.cmu.edu/calendar/18255…
English

目前中国经济遇到的是四个“见顶”
投资见顶,房地产完了,地方政府的财政完了;
消费见顶,通缩环境持续超过2年了,消费不断新低,存款新高;
外贸见顶,外贸不能只看顺差,要看出口企业的生存环境;
人口见顶,结婚对数2024年创45年新低,25年大概率继续新低。
而中国政府债务和财政赤字则远未见顶。日本债务出清后,政府债务基本上已经见顶了。
中国的非理性繁荣远未出清,政府阻止房地产下跌,同时吹起了另一个大泡沫,制造业产能严重过剩。
基于以上“四个见顶”,中国经济已经遇到刘易斯第二拐点。
刘易斯第一拐点是人口红利衰减开始。
刘易斯第二拐点是人口红利完全关闭。
有人说,中国每年超千万大学生毕业,人口红利并未关闭,这说错了,中国在产业升级过程中,由于过度依赖(补贴)制造业,忽视服务业,再加上房地产崩盘,导致结构性失业严重,大学生失业率超过50%,且忽视民生,内需消费自然无法拉动。
青年失业率高企的直接后果就是打击95-00后的婚育意愿,导致深度老龄化提前到来,超级老龄化+失业潮,让中国更没有时间整体上完成产业升级和消费升级。
2018年美国彻底的战略转变,以及此后的三年疫情处理不当,中国已确定无法跨越刘易斯第二拐点,也就是在2030年代末期,深度老龄化到来之前,成为发达经济体,即中国将跌入中等收入陷阱。
中文


Introducing OFT—an Optimized Fine-Tuning recipe for VLAs!
Fine-tuning OpenVLA w/ OFT, we see:
-25-50x faster inference ⚡️
-SOTA 97.1% avg SR in LIBERO 💪
-high-freq control w/ 7B model on real bimanual robot
-outperforms π₀, RDT-1B, DiT Policy, MDT, Diffusion Policy, ACT
🧵👇
English

NaVILA: Legged Robot Vision-Language-Action Model for Navigation
website: navila-bot.github.io
abs: arxiv.org/abs/2412.04453

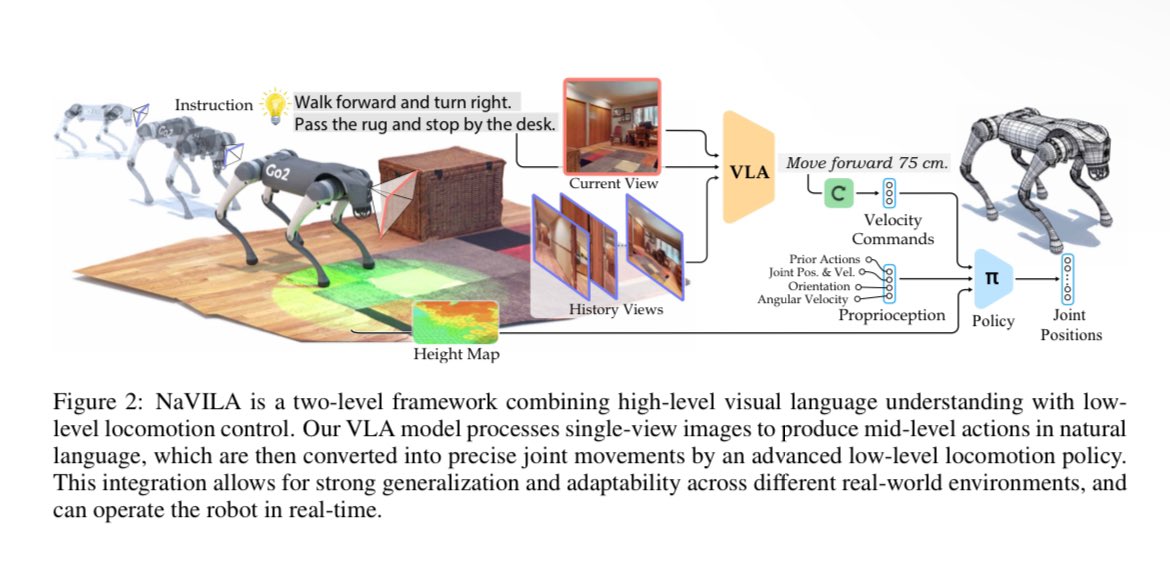

Yandong Ji@JiYandong
Without any maps and prior knowledge of the scene, our humanoid and quadruped can now navigate with human language instructions to anywhere outdoors and in any house we go!🔥🔥🔥 Introducing NaVILA, a 2-level navigation foundation model (mid-level action VLA + locomotion skills) leveraging massive offline datasets, e.g., not only sim envs, but also human touring videos. A thread 1/N
English