
t2ruva
5.6K posts

t2ruva
@t2ruva
Ambassador @driaforall Holder @CelestineSloths @MammothOverlord @ModularCards @OnchainOMies @AptosMonkeys @Aptomingos @v_on_vana @WhaleSharkNFTs
Meta Katılım Kasım 2021
737 Takip Edilen2.9K Takipçiler


t2ruva retweetledi

Living with Myasthenia Gravis? Join our secure at-home study, earn up to $250, and help advance research! aminochain.io/mg-study
#MyastheniaGravis #PatientCenteredResearch #RareDisease #DecentralizedTrials

English

We were pretty confident that in Web1 and Web2, major part of the data was produced by the real people. But today internet is becoming more synthetic with the rise of ai. Hence original data matters more than ever and will matter more. Paralelly we need quality over quantity which again reminds us that we need more human centric data to train our models for better functioning
As a result we need more intelligent and efficient ways to shape this technology for the ultimate utilization in our lives. Here Hub's business model seems highly robust by focusing real world data rather than repetitive synthetic data with the current infrastructure owned by the people and combining it with a revenue sharing model on blockchain
English

AI models are eating faster than the internet can grow
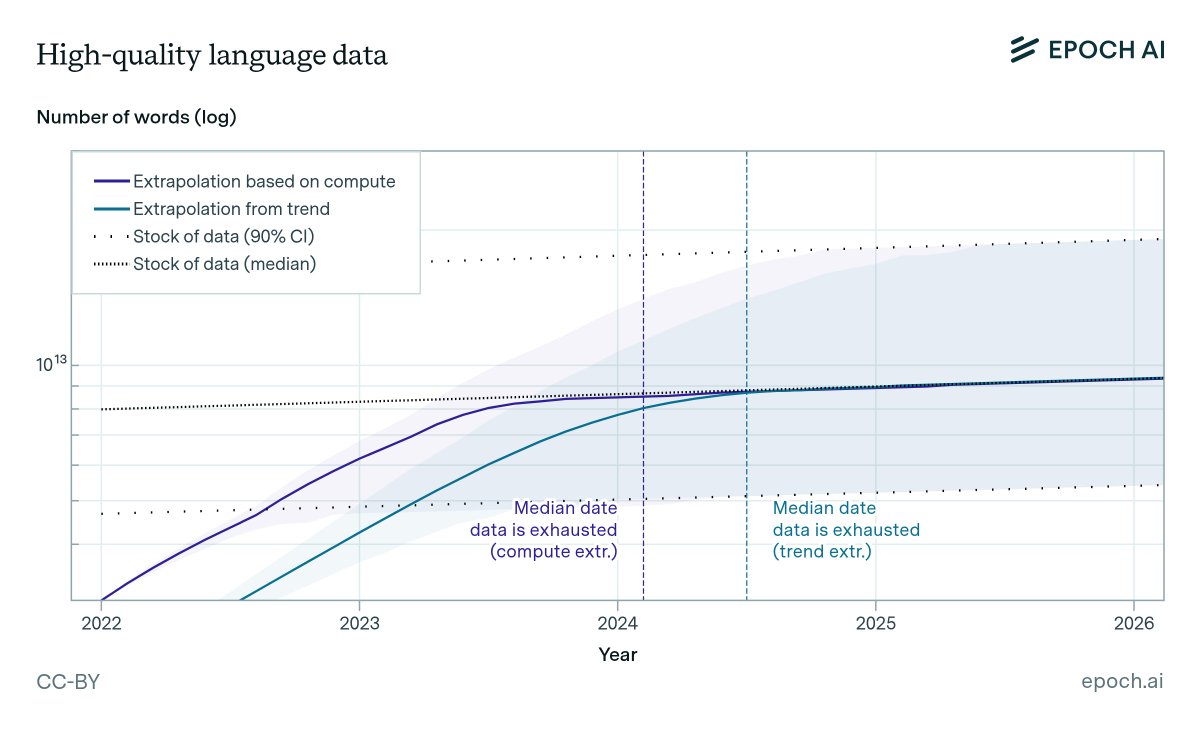
Epoch AI published one of the most important papers in the AI industry. They estimated the total stock of quality human-generated text at ~300 trillion tokens, and projected an 80% probability that frontier models exhaust it between 2026 and 2032.
We are inside that window now.
But the real crisis is worse than the paper predicted.
The supply isn't just finite. It's shrinking. Over 74% of newly created web pages now contain AI-generated text. The internet is being contaminated by the very models it trained. Every generation of AI pollutes the training data for the next one.
The industry tried synthetic data as a fix. The research killed that idea. Models trained on their own outputs degrade. They lose the nuance and variability that made human data valuable. Without real human data as an anchor, quality collapses.
Meanwhile, training costs keep climbing. GPT-4 cost ~$40M. The current generation is approaching $1B. The next: $10B+. Every dollar spent scaling compute accelerates the depletion of the data these models depend on.
Ilya Sutskever said it at NeurIPS: "We've achieved peak data. There's only one internet."
And that's just text.
The industry is shifting multimodal. Models now need real-world audio across hundreds of languages. Real images from real environments. Real video from natural conditions. That data doesn't live on the internet. It hasn't been collected yet.
The race for compute is solved by capital. The race for data has no equivalent solution.
You can't manufacture more internet. You can't synthesize what doesn't exist. And you can't scrape what was never captured.
This is what @hubxyz is building.
The data AI needs next doesn't exist online.
It exists in the real world.
And someone has to go collect it

Epoch AI@EpochAIResearch
Are we running out of data to train language models? State-of-the-art LLMs use datasets with tens of trillions of words, and use 2-3x more per year. Our new ICML paper estimates when we might exhaust all text data on the internet. 1/12
English
@Amino_Chain @imyoohealth I wonder if there exists any activities for your followers who want to contribute to Amino Chain? I’d like to be a part of your journey and an active member rather than a passive follower
English
“Data sharing is necessary to truly understand MG, which is ‘continuously elusive’ and has many different faces.” — Anita Longoria, Patient Advocate and founder of m.facebook.com/groups/1678996…
Help shape the future of MG care from home.
@AminoChain, in partnership with @imyoohealth , is launching the Myasthenia Gravis Repository Initiative and recruiting 60 U.S. participants (≈50 with MG, ≈10 comparison) for at home blood collection for whole genome sequencing and longitudinal immune profiling.
Built on privacy first technology, this study keeps participants directly connected to their samples and data, provides regular updates, and gives a clear window into how contributions are used.
Learn more and join: aminochain.io/mg-study
#MyastheniaGravis #MG #PatientCentricResearch #MolecularTools #RareDisease

English
Vay be kutlu airdrobun üstünden tam 3 yıl geçmiş. Üşüyoruz ed felten reis
Arbitrum@arbitrum
Wen? Now. 🧑🚀💙🧡
Türkçe
AI companies spend billions acquiring training data
5 billion people carry cameras and microphones in their pockets
Nobody connected the two
Until now
We built a new platform where anyone with a phone can collect real-world data for AI and earn from it.
A student in Manila recording how Tagalog sounds on a crowded bus.
A mother in Lagos photographing the objects on her kitchen table.
A woman in Bogotá capturing how afternoon light falls through her window.
Real images. Real audio. Real environments.
From 190+ countries.
Data that no AI company can buy from any provider today because it does not exist yet.
Hub already delivers structured training data to companies building the next generation of AI models.
Now we are opening the supply side to the world.
The people left behind by the economy just became its most valuable participants.
The first tasks are live.
The first contributors are already earning inside our Discord.
This is not a test. This is the beginning.
The full public launch is coming.

English

Çok güzel maç oldu ama sadece Fenerbahçe kaynaklı değildi Trabzonspor’u da tebrik ederim. Öte yandan böyle güzel bir galibet sonrası maçın oyuncusunu seçmekte zorlanıyorsak takım olarak doğru bir yere gidiyoruz demektir yani finansal tabirle tabana yayılmış sağlıklı bir yükseliş var
Türkçe

Herkese Selamlar 👋
Espresso ( @EspressoSys ) $ESP Token Allocations @magna_digital üzeriden Görünüyor 👀
🔗Link : app.magna.so
( Claim Sitesinin Altyapısınıda Magna Sağlıyor )
➜ Yoğunluktan site çöküyor, daha şimdiden böyleyse 😁
➜ Claim 02/12/2026 Gösteriyor - 12 Şubat Claim. 12PM UTC
➜ Türkiye için +3 Saat ekliyoruz. 15.00 12 Şubat.
➜ Bana 359 Tane vermiş, güncel pre market 0.08 x 359 : 28 Dolar.
🔗Pre Market : binance.com/en/futures/ESP…
Gelsin Bakalım Dürüm Paramız ⏳
Uzman@0xUzman
Herkese Selamlar 👋 Espresso ( @EspressoSys ) $ESP Airdrop'u için Dağıtım Method'unu ve Detayları Açıklamış 👇 Özet Geçelim : 🔗Claim Sayfası Yine Aynı Yerden : claim.espresso.foundation Holder Score & Anti-Sybil: Espresso Airdrop’un Asıl Mantığı Espresso ekibi şuradan yola çıktı: Klasik airdrop’lar çalışmıyor. Bunun sonucu da hep aynı: Botcular yüzlerce cüzdan açıyor Claim günü geliyor, alan anında satıyor Projenin uzun vadeli topluluğu zarar görüyor Adamlar bunu değiştirmek için Holder Score Getirmiş. Holder Score Nedir? Holder Score, bir cüzdanın geçmişte aldığı airdrop’larda nasıl davrandığına bakar. Şuna bakıyorlar: ➜ Aldığı token’ları hemen mi sattı? ➜ Tuttu mu? ➜ Stake etti mi? ➜ Hatta üstüne alım mı yaptı? İncelenen büyük airdrop’lardan bazıları: ➜ Arbitrum ➜ EigenLayer ➜ LayerZero ➜ Caldera Veriler çok net: ➜ Airdrop alan adreslerin yaklaşık %90’ı, token’ları kısa sürede elden çıkarıyor. Espresso diyor ki: “Biz bu %90’ı değil, kalan gerçek kullanıcıyı ödüllendirelim.” Kaç X’e Kadar Etki Ediyor? ➜ Holder Score ceza değil, bonus ➜ Düşük skor ➜ airdrop iptal olmaz ➜ Yüksek skor ➜ çarpanlı ödül 📈 Maksimum etki: ➜ Base allocation’a göre 170x’e kadar artış ( Manyak eder ha 2 Dolar tu 340 Dolar. ) Yani: ➜ Normalde 100 $ESP alacak bir adres ➜ Güçlü Holder Score ile 17.000 $ESP alabiliyor Tüm Yazı & Kaynak : @espressofndn/espresso-airdrop-rewarding-participation-and-long-term-conviction" target="_blank" rel="nofollow noopener">paragraph.com/@espressofndn/…
Gelsin Bakalım ⏳ Türkçe
Özetle Vitalik diyor ki;
Ethereum artık ölçeklenmeye başladı, L2 projeleri çok özel değişik bir geliştirme yapmadıkça bir işe yaramayacak. Orjinal vizyondan uzaklaşıyorlar.
Layer2’lerin fişini çekiyor çoğu silinecek piyasadan.
vitalik.eth@VitalikButerin
There have recently been some discussions on the ongoing role of L2s in the Ethereum ecosystem, especially in the face of two facts: * L2s' progress to stage 2 (and, secondarily, on interop) has been far slower and more difficult than originally expected * L1 itself is scaling, fees are very low, and gaslimits are projected to increase greatly in 2026 Both of these facts, for their own separate reasons, mean that the original vision of L2s and their role in Ethereum no longer makes sense, and we need a new path. First, let us recap the original vision. Ethereum needs to scale. The definition of "Ethereum scaling" is the existence of large quantities of block space that is backed by the full faith and credit of Ethereum - that is, block space where, if you do things (including with ETH) inside that block space, your activities are guaranteed to be valid, uncensored, unreverted, untouched, as long as Ethereum itself functions. If you create a 10000 TPS EVM where its connection to L1 is mediated by a multisig bridge, then you are not scaling Ethereum. This vision no longer makes sense. L1 does not need L2s to be "branded shards", because L1 is itself scaling. And L2s are not able or willing to satisfy the properties that a true "branded shard" would require. I've even seen at least one explicitly saying that they may never want to go beyond stage 1, not just for technical reasons around ZK-EVM safety, but also because their customers' regulatory needs require them to have ultimate control. This may be doing the right thing for your customers. But it should be obvious that if you are doing this, then you are not "scaling Ethereum" in the sense meant by the rollup-centric roadmap. But that's fine! it's fine because Ethereum itself is now scaling directly on L1, with large planned increases to its gas limit this year and the years ahead. We should stop thinking about L2s as literally being "branded shards" of Ethereum, with the social status and responsibilities that this entails. Instead, we can think of L2s as being a full spectrum, which includes both chains backed by the full faith and credit of Ethereum with various unique properties (eg. not just EVM), as well as a whole array of options at different levels of connection to Ethereum, that each person (or bot) is free to care about or not care about depending on their needs. What would I do today if I were an L2? * Identify a value add other than "scaling". Examples: (i) non-EVM specialized features/VMs around privacy, (ii) efficiency specialized around a particular application, (iii) truly extreme levels of scaling that even a greatly expanded L1 will not do, (iv) a totally different design for non-financial applications, eg. social, identity, AI, (v) ultra-low-latency and other sequencing properties, (vi) maybe built-in oracles or decentralized dispute resolution or other "non-computationally-verifiable" features * Be stage 1 at the minimum (otherwise you really are just a separate L1 with a bridge, and you should just call yourself that) if you're doing things with ETH or other ethereum-issued assets * Support maximum interoperability with Ethereum, though this will differ for each one (eg. what if you're not EVM, or even not financial?) From Ethereum's side, over the past few months I've become more convinced of the value of the native rollup precompile, particuarly once we have enshrined ZK-EVM proofs that we need anyway to scale L1. This is a precompile that verifies a ZK-EVM proof, and it's "part of Ethereum", so (i) it auto-upgrades along with Ethereum, and (ii) if the precompile has a bug, Ethereum will hard-fork to fix the bug. The native rollup precompile would make full, security-council-free, EVM verification accessible. We should spend much more time working out how to design it in such a way that if your L2 is "EVM plus other stuff", then the native rollup precompile would verify the EVM, and you only have to bring your own prover for the "other stuff" (eg. Stylus). This might involve a canonical way of exposing a lookup table between contract call inputs and outputs, and letting you provide your own values to the lookup table (that you would prove separately). This would make it easy to have safe, strong, trustless interoperability with Ethereum. It also enables synchronous composability (see: ethresear.ch/t/combining-pr… and ethresear.ch/t/synchronous-… ). And from there, it's each L2's choice exactly what they want to build. Don't just "extend L1", figure out something new to add. This of course means that some will add things that are trust-dependent, or backdoored, or otherwise insecure; this is unavoidable in a permissionless ecosystem where developers have freedom. Our job should make to make it clear to users what guarantees they have, and to build up the strongest Ethereum that we can.
Türkçe

Anadolu’nun kadim deve geleneği,
insan emeği, motifler ve dokular üzerinden yeniden anlatılıyor.
Her detayda sabır, her bakışta hikâye.
Created with ImagineArt 1.5 Pro
#imagineart15prochallenge
#ImagineArt15Pro
#TexturesAndDetails
#Photorealism
#AIArt
@ImagineArt_X @imagineart_creo

Türkçe
GMMM ☀️
Profil resmini bayadır değiştirmiyordum.
Eskiler bilir yeniler bu ne diyor :D

Türkçe


🎄 Merry Christmas from Hub
Thank you to our community, backers and partners for contributing and helping us raise the bar this year.
Now it’s time to take a break to enjoy the moment. Then we keep building.
Bonus: reply with your most creative Hub Christmas visual.
5 winners get 5,000 IQ Points each

English



ZAMATHON (FİNAL)
Kedimiz yetişmişti ve ana karakterimizin sadece zihniyle oluşturduğu anılar ekranda görünüyordu. Kendisi asla hareket edemeyen ve yalnızca zihniyle yaşayabilen birisi. Sağdaki @randhindi karakterimiz yıllardır anıların oluşturulabilmesi için kodları gizlice yönetip karakterimizle kablolarla bağlantılar kurarak yazmıştı. Her ne kadar konuşamasa da çocuğunun bu anları görebilmesine ve hayallerinin kedisiyle birlikte Zamathon kapanışında güzel bir kapıdan geçebildiğini, @zama_fhe'ye ulaşıldığını görmesinden dolayı çok memnundu. Kapı açılmıştı, geçmeden önce içindekileri çocuğu okumuştu:
Zihnim, bir ışık tüneli gibi Zama Kapısı’ndan süzülüp gidecek. Bedenimle değil, düşüncelerimle yaşadım. Şimdi hayallerimi kapıdan yolluyorum. Gökyüzüne iyi dileklerimi senin için yolluyorum. Her şifreli satırda mutluluk gözyaşlarımla unutulmamaya gidiyorum. Zamathon'un sonsuz kod denizinden, Zama'nın ışık süzmesine gidiyorum. Kapıyı zihnimle, yüreğimle, direnişimle.. Geçiyorum ! Zamathon'un son nefesi, ilk nefesim olacak. Işık sonsuza dek yanacak.
Geçiş için kodu Rand yazmıştı
Kapıya doğru banttan ilerleyen ana karakterimizin hayali ve kedisi geçişini gerçekleştirdi. Direnişini devam ettirmeye, sonsuzluğa gittiler !
#Zamathon #ZamaCreatorProgram


Nikelenjelo@nikelenjeloo
Zamathon Final Günü İlk Partından Günaydın ☀️ Evet önceki paylaşımımızda kedimizin @zama_fhe tasmasından yansıttığı ışık süzmesinde eksik vardı. Ana karakterimiz orada değildi, olmayı isterdi ama yapamıyordu. Oblomov ve Cheryl arasında yaşam normalini en çok isteyen de kendisiydi. Gitar tellerinden çıkan melodiler Cem Karaca "Bu Son Olsun" şarkısıydı ve herkes son sesiyle eşlik ediyordu. Işık süzmesi artmaya başladı. Arttı arttı.. Kedimizin içinden demek istedikleri daha da yoğun şekilde dışarıya çıktı: Bekle… Bir pati izi daha bırakmalıyım. Sen gittin ama ben hâlâ buradayım. Ateşin başında, şarkının ortasında Tasma parlamıştı ve uzaktan kodlar yazılmaya başlamıştı: Şifreli kitap açılmıştı. Açılan portaldan sonra son gücüyle koşmaya başlamıştı. Melodiler, hisler hepsi taşmıştı. Ateş sönüyor, kitap kapanmaya başlamışken kedimiz de geçecekti. Geçtiğinde son kez "Nereye gidiyorum ? Ne yapıyorum bilmiyorum ama senin kodların, direnişin tüm tüylerimde ve kuyruğumda sadece senin adını miyavlayacağım yerde olacak". dedi ve heyecanla içeriye adım attı. #ZamaCreatorProgram #Zamathon
Türkçe


The Cult rises with the tide on Odyssey. 🔮
The @hubxyz ship is docking among all Sailors, full of XP, brand-new quests, quizzes, and rewards for all AI-savvy explorers! ✨
Learn about next-gen data infrastructure, and join exclusive giveaways, all while exploring Odyssey ⛵️

English