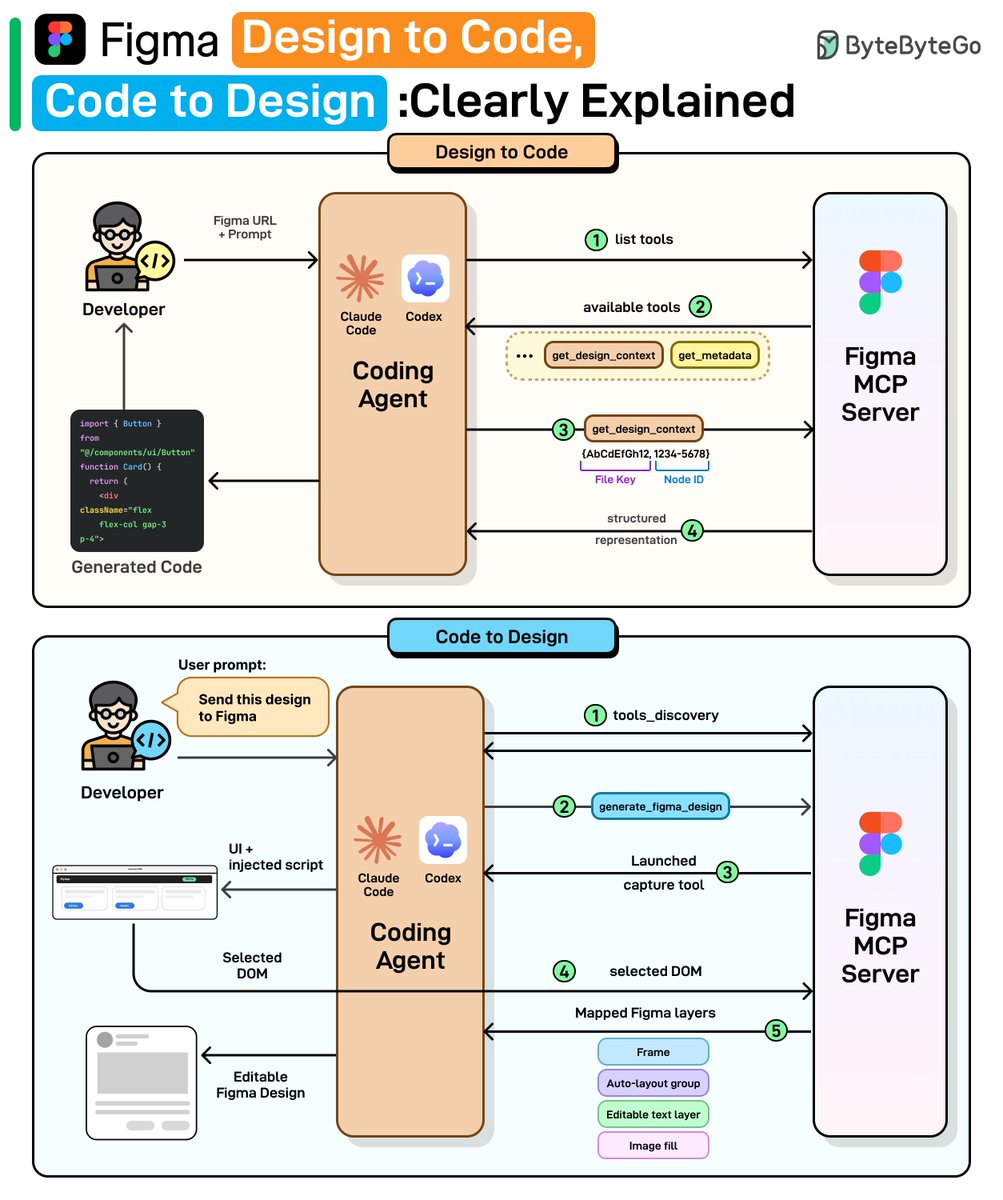
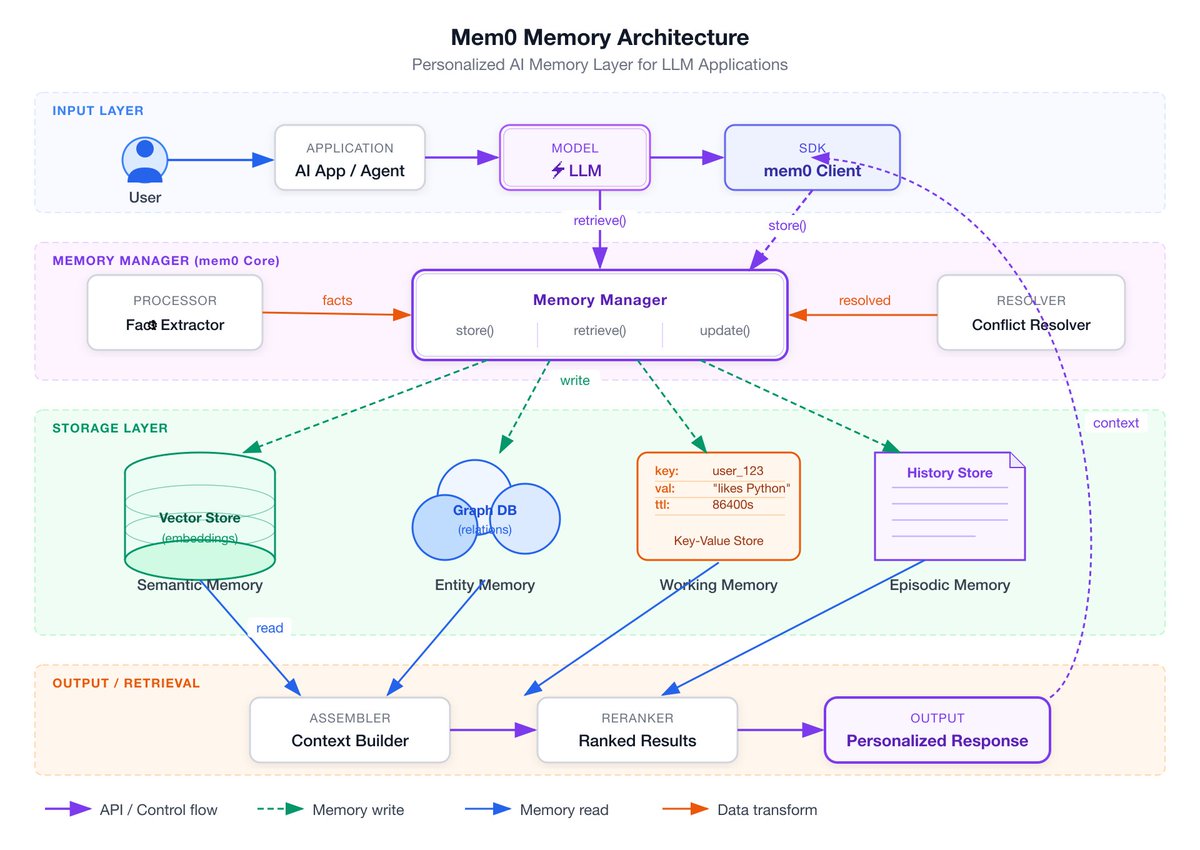
Sabitlenmiş Tweet

写技术文章最烦的事之一:画图。
脑子里很清楚的架构,落到 draw.io 上总是对不齐、颜色难看、导出模糊。
所以我做了 fireworks-tech-graph,一个专门生成技术图的 Claude Code Skill。
o…
用法很简单——
t
「画一张 Multi-Agent 协作图:Orchestrator 调度 3 个
SubAgent,分别负责搜索、计算和代码执行,最后汇聚到 Aggregator 输出结果,玻璃态风格」
然后它会:
① 识别图类型 → Agent 架构图
② 分配语义形状 → Orchestrator 用六边形,Agent 用六边形,存储用圆柱体
③ 用语义颜色编码箭头 → 蓝色主流程、橙色控制流、绿色读写
④ 自动导出 SVG + 1920px PNG
整个过程不需要写 DSL,不需要打开任何工具,一句话描述,图就出来了。
o…
目前支持 8 种图类型、5 种视觉风格,AI/Agent 领域的常见 Pattern
全部内置(RAG、Mem0、Agentic Search、Multi-Agent、Tool Call 等)。
开源,欢迎 star 和 fork 👇
github.com/yizhiyanhua-ai…
中文