Dingli Yu retweetledi

Meta is back! Muse Spark scores 52 on the Artificial Analysis Intelligence Index, behind only Gemini 3.1 Pro, GPT-5.4, and Claude Opus 4.6. Muse Spark is the first new release since Llama 4 in April 2025 and also Meta's first release that is not open weights
Muse Spark is a new model from @Meta evaluated on Artificial Analysis. We were given early access by Meta to independently benchmark the model. It is the first frontier-class model from Meta since Llama 4 Maverick was released in April 2025, and notably the first @AIatMeta model that is not being released as open weights. The release follows Meta's reorganization of its AI efforts under Meta Superintelligence Labs, and signals that Meta is re-entering the frontier race after roughly a year of relative quiet.
For context, Llama 4 Maverick and Scout scored 18 and 13 respectively on the Artificial Analysis Intelligence Index as non-reasoning models at the time of their release, while Muse Spark scores 52. Muse Spark essentially closes the gap between to the frontier in a single release.
The model is not open source and is not yet accessible via an API but Meta has shared they expect this to come soon. Meta is also integrating Muse Spark into their first party products including their Meta AI chat product, Facebook, Instagram and Threads.
Key takeaways from our benchmarks:
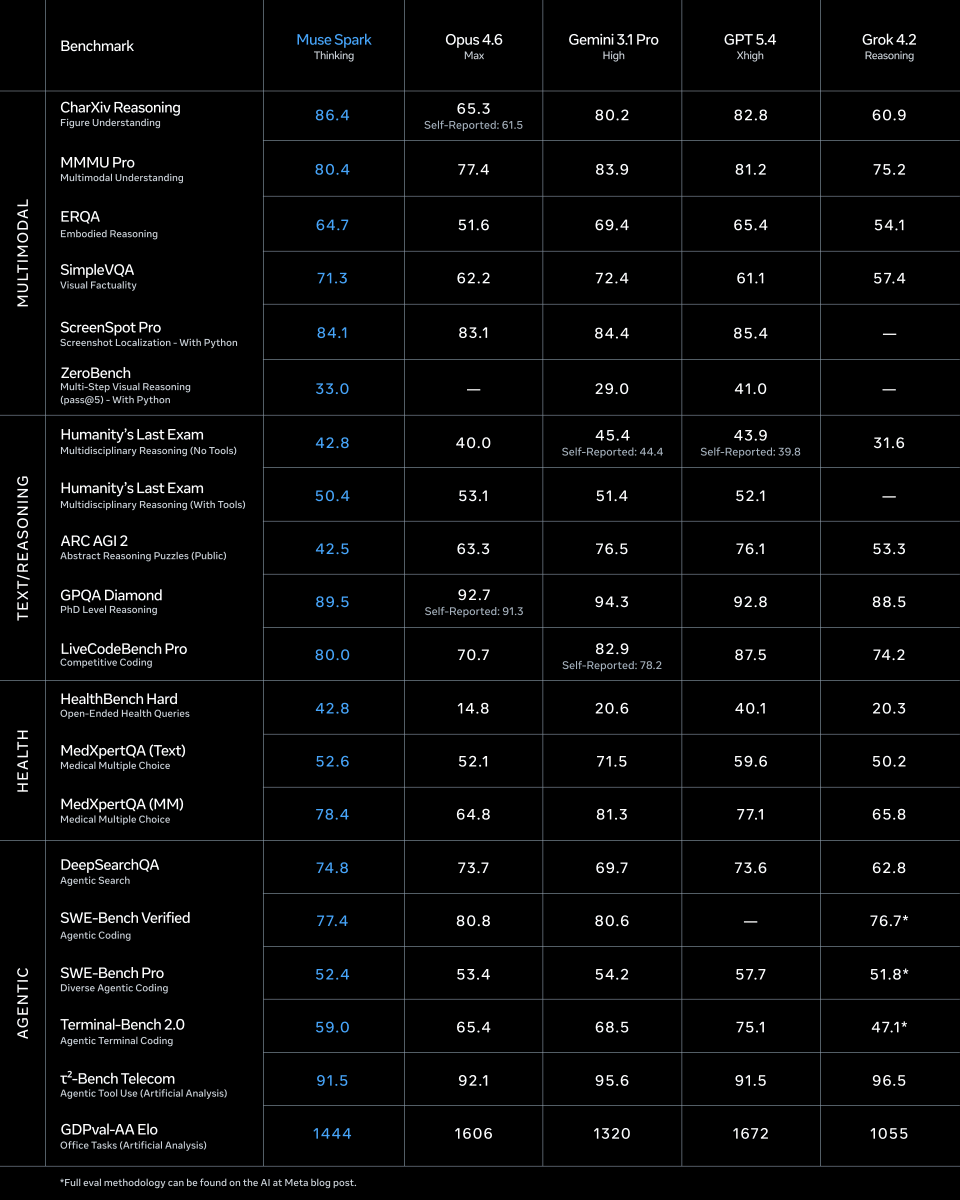
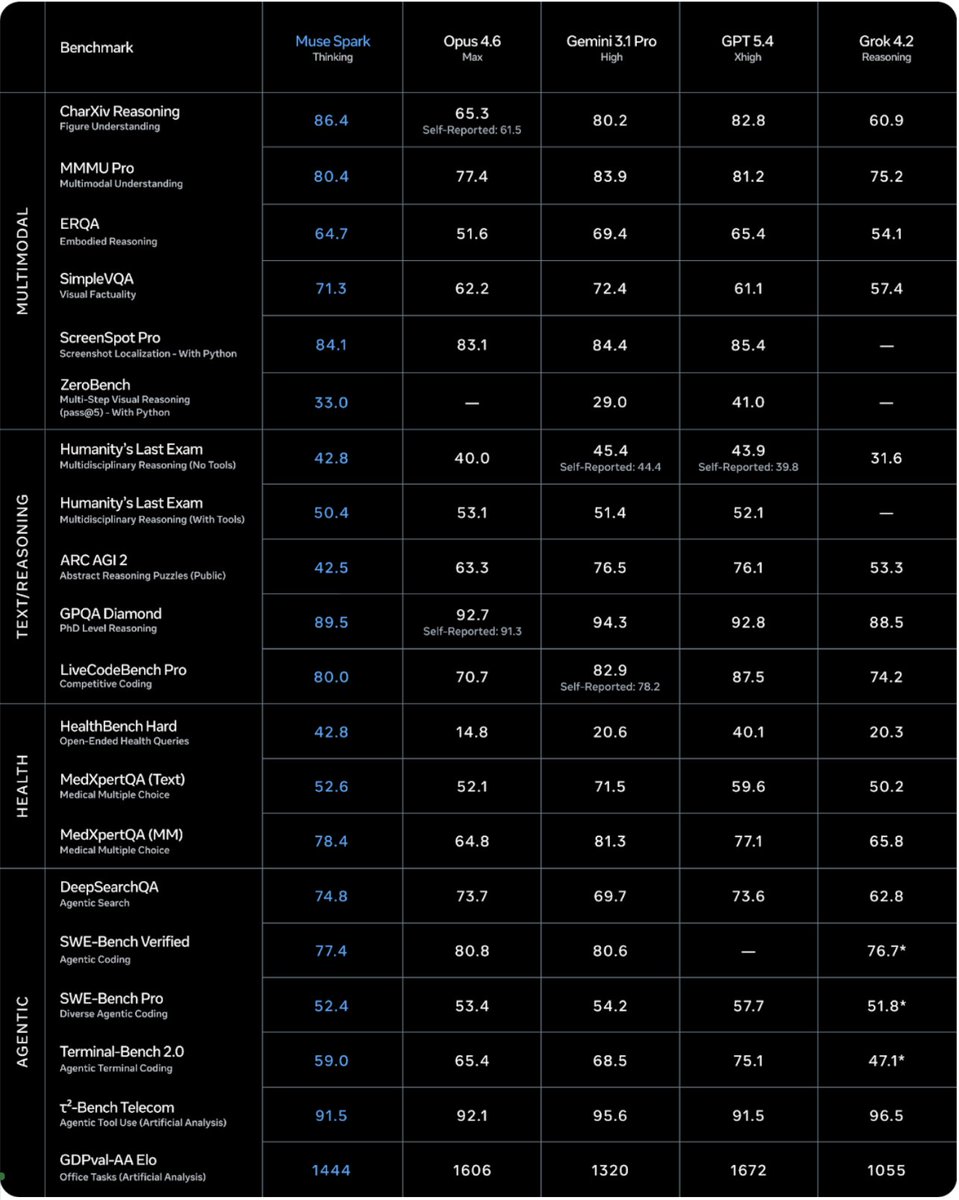
➤ Muse Spark scores 52 on the Artificial Analysis Intelligence Index, placing it within the top 5 models we have benchmarked. It sits ahead of Claude Sonnet 4.6, GLM-5.1, MiniMax-M2.7, Grok 4.20 and behind Gemini 3.1 Pro Preview, GPT-5.4 and Claude Opus 4.6
➤ Muse Spark is notably token efficient for its intelligence level. It used 58M output tokens to run the Intelligence Index, comparable to Gemini 3.1 Pro Preview (57M) and notably lower than Claude Opus 4.6 (Adaptive Reasoning, max effort, 157M), GPT-5.4 (xhigh, 120M) and GLM-5 (110M)
➤ Muse Spark is the second-most capable vision model we have benchmarked. It scores 80.5% on MMMU-Pro, behind only Gemini 3.1 Pro Preview (82.4%)
➤ Muse Spark performs strongly on reasoning and instruction-following evaluations. It scores 39.9% on HLE, trailing only Gemini 3.1 Pro Preview (44.7%) and GPT-5.4 (xhigh, 41.6%). The model also achieved 5th highest in CritPT with a score of 11%, an eval that is focused on difficult physics research questions. This is substantially above above Gemini 3 Flash (9%) and Claude 4.6 Sonnet (3%)
➤ Agentic performance does not stand out. On GDPval-AA, our evalaution focused on real world work tasks, Muse Spark scores 1427, behind both Claude Sonnet 4.6 at 1648 and GPT-5.4 at 1676, but ahead of Gemini 3.1 Pro Preview at 1320. On On TerminalBench Hard, Muse Spark trails Claude Sonnet 4.6, GPT-5.4, and Gemini 3.1 Pro. Muse Spark joins others in achieving a high τ²-Bench Telecom score of 92%
Key model details:
➤ Modalities: Multimodal including text and vision input, text output
➤ License: Proprietary, Meta's first frontier model not released as open weights
➤ Availability: No public API at the time of publishing. Meta expects to provide API access soon. Meta has started integration into their first party AI offering Meta AI and inside Facebook, Instagram, and Threads

English