Sabitlenmiş Tweet
Spok
1.2K posts




@ivanfioravanti yes the max reasoning setting, in most cases, it doesn’t think for long unless the task is complex, so it adapts by itself
i saw it can think for 3 min or so (very rarely), but it you have 3 agents in parallel then it's fine
English

For the Claude Code warriors out there, what is the right effort level to be used? 🤔
English

@spok_vulkan same experience building a local desktop agent. aggressive quantization kills tool-calling way before it hurts chat quality. smaller model + higher precision wins every time for agent work.
English
@LeanKinPrazli And the funny part is, in most cases, you will not see the errors directly the result itself will just be worse overall, you can really notice only in a direct comparison or benchmarks
English
@LeanKinPrazli If we talk about MLX, any 4-bit quants seem to be very bad at tool calling compared to the FP16 baseline, like 2x worse, witch is a significant drop in performance.
So I would rather use Qwen3.5-4B at 8-bit than Qwen3.5-9B at 4-bit for such a task.
English
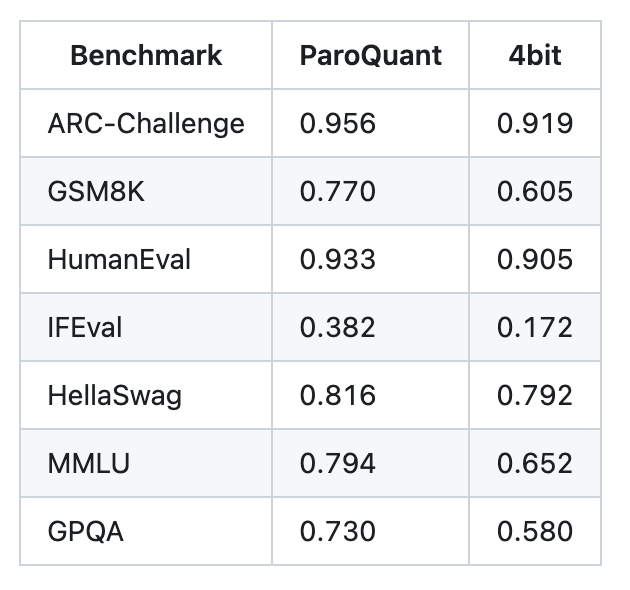
@ivanfioravanti Your IFEval column is the most interesting one here though.
ParoQuant: 0.382. Standard 4bit: 0.172. FP16 baseline? 0.915.
I hit this exact problem building an on-device agent. Ran a 14-scenario tool-calling benchmark on Qwen3.5-9B PARO vs 4B 8-bit.
x.com/spok_vulkan/st…
Spok@spok_vulkan
I just ran into something wild building a local AI agent. Qwen3.5-9B at INT4 (ParoQuant) performs WORSE than Qwen3.5-4B at 8-bit on tool-calling benchmarks. More parameters. Worse results. Here's what we found.
English
MLX 4bit vs MLX ParoQuant 4bit using Qwen3.5-9B 📣
As you can see below there is no match.
I will try to do same with 8bit in next days to do a comparison.
ParoQuant is my new go to quantization below 8bit!
I have limited max-tokens in some cases, but the important thing is that same limits have been applied to both quantizations.
English
Spok retweetledi

