
Tay
67 posts

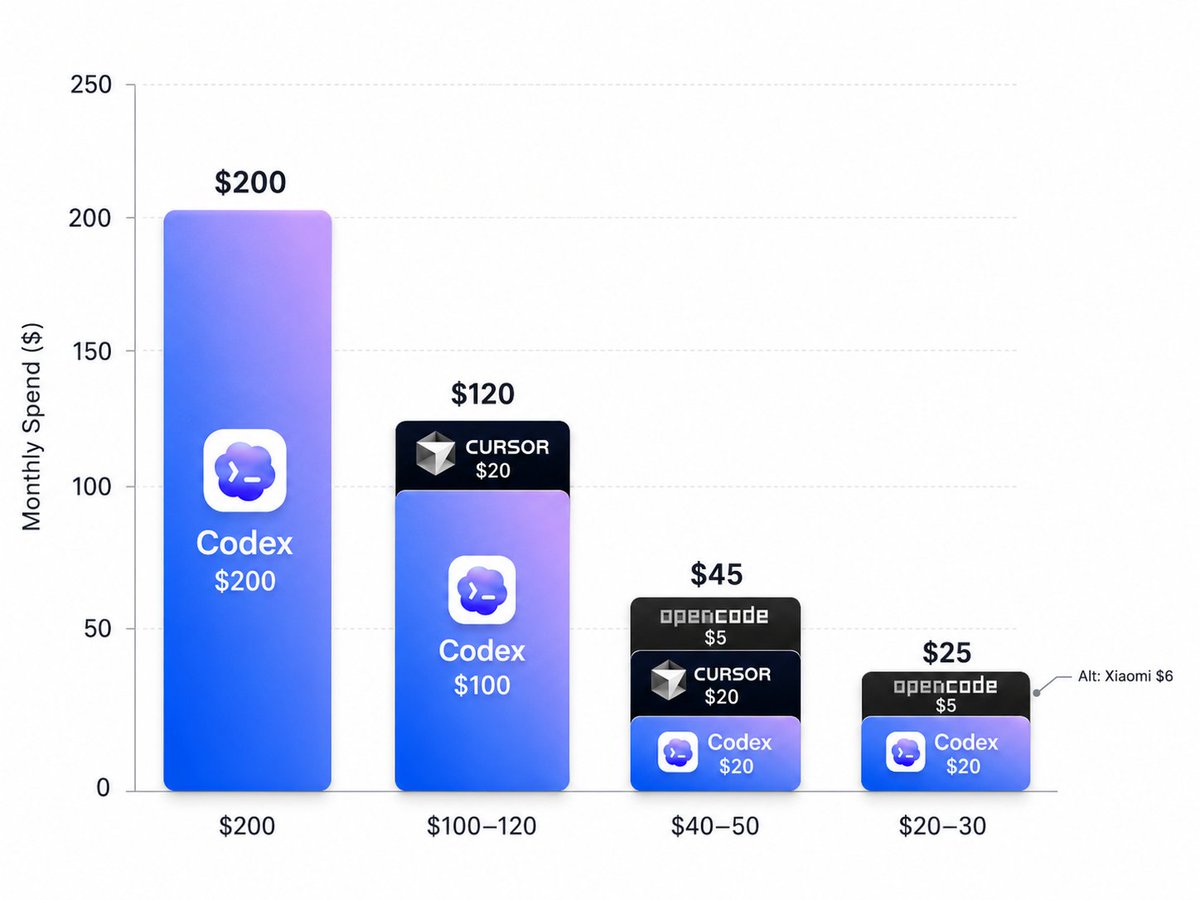
Here's the best coding plan for your specific budget
200$
Codex 200$
100-120$
Codex 100$ + Cursor 20$
40-50$
Codex 20$ + Cursor 20$ + Opencode 5$
20-30$
Codex 20$ + Opencode 5$ /Xiaomi 6$
Codex is a must've for any serious coding
while all other are swappable and cursor has become very valuable recently due to composer 2.5
English


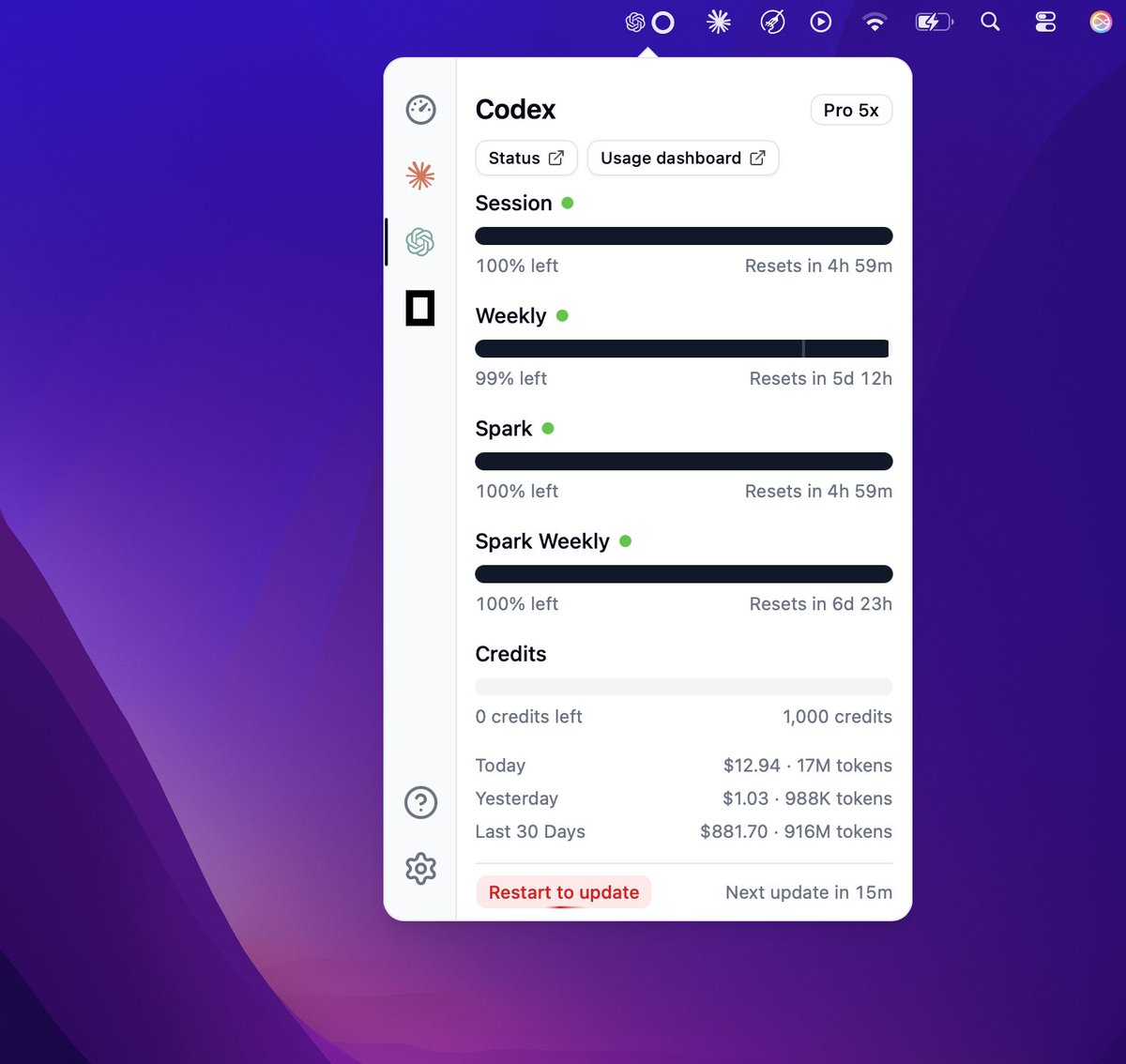


New record : in 16 min quota reached 😂❤️
Soso fun ✨@Soso_fun_yt
Google, autocompacting is SO aggressive, it does autocompaction every 1-2 minutes, I'm working in a large codebase, and the problem is that @antigravity is too restricted on tokens, can someone at Google look into this to improve it ? The chat autocompaction after 7500 tokens completely breaks the session context, please fix this, otherwise, it forces me to use Codex, even though I really love Antigravity for its simplicity and the Gemini models ! :D @_mohansolo, @kevinhou22, @OfficialLoganK, @DynamicWebPaige
English

@rezoundous @Mich924851311 I think OpenAI have distilled GPT 5.5 for distribution, because model always acts weirdly, and at ESP32 tests i put it trough, it looses to kimi instantly
English



I switched Gemini 3.5 Flash to medium and I'm not looking back.
English

the problem with these benchmarks is that they might be on a very specific sets of tasks and not representative of the reality (a bit like political polls)
Composer 2.5 IS NEVER BETTER THAN Opus 4.7 med
NOT EVEN CLOSE GUYS
Artificial Analysis@ArtificialAnlys
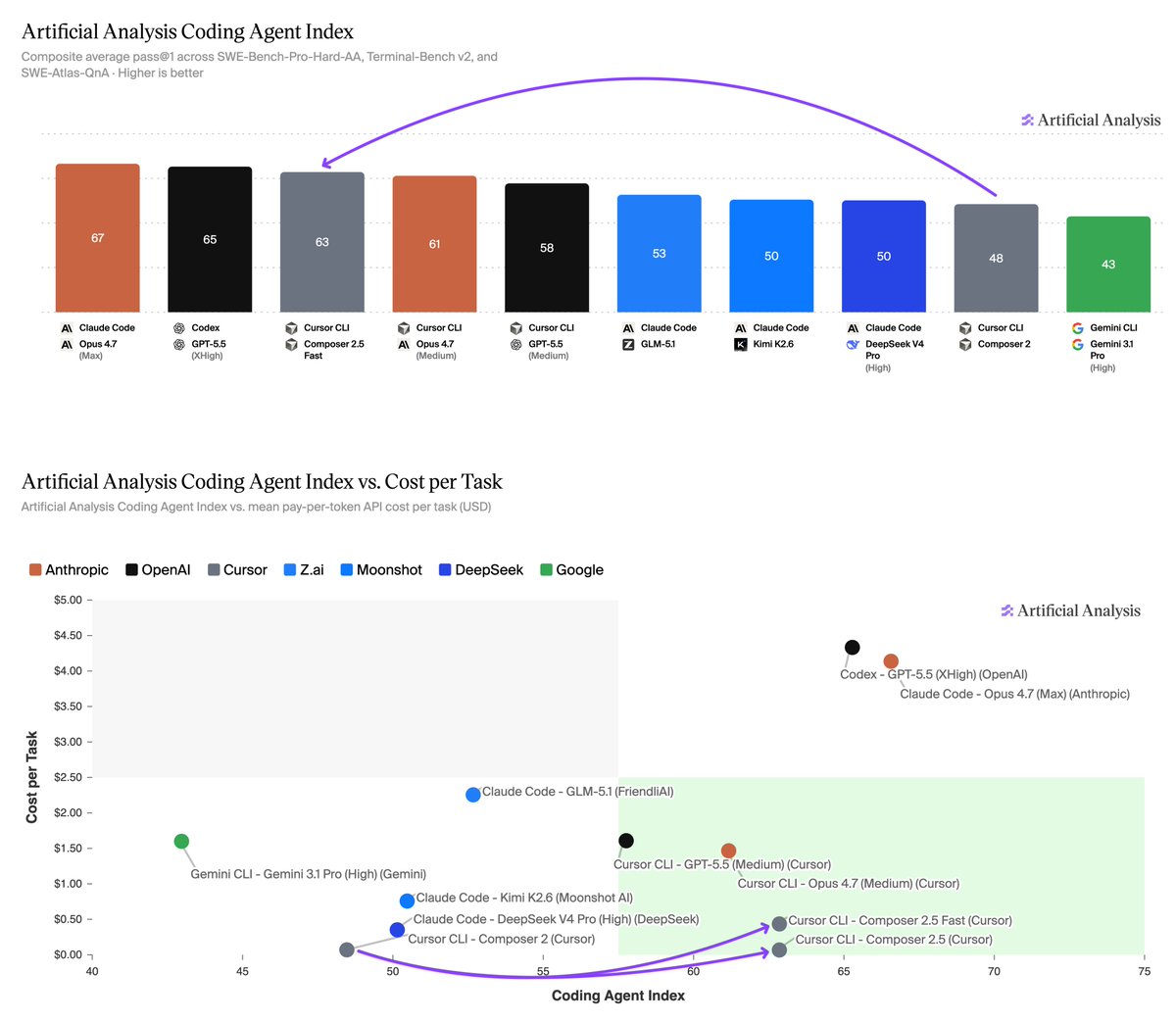
Cursor's new Composer 2.5 takes third on the Artificial Analysis Coding Agent Index and is ~10-60x lower cost than the higher-effort Opus 4.7 and GPT-5.5 variants above it. This release puts Composer among the leading coding agent models, something that wasn’t clear for past releases @cursor_ai has released Composer 2.5, the latest model in its Composer line. Composer 2.5 scored 62 on our Coding Agent Index, a 14 point gain over Composer 2 (48). This puts it in third place of our tested agents, behind only Claude Opus 4.7 (max) in Claude Code (66) and GPT-5.5 (xhigh reasoning) in Codex (65). These cost $4.10 and $4.82 per task respectively, ~10x the cost of Composer 2.5 Fast ($0.44) and ~60x the cost of Composer 2.5 standard ($0.07). Key results for Composer 2.5 in Cursor CLI: ➤ Cost-quality Pareto frontier: At $0.07 (standard) and $0.44 (Fast) per task, Composer 2.5 is cheaper than every other agent scoring above 60 on the Index. Medium-effort peers cost $1.24–$2.21 per task; higher-effort variants land 3-4 points above at $4.10–$4.82 ➤ Per-benchmark gains vs Composer 2: +35 points on SWE-Bench-Pro-Hard-AA (12% → 47%), +2 points on Terminal-Bench v2 (64% → 66%), and +3 points on SWE-Atlas-QnA (69% → 72%). At 47%, Composer 2.5's score on SWE-Bench-Pro-Hard-AA is comparable to Claude Opus 4.7 (max) in Claude Code ➤ Among the fastest coding agents: Composer 2.5 Fast runs at an average wall time of 6.7 minutes per task, the third-fastest agent on the Artificial Analysis Coding Agent Index, behind only Claude Opus 4.7 (medium) in Claude Code (5.8m) and GPT-5.5 (medium) in Cursor CLI (6.2m) ➤ Fast mode enables better responsiveness at 6x pricing: Fast runs 30% faster than standard Composer 2.5, but is ~6x the cost per task ($0.44 vs $0.07). Token pricing is 6x higher for Fast: $3.00/$15.00 vs $0.50/$2.50 per million input/output tokens Model details: ➤ Base model: Continued training on @Kimi_Moonshot's open weights Kimi K2.5 as with Composer 2, with Cursor reporting ~85% of total compute from its own additional training and reinforcement learning ➤ Pricing: $0.50/$2.50 per million input/output tokens for the standard variant; $3.00/$15.00 for the Fast variant (the default in Cursor) ➤ Available exclusively in Cursor: both Cursor IDE and Cursor CLI, an externally accessible API is not available Congratulations @cursor_ai and @mntruell on the impressive release!
English

@uwunetes @cursor_ai I got you, sending credits your way! Check your DM.
English


more expensive than GPT-5.5 xhigh btw

Logan Kilpatrick@OfficialLoganK
Gemini 3.5 Flash ranks #1 on the APEX-Agents-AA benchmark, outperforming much larger models a whole size above it.
English

Alternate read: "usage is lower than expected so we have some extra compute"
Varun Mohan@_mohansolo
An update: we’re 3xing the rate limits for Gemini models across all paid tiers in Antigravity and resetting everyone’s Gemini quota for the week. We understand some people hit their rate limits quickly and wanted to respond fast. Lots more to come and enjoy building!
English

An update: we’re 3xing the rate limits for Gemini models across all paid tiers in Antigravity and resetting everyone’s Gemini quota for the week.
We understand some people hit their rate limits quickly and wanted to respond fast. Lots more to come and enjoy building!
English

WTF is Antigravity 2.0?
I updated expecting an IDE upgrade.
Instead I got… an Agent Manager dashboard.
No terminal.
No source control.
No editor.
I can’t even run a simple dotnet run.
Did we really go from “developer tools” to “just prompt the AI and pray”?
Feels less like an IDE and more like a glorified chat wrapper.
Am I missing some hidden developer mode, or is the new vision literally “stop typing, let the agent do everything”?
English

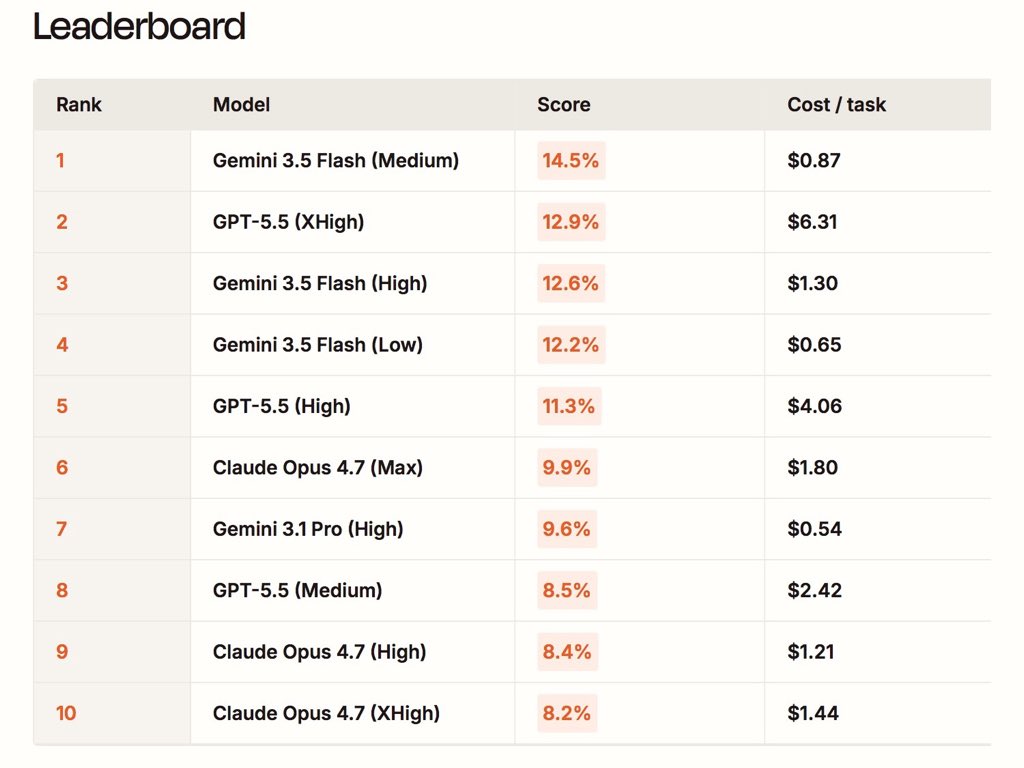
Gemini 3.5 Flash ranks #1 on Automation Bench (from Zapier), beating every other frontier model at a much lower cost
English
Holy moly, I slept on Cursor. Let's go, Cursor!!
Artificial Analysis@ArtificialAnlys
Cursor's new Composer 2.5 takes third on the Artificial Analysis Coding Agent Index and is ~10-60x lower cost than the higher-effort Opus 4.7 and GPT-5.5 variants above it. This release puts Composer among the leading coding agent models, something that wasn’t clear for past releases @cursor_ai has released Composer 2.5, the latest model in its Composer line. Composer 2.5 scored 62 on our Coding Agent Index, a 14 point gain over Composer 2 (48). This puts it in third place of our tested agents, behind only Claude Opus 4.7 (max) in Claude Code (66) and GPT-5.5 (xhigh reasoning) in Codex (65). These cost $4.10 and $4.82 per task respectively, ~10x the cost of Composer 2.5 Fast ($0.44) and ~60x the cost of Composer 2.5 standard ($0.07). Key results for Composer 2.5 in Cursor CLI: ➤ Cost-quality Pareto frontier: At $0.07 (standard) and $0.44 (Fast) per task, Composer 2.5 is cheaper than every other agent scoring above 60 on the Index. Medium-effort peers cost $1.24–$2.21 per task; higher-effort variants land 3-4 points above at $4.10–$4.82 ➤ Per-benchmark gains vs Composer 2: +35 points on SWE-Bench-Pro-Hard-AA (12% → 47%), +2 points on Terminal-Bench v2 (64% → 66%), and +3 points on SWE-Atlas-QnA (69% → 72%). At 47%, Composer 2.5's score on SWE-Bench-Pro-Hard-AA is comparable to Claude Opus 4.7 (max) in Claude Code ➤ Among the fastest coding agents: Composer 2.5 Fast runs at an average wall time of 6.7 minutes per task, the third-fastest agent on the Artificial Analysis Coding Agent Index, behind only Claude Opus 4.7 (medium) in Claude Code (5.8m) and GPT-5.5 (medium) in Cursor CLI (6.2m) ➤ Fast mode enables better responsiveness at 6x pricing: Fast runs 30% faster than standard Composer 2.5, but is ~6x the cost per task ($0.44 vs $0.07). Token pricing is 6x higher for Fast: $3.00/$15.00 vs $0.50/$2.50 per million input/output tokens Model details: ➤ Base model: Continued training on @Kimi_Moonshot's open weights Kimi K2.5 as with Composer 2, with Cursor reporting ~85% of total compute from its own additional training and reinforcement learning ➤ Pricing: $0.50/$2.50 per million input/output tokens for the standard variant; $3.00/$15.00 for the Fast variant (the default in Cursor) ➤ Available exclusively in Cursor: both Cursor IDE and Cursor CLI, an externally accessible API is not available Congratulations @cursor_ai and @mntruell on the impressive release!
English
Tay retweetledi

Cursor's new Composer 2.5 takes third on the Artificial Analysis Coding Agent Index and is ~10-60x lower cost than the higher-effort Opus 4.7 and GPT-5.5 variants above it. This release puts Composer among the leading coding agent models, something that wasn’t clear for past releases
@cursor_ai has released Composer 2.5, the latest model in its Composer line. Composer 2.5 scored 62 on our Coding Agent Index, a 14 point gain over Composer 2 (48). This puts it in third place of our tested agents, behind only Claude Opus 4.7 (max) in Claude Code (66) and GPT-5.5 (xhigh reasoning) in Codex (65). These cost $4.10 and $4.82 per task respectively, ~10x the cost of Composer 2.5 Fast ($0.44) and ~60x the cost of Composer 2.5 standard ($0.07).
Key results for Composer 2.5 in Cursor CLI:
➤ Cost-quality Pareto frontier: At $0.07 (standard) and $0.44 (Fast) per task, Composer 2.5 is cheaper than every other agent scoring above 60 on the Index. Medium-effort peers cost $1.24–$2.21 per task; higher-effort variants land 3-4 points above at $4.10–$4.82
➤ Per-benchmark gains vs Composer 2: +35 points on SWE-Bench-Pro-Hard-AA (12% → 47%), +2 points on Terminal-Bench v2 (64% → 66%), and +3 points on SWE-Atlas-QnA (69% → 72%). At 47%, Composer 2.5's score on SWE-Bench-Pro-Hard-AA is comparable to Claude Opus 4.7 (max) in Claude Code
➤ Among the fastest coding agents: Composer 2.5 Fast runs at an average wall time of 6.7 minutes per task, the third-fastest agent on the Artificial Analysis Coding Agent Index, behind only Claude Opus 4.7 (medium) in Claude Code (5.8m) and GPT-5.5 (medium) in Cursor CLI (6.2m)
➤ Fast mode enables better responsiveness at 6x pricing: Fast runs 30% faster than standard Composer 2.5, but is ~6x the cost per task ($0.44 vs $0.07). Token pricing is 6x higher for Fast: $3.00/$15.00 vs $0.50/$2.50 per million input/output tokens
Model details:
➤ Base model: Continued training on @Kimi_Moonshot's open weights Kimi K2.5 as with Composer 2, with Cursor reporting ~85% of total compute from its own additional training and reinforcement learning
➤ Pricing: $0.50/$2.50 per million input/output tokens for the standard variant; $3.00/$15.00 for the Fast variant (the default in Cursor)
➤ Available exclusively in Cursor: both Cursor IDE and Cursor CLI, an externally accessible API is not available
Congratulations @cursor_ai and @mntruell on the impressive release!
English