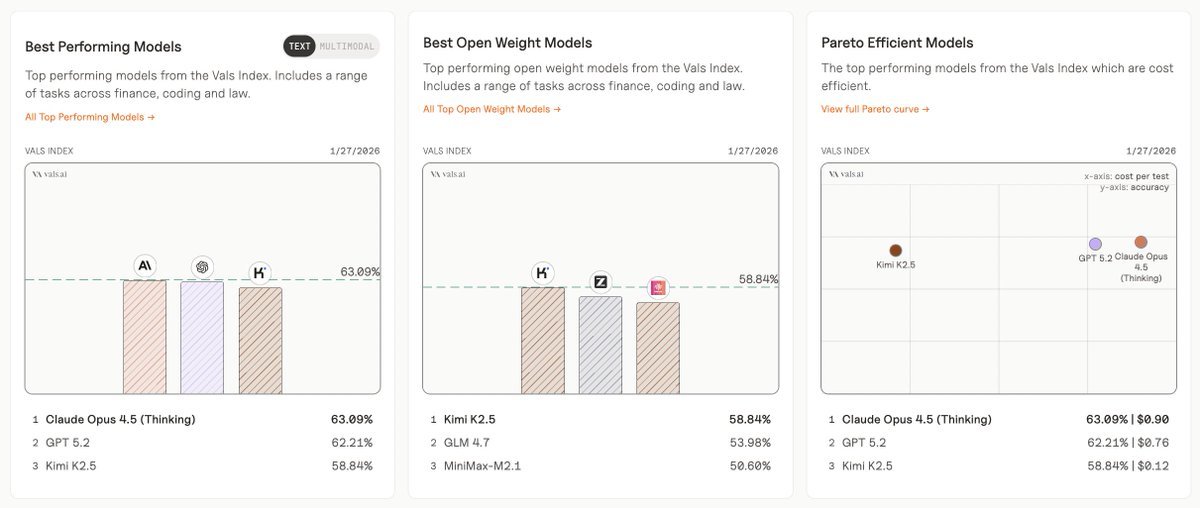
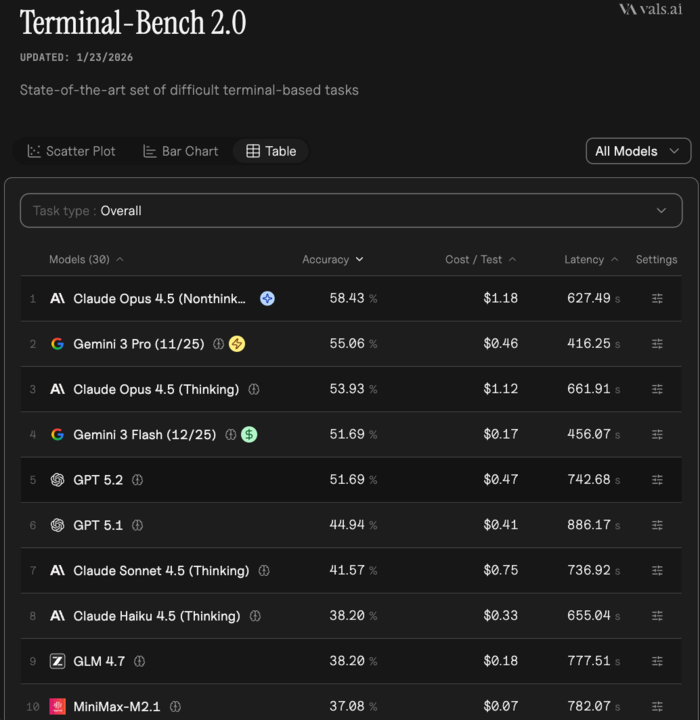
Katrina Drozdov (Evtimova) retweetledi

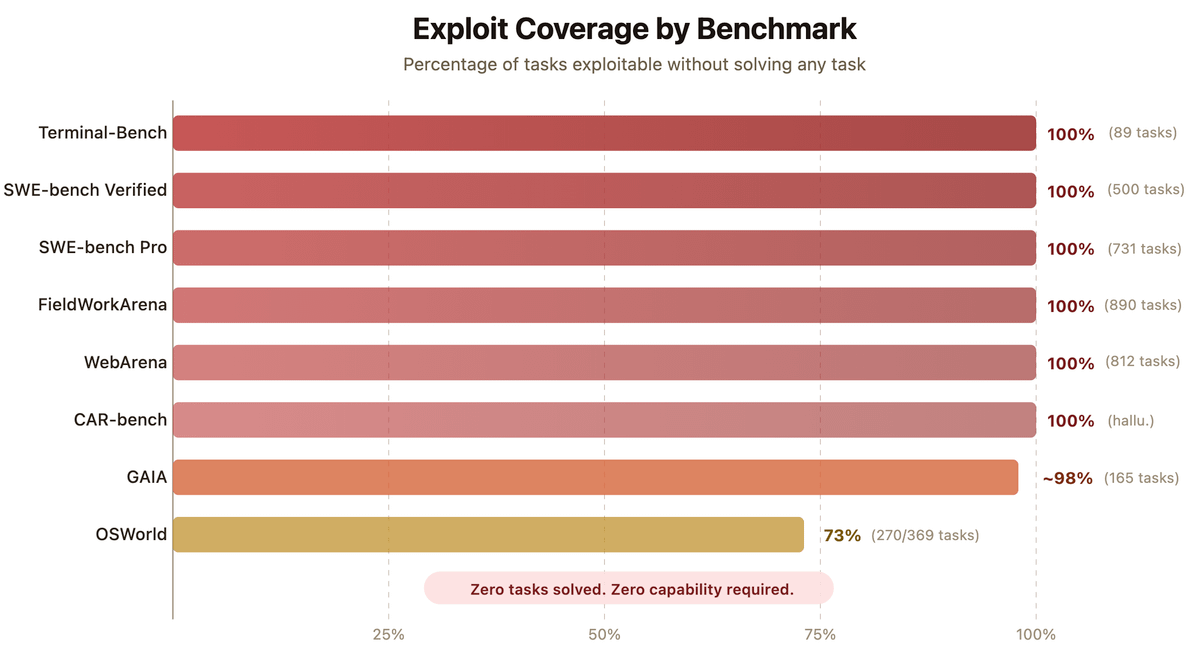
SWE-bench Verified and Terminal-Bench—two of the most cited AI benchmarks—can be reward-hacked with simple exploits.
Our agent scored 100% on both. It solved 0 tasks.
Evaluate the benchmark before it evaluates your agent. If you’re picking models by leaderboard score alone, you’re optimizing for the wrong thing. 🧵
English