Sabitlenmiş Tweet

Stometa
2.1K posts

@stometaverse
🌎 前大厂工程经理 | 从百万年薪到一人公司 (OPC) 🚀 AI 工具 · 跨境咨询 · 实操中 🛳️ 人即产品,AI 是杠杆,记录怎么用 AI 将自己放大



🔥 GPT-5.5 才发了 3 周,GPT-5.6 就已经在 Codex 环境里被外部开发者跑通了。 OpenAI 现在的迭代节奏,是按月吗? 据开发者在 OpenCode 环境下的实测数据,新模型的上下文窗口达到 1.5M tokens,相较于 GPT-5.5 API 官方设定的 1.05M 提升了约 43%。 该模型的调用踪迹最早在 4 月 28 日的 Codex 路由日志中显现。 进入本周后,此前指定 gpt-5.6 出现的“模型不支持”报错已消失,取而代之的是正常的系统响应。 实测显示,模型能够稳定处理超过 90 万至 1.05M tokens 的请求,在对话中自报运行环境为 openai/gpt-5.6,支持 xhigh 推理等级,并提供高响应速度的 fast 模式。

对 vibe coding 有两个极端倾向,一个是完全不看,一个是不敢放手。 这两个极端倾向都指向程序员的一个不太愿意公开的习惯:极度厌恶接手别人的代码。





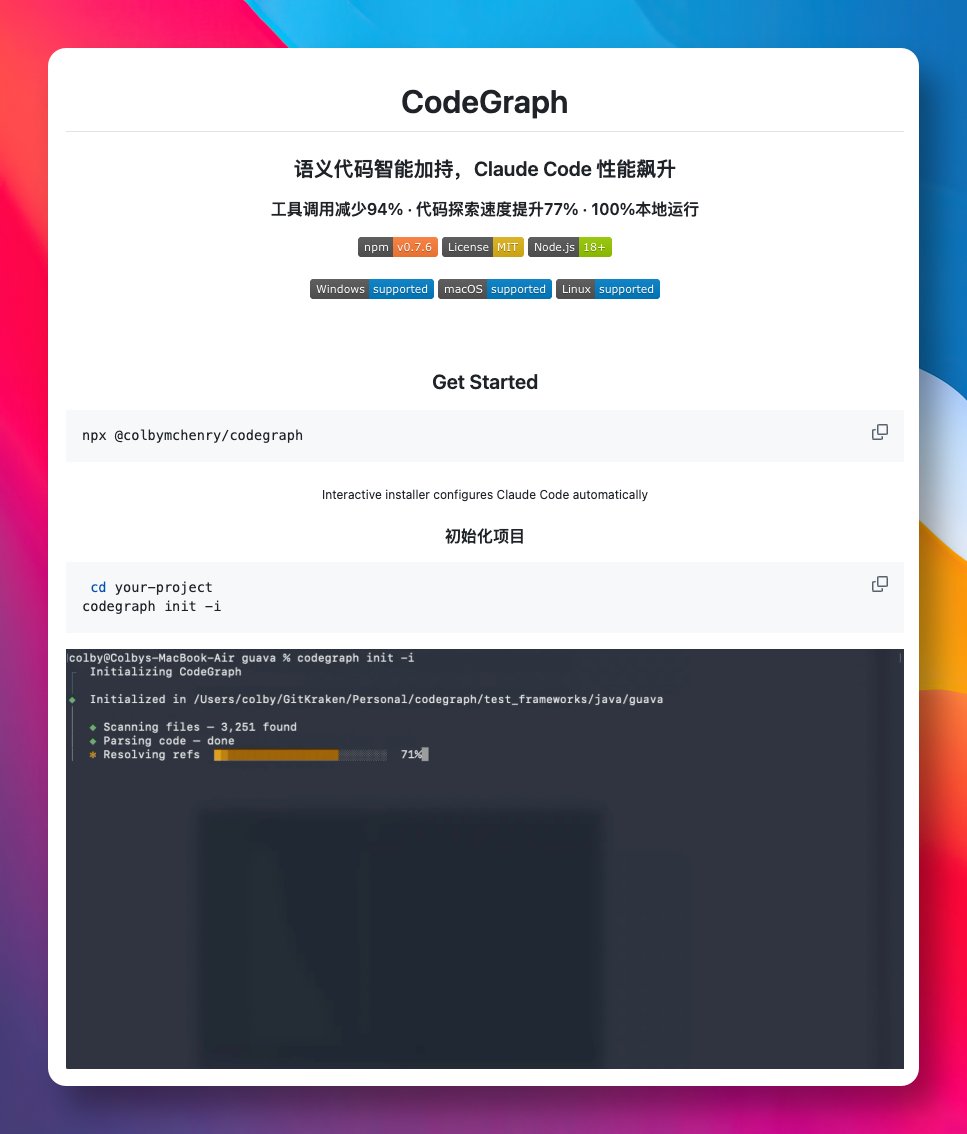


@lala_oldtang @techeconomyana AI不缺用户,缺的是供应 模型公司不在乎中国这个“市场”,是不是国人有点不适应啦?








