Antigravity just cooked every bloated AI interface.
The Antigravity CLI dropped today. It brings the full agentic power of Antigravity 2.0 - multi-step reasoning, tool calling, and multi-file editing - directly to your terminal.
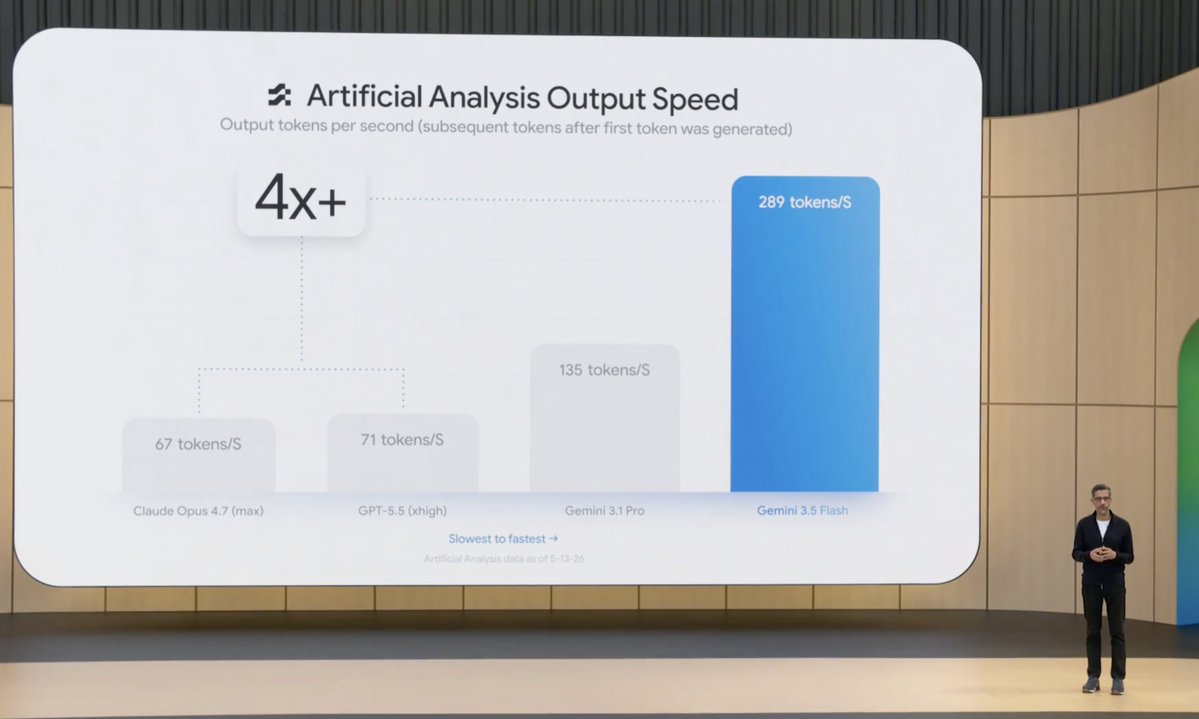
It’s written in Go, ultra-snappy, and runs on Gemini 3.5 Flash.
What it actually does:
→ Delegates parallel background tasks to autonomous subagents
→ Executes complex multi-file code editing with zero keyboard lag
→ Authenticates remote SSH sessions silently via keyring sign-in
→ Syncs settings and core preferences instantly with the desktop app
It uses the exact same core agent harness and app server as the flagship product. You get elite orchestration and fast-path approvals without ever lifting your hands off the keyboard.
Heavy desktop software isn't the tax for agentic power anymore. The terminal is.
Want the full installation blueprint + SSH setup guide? Like + comment "CLI" and I’ll DM it to you for free (must be following).

English