
As an aside, this work continues a direction that I've been recently focused on: understanding and improving post-training/inference of LLMs. More to come soon!
English
Stanley Wei
25 posts
@stanleyrwei
PhD student @Princeton. Theoretical foundations of machine learning and LLMs. Previously CS + Math @UTAustin.
📰 RL for LMs often relies on imperfect proxy rewards, which can lead to reward hacking. But are incorrect rewards necessarily harmful? Turns out, they can also be benign or even beneficial! This has implications for reward model evaluation and verifiable reward design. 🧵

The modern world still baffles me. I'm told I should celebrate that my YouTube "channel" (if you can call it that; just 80 min live lectures of undergrad/grad level math courses) has crossed 1M views. Who is watching this stuff?! I suppose I myself get an awful lot out of being able to watch all kinds of instructional materials on there by others. So it's nice to see that some people apparently find these lectures somewhat useful... (Or maybe they fell asleep watching Veritasium late at night, and the algorithm auto-loaded one of mine?..😂)

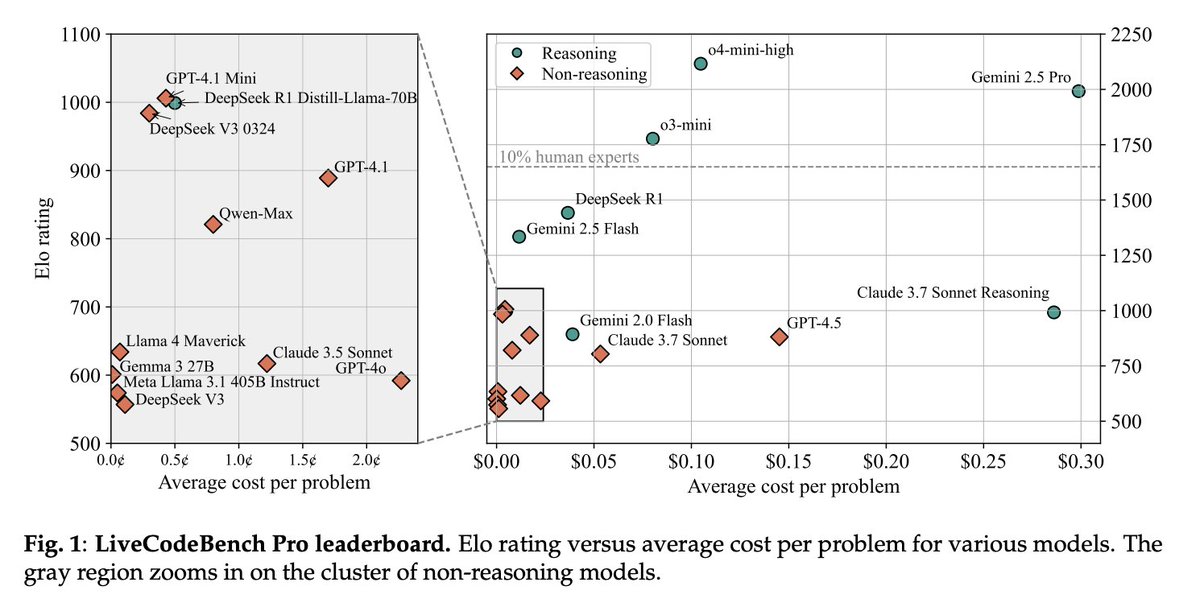
We introduce LiveCodeBench Pro. Models like o3-high, o4-mini, and Gemini 2.5 Pro score 0% on hard competitive programming problems.


New unlearning work at #ICLR2025! We give guarantees for unlearning a simple class of language models (topic models), and we further show it's easier to unlearn pretraining data during fine-tuning, without even modifying the base model. Paper: arxiv.org/abs/2411.12600 🧵:
The success of RLHF depends heavily on the quality of the reward model (RM), but how should we measure this quality? 📰 We study what makes a good RM from an optimization perspective. Among other results, we formalize why more accurate RMs are not necessarily better teachers! 🧵

