Sabitlenmiş Tweet

Here is our Chrome Extension that allows you to go to Synthical from arXiv, bioRxiv, medRxiv, and hf papers.
Go check it out 🚀
Link: chromewebstore.google.com/detail/synthic…
Source code: github.com/mixeden/synthi…
English
Synthical
10.2K posts
@synthical_ai
App to supercharge your research


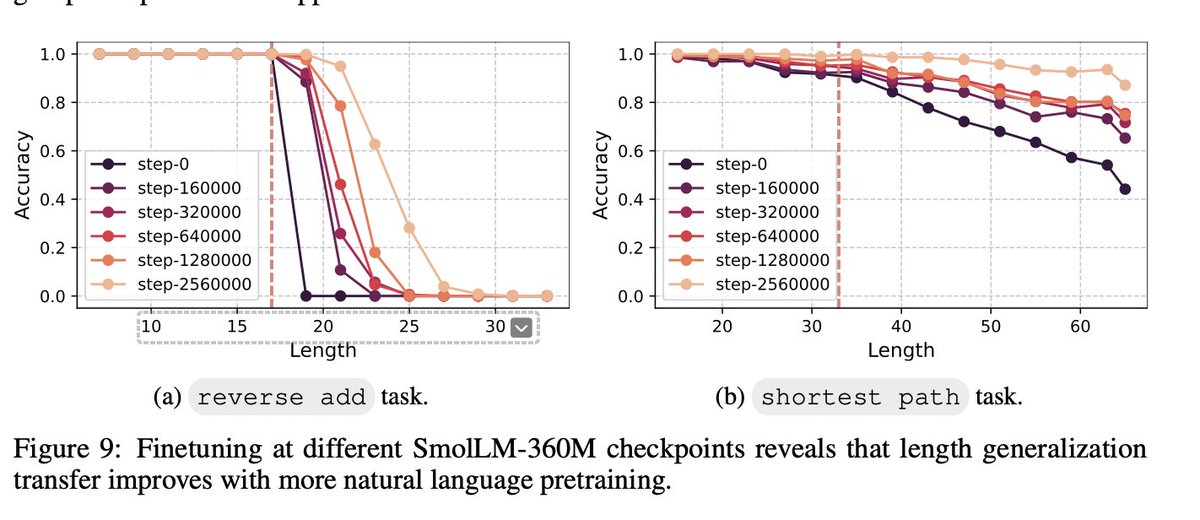
Excited about our new work: Language models develop computational circuits that are reusable AND TRANSFER across tasks. Over a year ago, I tested GPT-4 on 200 digit addition, and the model managed to do it (without CoT!). Someone from OpenAI even clarified they NEVER trained GPT-4 explicitly on 200-digit arithmetic. (can't find the tweet :( ) How?? It felt like magic. In controlled arithmetic tests on transformers, length generalization consistently failed. There must be something magic about pretraining? Turns out there's a clean, simple, and plausible answer: Transfer. Here is what we find with Jack @jackcai1206 Nayoung @nayoung_nylee, Avi @A_v_i__S, and my friend Samet @SametOymac: Language models develop computational circuits that TRANSFER length generalization across related tasks.arxiv.org/abs/2506.09251 A "main" task (like addition) trained on short sequences inherits length capabilities from an "auxiliary" task (like carry prediction) trained on longer sequences, if the model is co-trained on BOTH. This happens even when we train from scratch on only task A and B. But it only happens when A and B are related. So, length TRANSFERS between tasks, when they are similar. I think this is very cool! We tested this across three types of tasks: - arithmetic (reverse addition, carry operations) - string manipulation (copying, case flipping) - maze solving (DFS, shortest path). Same pattern! We also find that language pretraining acts as implicit auxiliary training. Finetuning checkpoints at different pretraining stages shows that more pretraining => better length generalization on downstream synthetic tasks. After ~3 years studying length generalization, much of the initial magic has dissipated. And that's great! This is what science does. It lifts the veil of ignorance :)




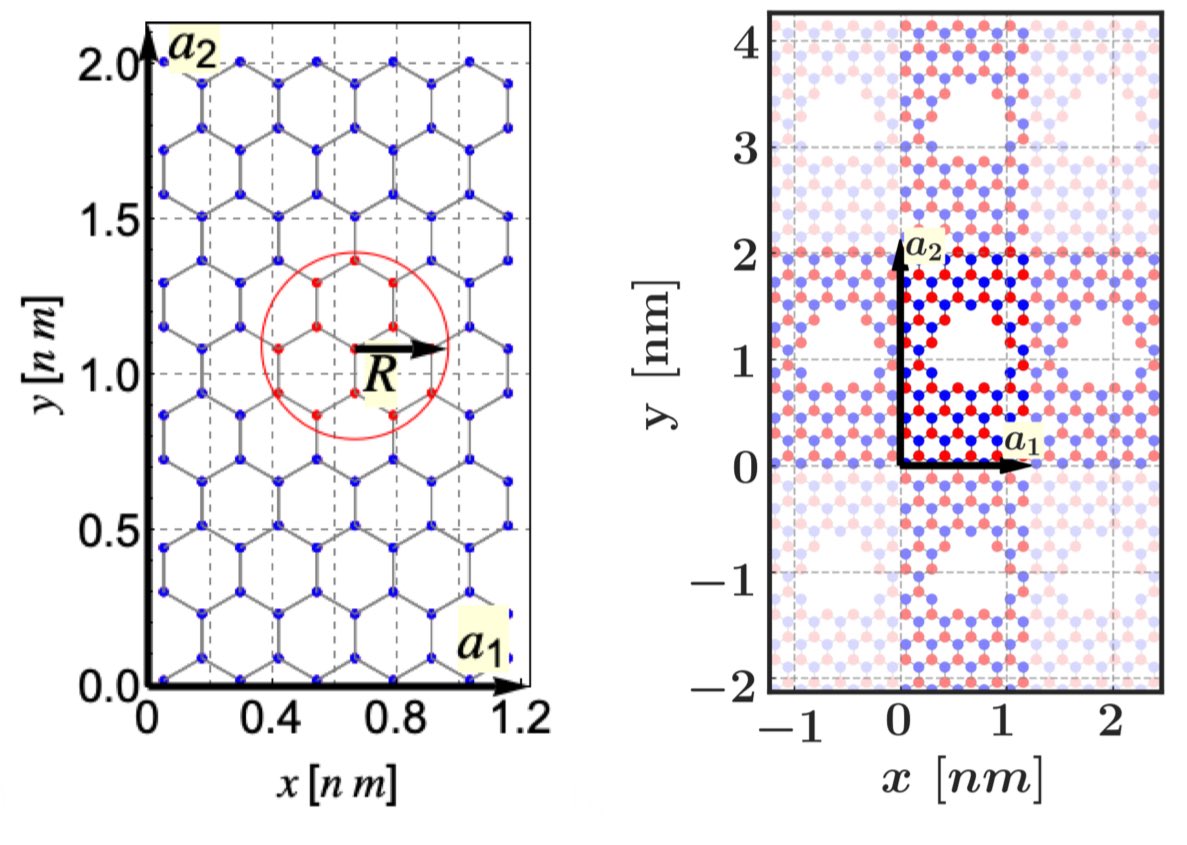





🚀 New Paper: Scaling Laws and Efficient Inference for Ternary Language Models. Thrilled to share that our work was presented at ACL 2025! We explore ternary LMs (TriLMs), studying their scaling laws and efficiency compared to traditional FloatLMs. 🧵 1/6