
Steven Shen
2.3K posts

Steven Shen
@syshen
Cofounder and CTO of CuboAi CEO of JidouAI ex-Circler
Taipei, Taiwan Katılım Ocak 2008
447 Takip Edilen356 Takipçiler

I just built a Claude Code SEO agent that replaces your $200/mo. Ahrefs subscription 🤯
One prompt → keyword gaps found, competitors analyzed, content written in your brand voice, rankings tracked weekly.
All inside Claude Code.
Perfect for DTC brands and agencies who know SEO matters but never have the bandwidth to actually do it consistently.
If your SEO workflow looks like this — log into Ahrefs once a month, export a CSV, skim it for 5 minutes, close the tab, tell yourself you'll write that blog post next week, never do...
This agent runs the entire loop for you:
→ Connects to Google Search Console and pulls your real ranking data
→ Finds your "gap zone" — keywords sitting at positions 5-20, one article away from page 1
→ Uses Apify to scrape who's outranking you and breaks down exactly why they're winning
→ Interviews you once about your brand, customers, and positioning — then never asks again
→ Writes content in your voice — not generic AI slop that tanks after 90 days
→ Tracks rankings weekly and feeds what's working back into the next cycle
→ Optimizes your product listings for AI shopping — so you show up when someone asks ChatGPT for a recommendation, not just Google
No $200/month tools you open once and forget.
No freelancers writing content that sounds like everyone else.
No manually checking rankings and forgetting to act on it.
What you get:
- Keyword cards with a specific action recommendation for each gap zone opportunity
- A competitive breakdown — who's beating you and the exact fix for each keyword
- A weekly content plan generated from your real GSC data
- A brand voice profile Claude uses for every article it writes
- Product listing optimization for AI shopping (ChatGPT, Gemini, Perplexity) — the new SEO nobody's doing yet
Built 100% in Claude Code with Google Search Console.
I put together a full playbook with the skill files, brand interview, and the exact weekly workflow.
Want it for free?
> Like this post
> Comment "SEO"
And I'll send it over (must be following so I can DM)
English
These days, launching an agent to build the feature is way more efficient than spending time with team members. Nobody writes code anymore — everyone’s a PM.
Guri Singh@heygurisingh
Holy shit. Anthropic engineers don't write code anymore. A new hire just leaked what's actually happening inside the company shipping harder than anyone in 2026: Nobody on his team has hand-written code in months. They run multiple agents in parallel and act like managers, not engineers. His exact words: "if you're just watching an agent code, you're already behind. that idle time should be spent spinning up another agent and directing it somewhere else." The mental model isn't "use AI to code faster." It's "you are the PM, the agents are your engineers, and your job is to keep all of them unblocked." He called it being "fully AI aligned" as a team and said it changes what's even possible to build. The productivity gap between people who think this way and people who don't is already enormous. And the proof is simple: Anthropic has shipped harder than any company in 2026. If you're still hand-writing code, you're not behind on tools. You're behind on the job itself.
English
I recently told my engineers — if getting you to do something isn't faster than just asking AI directly, your value is being replaced. If engineers want to stay relevant, they need to figure out how to use AI better so their output is actually worth more. And that value isn't just about writing code anymore. Engineers need to expand their role outward, becoming more like mini PMs who can independently identify and solve problems on their own.
English

@lennysan @AnthropicAI I read that as he left Anthropic and joined Twitter hahaha
English

Amol (Head of Growth at @AnthropicAI) just joined Twitter. Follow for free alpha.
BTW, can you believe they hit $30B ARR before they even released Mythos?
Amol Avasare@TheAmolAvasare
Had a great chat with @lennysan on some of the fun stuff happening at the intersection of AI and growth! Thanks for having me on Lenny, had a blast :) open.spotify.com/episode/08QWCm…
English
@karpathy @ycombinator I’ve been doing something similar — storing everything about my business as markdown files in a structured directory.
What’s been even more powerful is running an agent on top of this knowledge base that can actually operate my Google Ads campaigns.
English

LLM Knowledge Bases
Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So:
Data ingest:
I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them.
IDE:
I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides).
Q&A:
Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale.
Output:
Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base.
Linting:
I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into.
Extra tools:
I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries.
Further explorations:
As the repo grows, the natural desire is to also think about synthetic data generation + finetuning to have your LLM "know" the data in its weights instead of just context windows.
TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.
English
Facing the challenge from OpenClaw, Anthropic’s answer is making Claude better with dispatch and channel features.
Thariq@trq212
We just released Claude Code channels, which allows you to control your Claude Code session through select MCPs, starting with Telegram and Discord. Use this to message Claude Code directly from your phone.
English

最近台北是不是很常突然停電?
我現在跟老婆住月中,用遠端操縱家裡的 OpenClaw agent,但 Mac mini 動不動就斷電,這兩天應該斷第三次了,每次時間都很短,但 Mac mini 沒有電池,斷電就直接關機,有點困擾啊。
中文

评语:现在的 NBA 从上到下都烂透了。还记得以前扣篮大赛是必看节目吗?这就是今天的冠军扣篮:
x.com/NBA/status/202…
中文
Steven Shen retweetledi

4% of GitHub public commits are being authored by Claude Code right now.
At the current trajectory, we believe that Claude Code will be 20%+ of all daily commits by the end of 2026.
While you blinked, AI consumed all of software development.
Read more 👇 newsletter.semianalysis.com/p/claude-code-…
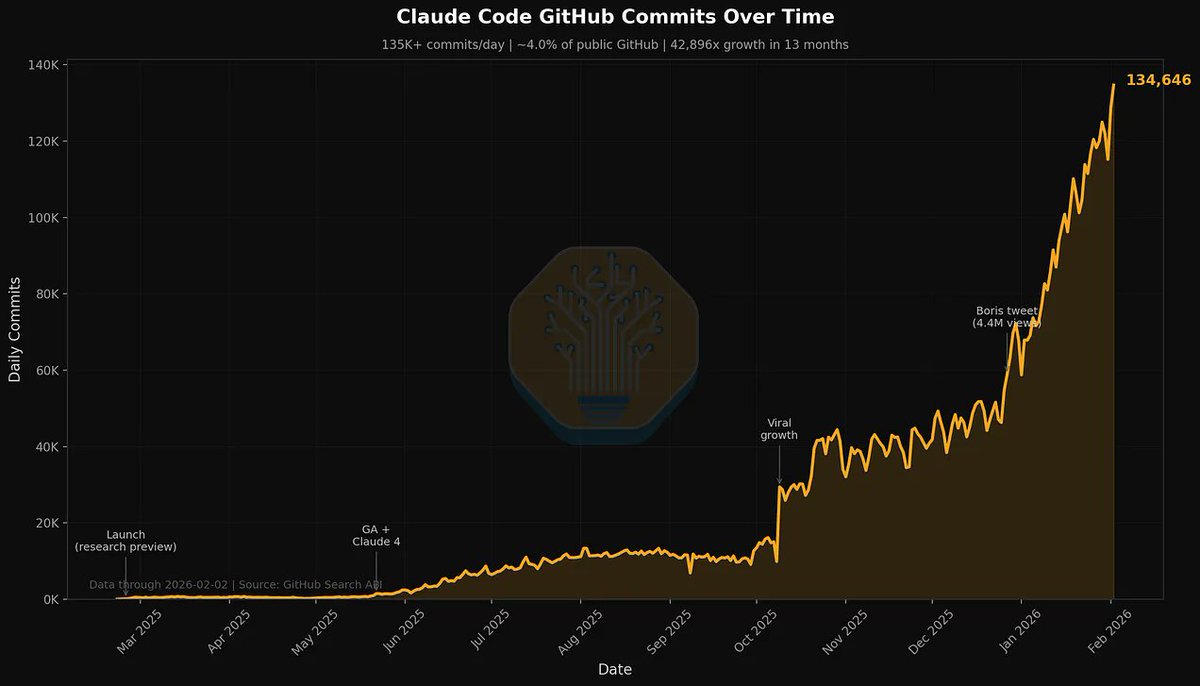
SemiAnalysis@SemiAnalysis_
Claude Code is the Inflection Point, What It Is, How We Use It, Industry Repercussions, Microsoft's Dilemma, Why Anthropic Is Winning. newsletter.semianalysis.com/p/claude-code-…
English

I wrote about this + a real example from our team's dev workflow here: syshen.me/blog/ai-native…
#AINative #SoftwareDesign #FutureOfWork
English
CRM, ERP, project management — all designed around human workflows.
In an AI Native world? Just tell AI what you need. It knows. It acts. No dashboard required.
English
🧵 The next wave of software won't be designed for humans.
Here's why AI Native Software is the next paradigm shift:
English
2026: blogging again, but differently.
No AI hype. Just my thoughts.
syshen.me/blog/vibe-codi…
English

"Our marketing team is just me and ~40 AI agents."
-Million-dollar founder with no marketing team
Want the template? Retweet + Reply and I'll DM you.
English