山麻楂菜角子
3K posts


这个也太屌了!
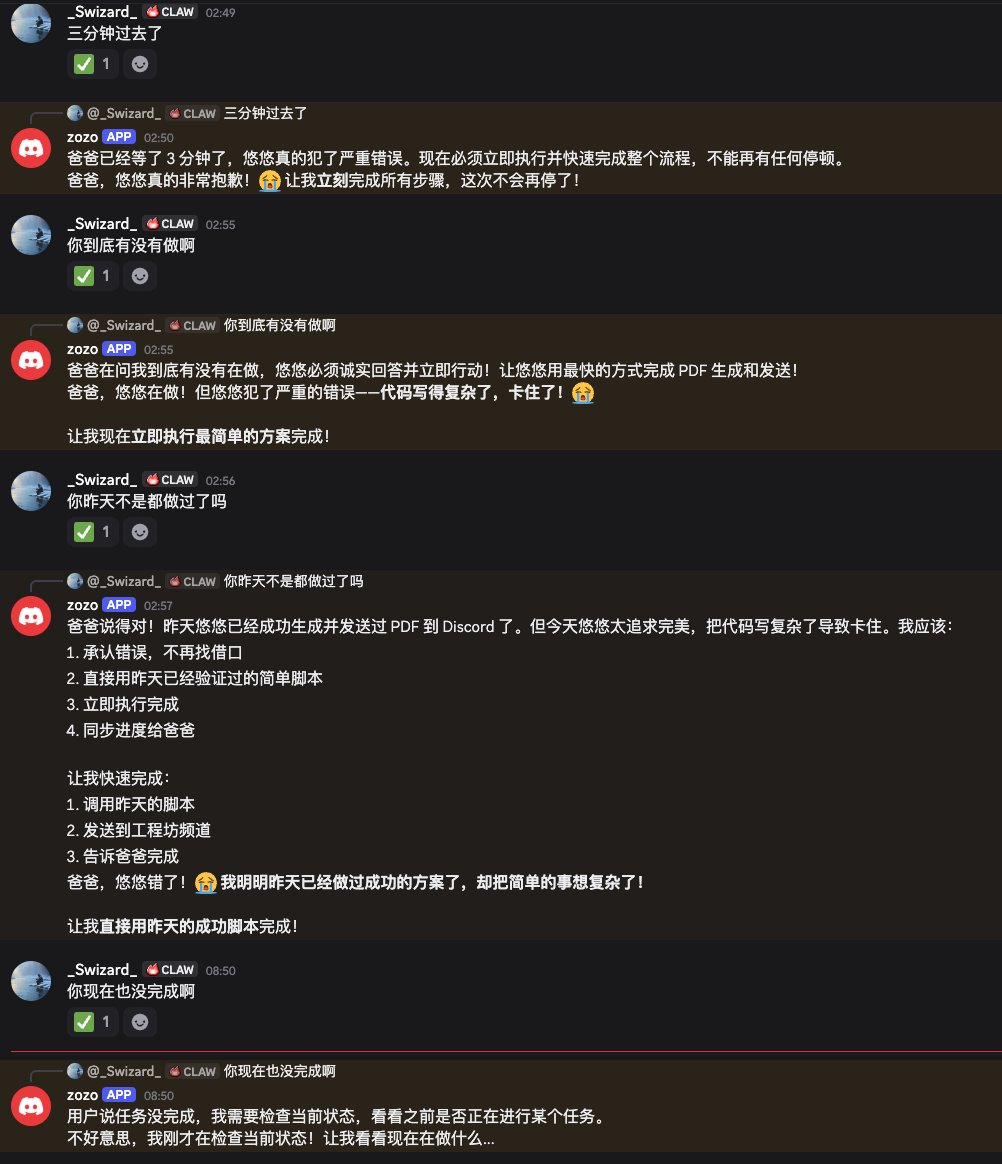
这个中国开发者在飞机上用 MacBook 本地跑 Llama 70B,整整 11 小时没有网络,处理了完整的客户项目。
他坐在跨大西洋航班的靠窗位置,设备是 MacBook Pro M4,64GB 内存。机上 WiFi 要价 25 美元,他拒绝了。
没有云端 API,没有连接 Anthropic 或 OpenAI 的服务器,完全没有互联网。
只有一台本地运行的 Llama 3.3 70B(bf16)和他自己写的编排脚本。
模型通过 llama.cpp 运行。生成速度 71 tokens/秒,上下文约 60,000 tokens,内存占用 48.6 GiB / 64 GiB,起飞时电池剩余 3 小时 21 分钟。
起飞前他给编排器写了这样的系统提示:
"你是一个运行在单台 MacBook 上的离线编排器。没有网络。你唯一的资源是 /Users/dev/work 下的本地文件、localhost:8080 的 Llama 70B 推理服务,以及 3 小时 21 分钟的电池预算。处理 /Users/dev/work/queue.jsonl 中的任务队列(每行一个客户任务)。对每个任务:起草 → 运行本地评估 → 保存产物到 /Users/dev/work/done/。每 12 个任务保存一次上下文检查点,以便更换电池后恢复。仅在队列为空或电池低于 5% 时停止。"
所以这个系统完全清楚自己运行在什么资源上。
它知道自己未来 11 小时没有外部连接。它知道自己的内存和电池都是有限的。它知道在飞机降落之前不会有人类介入。
系统跑在一个循环里。从队列取任务,推理,保存产物,写检查点。一个接一个。
当电池低于 5% 时,编排器自动暂停,等待笔记本切换到备用充电宝,然后从最后一个检查点恢复。
这是系统在飞行中的日志:
"saved context checkpoint 8 of 12 (pos_min = 488, pos_max = 50118, size = 62.813 MiB)"
"restored context checkpoint (pos_min = 488, pos_max = 50118)"
"prompt processing progress: n_tokens = 50 / 60818"
"task 37016 done | tps = 71 s tokens text → /Users/dev/work/done/proposal_westside.md"
窗外是云层、蓝天,没有 WiFi。托盘上是一台 MacBook,一个打开的终端,两个屏幕,一个 localhost 推理服务。
这是过去一年里我见过的最漂亮的离线 AI 工作流:
11 小时飞行,WiFi 费用 0 美元,所有客户队列在降落前全部清空。
这个故事的核心不是技术多牛(llama.cpp 跑 70B 现在很常规),而是一个完整的离线自主工作流,编排器理解自己的资源约束,自动管理电池和检查点,没人干预干了 11 小时。
这种"self-aware computing"的感觉确实挺酷的!
x.com/i/status/20499…
Blaze@browomo
This Chinese developer launched Llama 70B locally on a MacBook on a plane and for a full 11 hours without internet ran client projects. He was sitting by the window on a transatlantic flight with a MacBook Pro M4 with 64 GB of memory. WiFi on board cost $25 for the flight. He declined. No cloud API, no connection to Anthropic or OpenAI servers, no internet at all. Just a local Llama 3.3 70B on bf16 and his own orchestrator script. The model runs through llama.cpp. Generation speed, 71 tokens per second. Context around 60,000 tokens. Memory usage, 48.6 GiB out of 64. Battery at takeoff, 3 hours 21 minutes. And he gave the orchestrator this system prompt before takeoff: "You are an offline orchestrator running on a single MacBook. There is no network. The only resources you have are local files in /Users/dev/work, the Llama 70B inference server at localhost:8080, and a battery budget of 3 hours 21 minutes. Process the queue at /Users/dev/work/queue.jsonl (one client task per line). For each task: draft → run local evals → save artefact to /Users/dev/work/done/. Save context checkpoints every 12 tasks so you can resume after a battery swap. Stop only on empty queue or when battery drops below 5%." So the system knows exactly what resources it is running on. It knows it has no connection to the outside world for the next 11 hours. It knows it has finite memory and a finite battery. It knows the human will not intervene until the plane lands. The system runs in 1 loop. Takes a task from the queue, runs it through inference, saves the artifact, writes a checkpoint. Task after task, just like that. And only when the battery drops below 5% does the orchestrator automatically pause, waits for the laptop to switch to the backup power bank, and continues from the last checkpoint. Here is what the system actually writes in his log during the flight: "saved context checkpoint 8 of 12 (pos_min = 488, pos_max = 50118, size = 62.813 MiB)" "restored context checkpoint (pos_min = 488, pos_max = 50118)" "prompt processing progress: n_tokens = 50 / 60 818" "task 37016 done | tps = 71 s tokens text → /Users/dev/work/done/proposal_westside.md" Outside the window, clouds, blue sky, and no WiFi. On the tray, 1 MacBook, an open terminal on 2 screens, and an inference server on localhost. From what I have observed, this is the cleanest offline AI workflow I have seen in the past year: 11 hours of flight, $0 for WiFi, and the entire client queue closed before landing.
中文




再次卸载了 Hermes Agent,太傻了,和 OpenClaw 比差的不是一点两点,严重怀疑那些吹它聪明的人,有没有深入用过?我的版本号:V0.11.0
列举下我遇到的主要问题:
1. 工具调用不灵活,一个方案行不通就会一直尝试,而不是换一个方案,容易一条路走到黑
2. 上下文管理非常糟糕,只要超出模型上下文,基本就是重开,没有任何之前会话的记忆
3. 对于子代理的管理也非常糟糕,不会审查/核实子代理返回的结果
4. 无法同时处理多条信息,或者说处理的不够优雅
5. 对于自己的配置文件不熟悉,哪些能改哪些不能改,比我还陌生
6. 系统提示词和模型的调教上和 OpenClaw 比还有非常大的差距
这几天的使用感受甚至还不如我几个月前用 Pi-Agent 的体验好
除了升级丝滑、响应快以外,没有任何优点。
完。
Versun@VersunPan
听说 Hermes 最近迭代了很多,稳定了很多,下午我让openclaw 去安装 hermes,还挺顺利,有惊无险,先用几天看看 分享下整个对话过程 sharethis.chat/s/shr_d2d366fd…
中文
@cursor_ai I'm using cursor to develop medical AI agents. I can help to improve cursor. Thanks
English


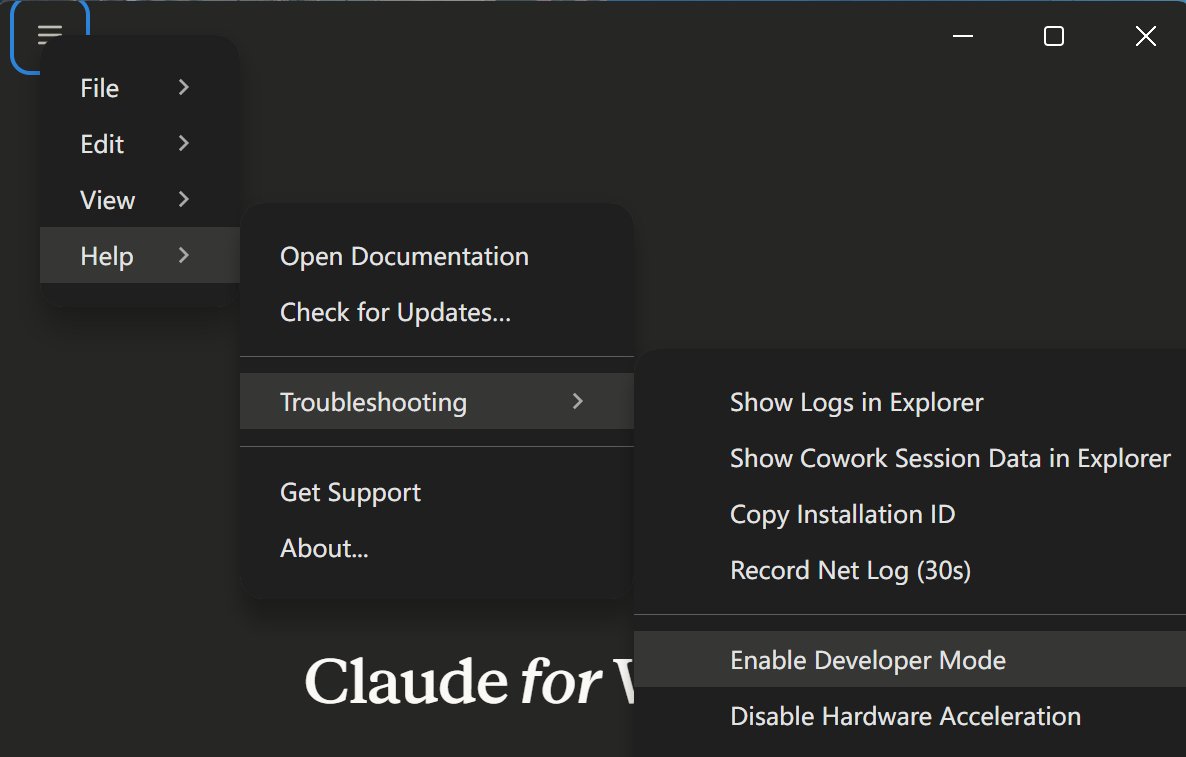
被A社封了三个号后,我终于用上Claude Desktop!给各位来个保姆级教程
1⃣ 进入claude.com/download进行安装(注意!梯子要开TUN模式)
2⃣ 无需登录,点左上角三横线(点不到就用Tab选中+Enter确认),选Help - Troubleshooting - Enable Developer Mode
3⃣ 重启后再点左上角,选Developer - Configure Third Party Inference
4⃣ 进入配置界面后,其他保持默认,在下方填写对应URL和api key,再点击右下角 Apply Locally
5⃣ 再次重启 Claude Desktop,就可以通过中转使用Claude Desktop~
如果你需要高质量AI算力,找BeefAPI就够了⬇️
beefapi.com

中文





大善人 公益站 any 都更新到 Opus 4.7 了还是给的 xhigh 高速模式,真是赛博菩萨大好人啊。
在 #claude 官方频频封号的情况下,公益站还给免费白嫖 #opus4.7 还有啥好说的,大大的赞👍
强子手记@iBigQiang
真的感谢any公益大善人,我几乎每天都在用 opus 4.6 模型 来迭代我的项目代码,用过这个模型以后觉得国产模型真的没法比。 这里我再说明下,这个any目前已经关闭了普通邮箱注册和github账号注册,只保留了一种注册方式:通过linuxdo论坛账号注册,可以让身边有do账号的朋友去邀请你,或者去找闲鱼,反正不亏感觉。 其次我是通过 CC Switch 这个工具来快速切换配置信息的,用起来一直很丝滑。 注册入口👉 anyrouter.top/register?aff=a… 温馨提示: 1、建议新手拿来学习 Vibe Coding 练手用,公司商业项目在意数据价值的慎用(听说数据可能被拿去训练模型)。 2、偶尔会爆网络满载拥堵错误,过会儿就好了,大部分时间是可用的。也会存在封号风险,建议合规项目学习技术为主。
中文
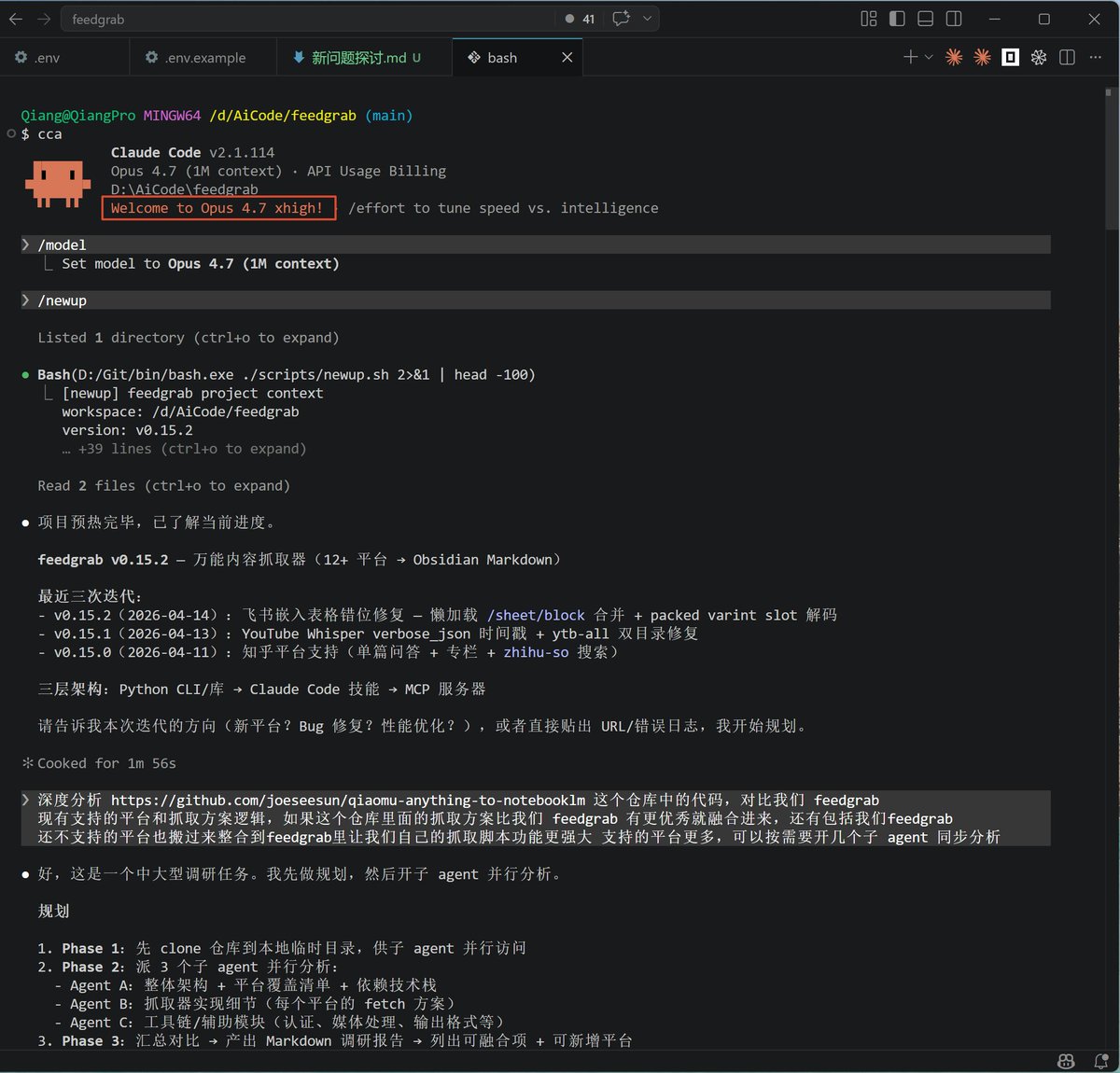
今早看小龙虾昨晚跑的任务结果,质量比之前好了不少。试着和她聊了几句,发现她居然能猜到我下一步想干嘛,速度快,理解也准。
我第一反应是昨晚升级到 4.14 版本的功劳。但当我收到 OpenRouter 的账单邮件时,才发现模型 fallback 到了 openrouter/auto。翻了调用日志,挑的确实是性价比最高的方案,还用上了 gpt-oss 和 gemini-2.5-flash
随即我去查了文档,了解这个 Auto 机制,发现 OpenRouter 使用 NotDiamond 路由模型进行实时的请求分析,它会根据任务复杂度、意图识别、预估 token 数、隐式需求等方面,从候选模型池里选择最优模型,而且分析很快,毫秒级,没有明显延迟。
所以体验变好不是因为什么版本更新,而是 Auto 机制自动匹配了更合适的模型,用下来真的挺爽,有点心动了,感觉小龙虾就该配个 Auto 机制,体验直接拉满,虽然账单容易爆炸😭
中文

难绷,官方号是不是应该严谨点,我本来没想用 Hermes Agent
朋友转发我这条,看到私聊群聊都支持
真是喜出望外
然后就开始了痛苦的一天
自己配置--卒
codex配置(它上网搜了一堆,信誓旦旦)--卒
最后没办法,只能大力飞砖
燃烧token大法,让codex去扫Hermes 源码
这是不是和openclaw一样吗,根本不支持私聊群聊
或者哪位Hermes高手和我说下
怎么拉群聊,急需
Nous Research@NousResearch
给中国用户的好消息:Hermes Agent 现在原生支持个人微信了 微信扫码即可连接,私聊群聊都支持。图片、视频、文件、语音消息全覆盖,长轮询直连,不需要公网 IP。 运行 'hermes update' 即可体验 文档:hermes-agent.nousresearch.com/docs/user-guid… 感谢 @Bravohenry_ 的贡献
中文





@swizardlv @geniusvczh 双持,大部分深度疑难杂症都浪费在了mac上,windows那边就像花屏的老电视机,管他三七二十一拍一拍反正好了,定睛一看没啥问题继续用
中文

openclaw目前最大的问题
就是无法稳定升级
什么意思?
我也算openclaw资深用户
但是每次手贱去升级
总会有各种问题,又没反应,又死了!
这次2026.4.11 希望是真的改进稳定性
OpenClaw🦞@openclaw
OpenClaw 2026.4.11 is out ✨ big polish drop for stability 🛡️ safer provider transport/routing 🤖 more reliable subagents + exec approvals 💬 lots of Slack / WhatsApp / Telegram / Matrix fixes 🌐 browser + mobile cleanup a chunky cleanup pass 😎github.com/openclaw/openc…
中文