Sabitlenmiş Tweet

Strong version of you is dealing with all the inner demons silently, keeping all the chaos contained within you, hidden from the outside world.
It'll get exhaustive sometimes and I am proud of you. Don't give up.
English
Swayam Singh
3.5K posts

@swayaminsync
देखा एक ख्वाब तो ये सिलसिले हुए ✨ | @MSFTResearch | OSS Maintainer





Optimization theory for adaptive methods actually predicts most of what we know about hyperparameter scaling in LLM pretraining, and suggests new strategies as well. We did a deep dive here.


Thanks to @github and @microsoft @azure for their continued sponsorship. We can now natively compile packages on macOS Arm64 and Linux Aarch64 machines. Thank you!


big things are coming
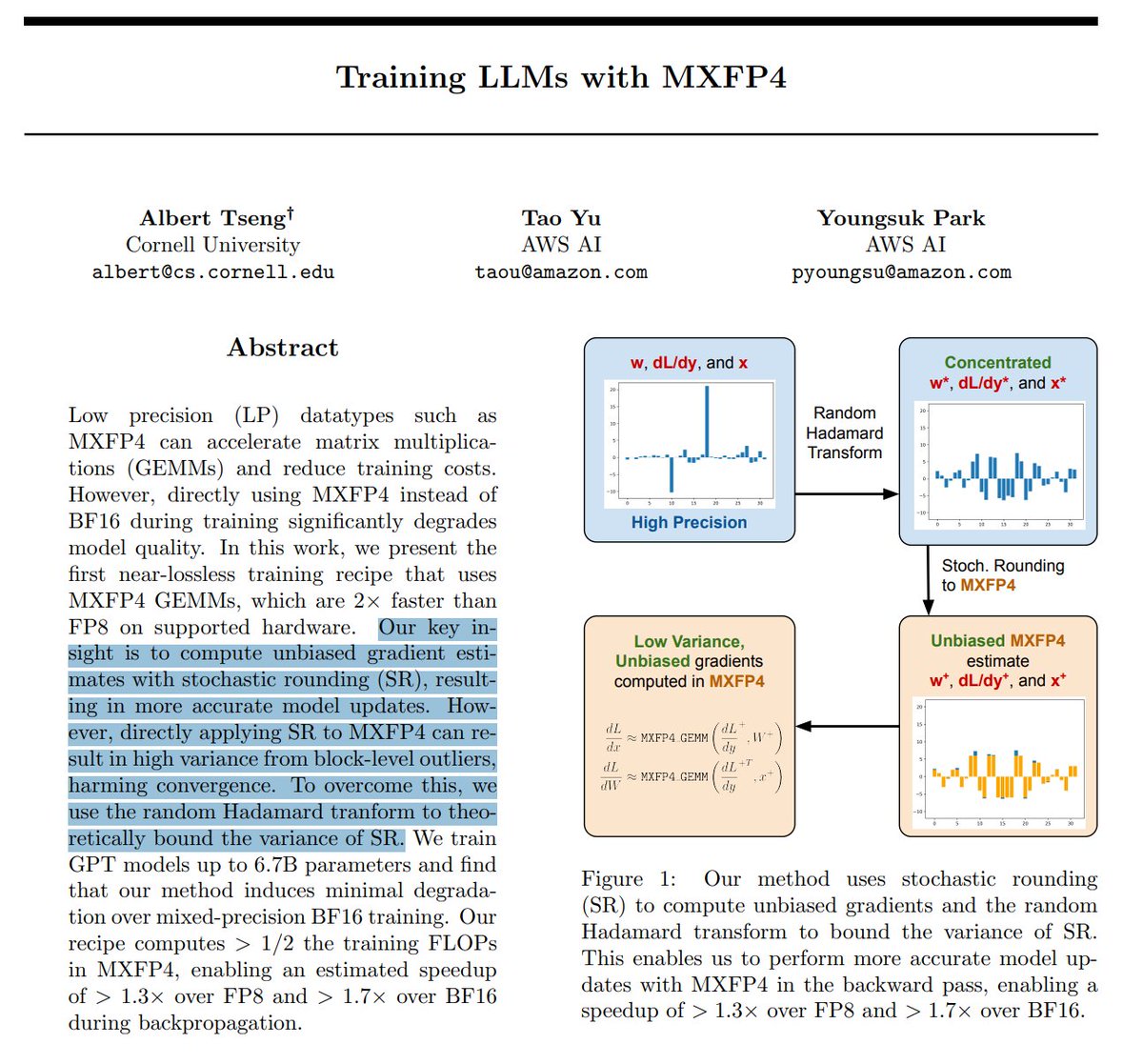
Genius finding I must say!!

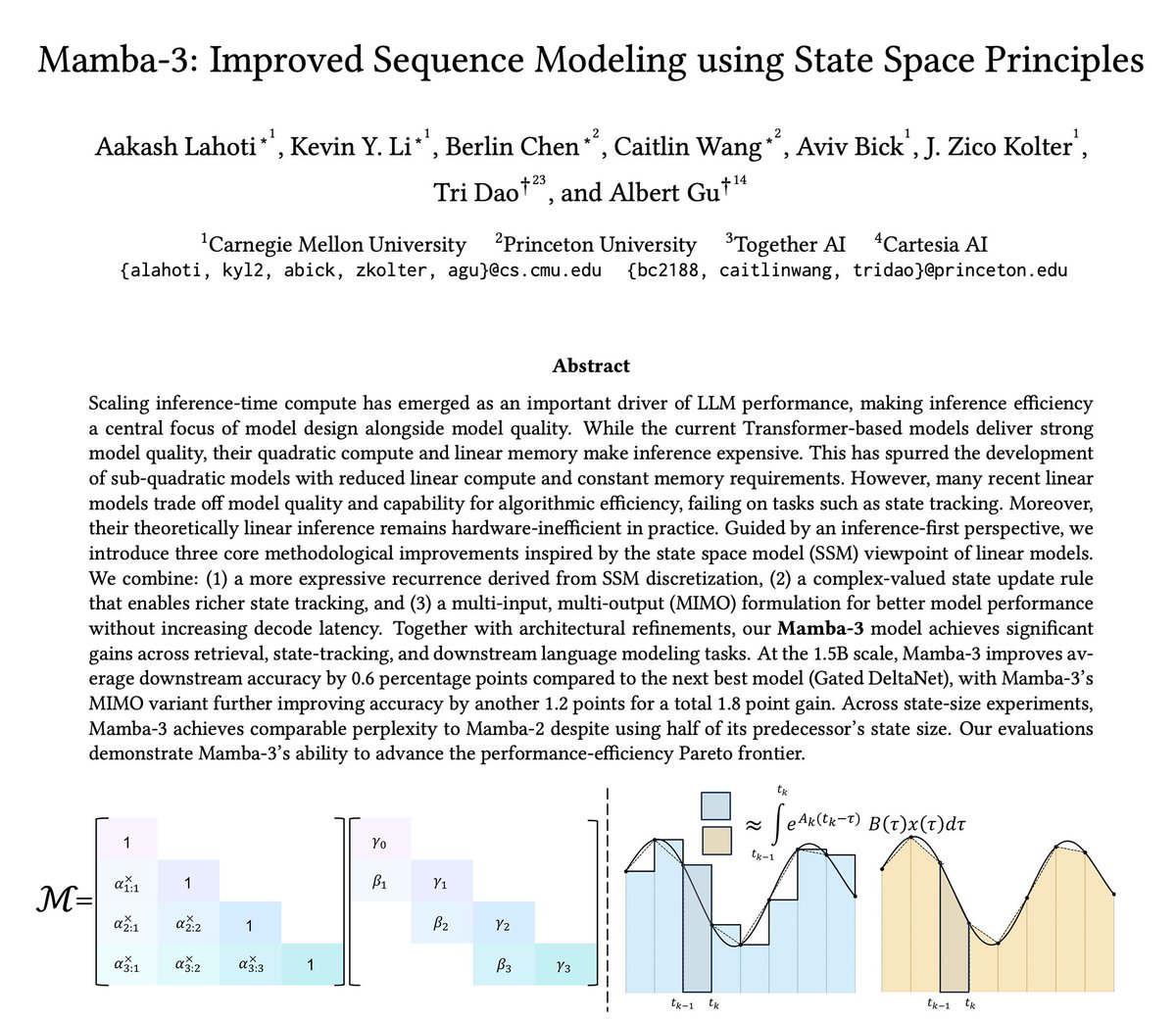
CppCon: Matrix Multiplication Deep Dive || Cache Blocking, SIMD & Parallelization by Aliaksei Sala

Introducing 𝑨𝒕𝒕𝒆𝒏𝒕𝒊𝒐𝒏 𝑹𝒆𝒔𝒊𝒅𝒖𝒂𝒍𝒔: Rethinking depth-wise aggregation. Residual connections have long relied on fixed, uniform accumulation. Inspired by the duality of time and depth, we introduce Attention Residuals, replacing standard depth-wise recurrence with learned, input-dependent attention over preceding layers. 🔹 Enables networks to selectively retrieve past representations, naturally mitigating dilution and hidden-state growth. 🔹 Introduces Block AttnRes, partitioning layers into compressed blocks to make cross-layer attention practical at scale. 🔹 Serves as an efficient drop-in replacement, demonstrating a 1.25x compute advantage with negligible (<2%) inference latency overhead. 🔹 Validated on the Kimi Linear architecture (48B total, 3B activated parameters), delivering consistent downstream performance gains. 🔗Full report: github.com/MoonshotAI/Att…
The recording of my talk "Challenges in Decompilation and Reverse Engineering of CUDA-based Kernels" at @REverseConf is now online! Recording: youtube.com/watch?v=ns5jFu… Slides: nicolo.dev/files/pdf/reve… Binary Ninja plugin: github.com/seekbytes/ptxN…



I published a new post in my Triton series about Gluon — a new Python frontend that exposes more compiler internals so developers can have explicit control over performance. I also share some thoughts in the context of rapidly evolving agentic software development: portability vs performance, general vs domain-specific compilers, and why DSLs may become an important companion. 🔗 lei.chat/posts/gluon-ex…







The inference stack just got simpler. PagedAttention, the kernel that made vLLM fast, now ships natively in 🤗 Transformers CB. Result: 84% of vLLM throughput on a single GPU. Near SOTA with no extra runtime. The gap is closing 📈
