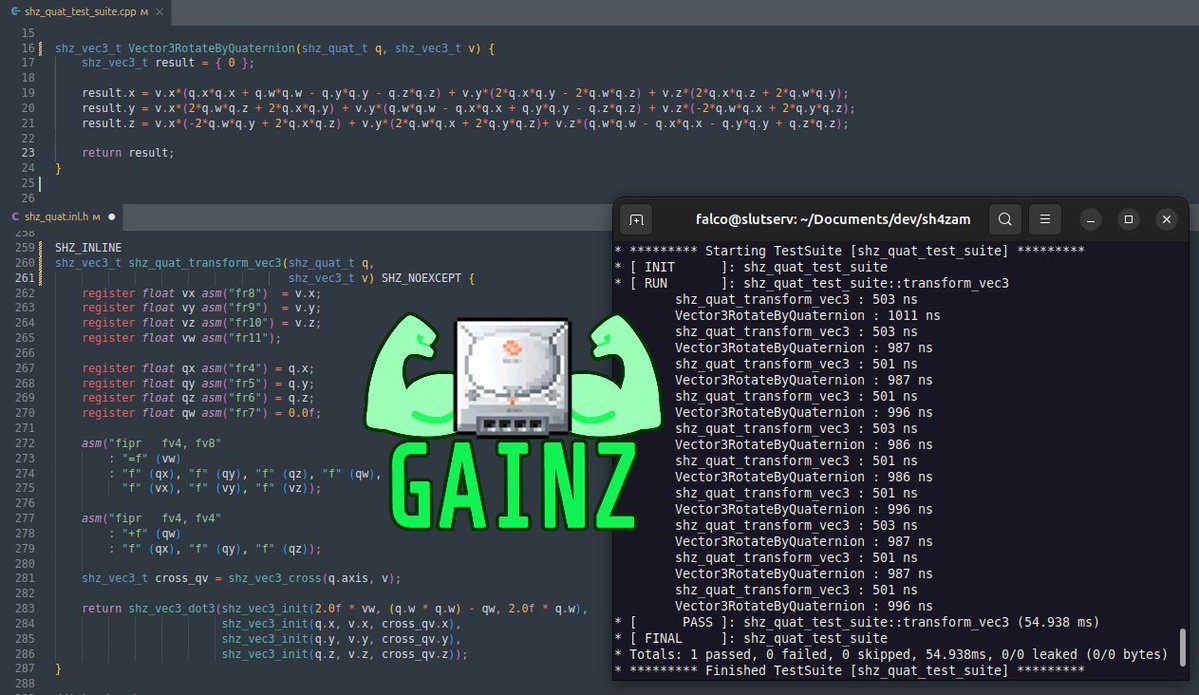
Holy CRAP, I just achieved a freaking 1.98x speedup for rotating a 3D vector by a quaternion on the Sega Dreamcast by using vectorized SH4 inline assembly over a standard C implementation!
This one I am OVER THE MOON WITH. The SH4 has historically been said to only accelerate vector and matrix operations, with a lack of HW acceleration for quaternions traditionally being called "lamentable" due to quaternion math not becoming mainstream until a bit after the console was created.
...bullshit. Yet again, I was able to accelerate quaternion math using the SH4's vector instructions and FPU, this time for SUBSTANTIAL performance gainz.
The trick? Why I was unable to achieve such gainz for so long? I spent so much time hyper fixating upon what has historically been accepted as the "optimal" floating-point algorithm for performing a quaternion rotation, based on minimal number of FP computations...
The problem? What is considered "minimal" for scalar FP math is not necessarily minimal when you have SIMD and vector instructions performing multiple FP operations in parallel!
One day I was verifying my implementation, when I ran into an alternate representation of the same operation, which was derived using a few linear algebra properties, yet was still mathematically equivalent to the original. This one being called "somewhat optimal," and "fairly fast," but was said to still be doing more work than necessary, compared to my previous implementation...
But the majority of the computational work? Is performing the dot product operation between 3D vectors! Which we all know, with FIPR, is a single instruction for us to accelerate on the SH4!
NOW, looking at the code, you can see the traditional algorithm on the top, implemented by the Vector3RotateByQuaternion() routine. This routine was taken from raylib--not because I'm picking on raylib, but because they typically have some of the prettiest, most straightforward implementations of linear algebra routines in pure, cross-platform C.
Not only that, but in my experience, the way raymath is written also facilitates optimal code generation from the compiler. So I'm using raymath's routine here, because it represents a competent, vanilla, no bullshit C implementation to benchmark against.
Now look at the balls-out SH4 optimized routine I implemented for SH4ZAM on the bottom pane. I am exploiting:
1) FIVE freaking 3D dot product patterns which I'm able to accelerate with FIPR either directly or through calling my special-case, chained dot-product routine, shz_vec3_dot3(), which carefully pipelines multiple FIPR calls together to calculate multiple dot products between a constant vector and batch of others.
2) CAREFUL register pinning, so that the compiler understands not only where operands must go for properly using them with the vector instructions, but also for knowing not to reload the invariants into FP regs across SH4 assembly boundaries.
The end result? The pane on the right shows the execution time for multiple invocations of the two routines with the same operands, using the cycle-accurate performance counters on the SH4 CPU.
Total gainz? About 100 clock cycles! 💪
GitHub commit and source code:
github.com/gyrovorbis/sh4…
@Stern_XD@TheBobPony Thanks for understanding, I’m actually quite good friends with the developer so I as well as him are very upset because he spends a large amount of time working on these patchers just for it to be shared for free by some asshole
@silly_lilah Don’t feel bad, Im running 7 on a 12th gen core i7, ddr5 and a 3080ti with an nvme 4th gen lol, people have told me I’m wasting the hardware
I spent a loooot of time looking through the code, and.... God *dayum*, they REALLY reinvented so much of the wheel in those codebases, like... MANY of the core routines they had to implement from scratch are just builtin to KOS and our toolchains now as part of the stdlib, and they "just work" as-is...
The main thing that would impede a port is that I can clearly see random x86 ASM interspersed throughout the codebase... that would all have to be converted to either C code or SH4 ASM for DC or another platform.
EA has uploaded fully recovered source code for Command & Conquer (aka, Tiberian Dawn). C&C Red Alert, C&C Renegade, and C&C Generals + Zero Hour to github. W move!
github.com/electronicarts/