Peter Szemraj retweetledi

Peter Szemraj
184 posts


@ten3br1s
research interests: metallic intuition


Fast Byte Latent Transformer is accepted to ICML 2026! ⚡🥪 Byte-level LMs promise to free us from subword tokenizers, but decoding one byte at a time is super slow. We make BLT generation more efficient with BLT-D: text diffusion for parallel byte decoding. 1/

1/ SSMs struggle on recall benchmarks due to their fixed-size state. But are current models actually storing context “wisely”? Introducing Raven 🐦⬛, the first SSM with selective memory allocation! Raven achieves SOTA performance on recall-heavy tasks with the highest length generalization, extending up to 16× beyond its training sequence length. Raven is a strict upgrade over SWA in the way it stores past context! This is the most elegant model I’ve been involved in designing so far shoutout to @avivbick and @_albertgu for their trust and amazing work! Check out how Raven bridges between SWA and SSM👇

We’ve agreed to a partnership with @SpaceX that will substantially increase our compute capacity. This, along with our other recent compute deals, means that we’ve been able to increase our usage limits for Claude Code and the Claude API.
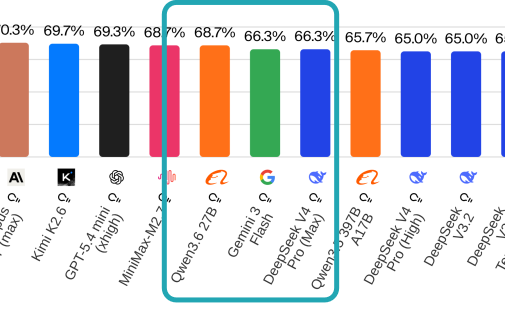
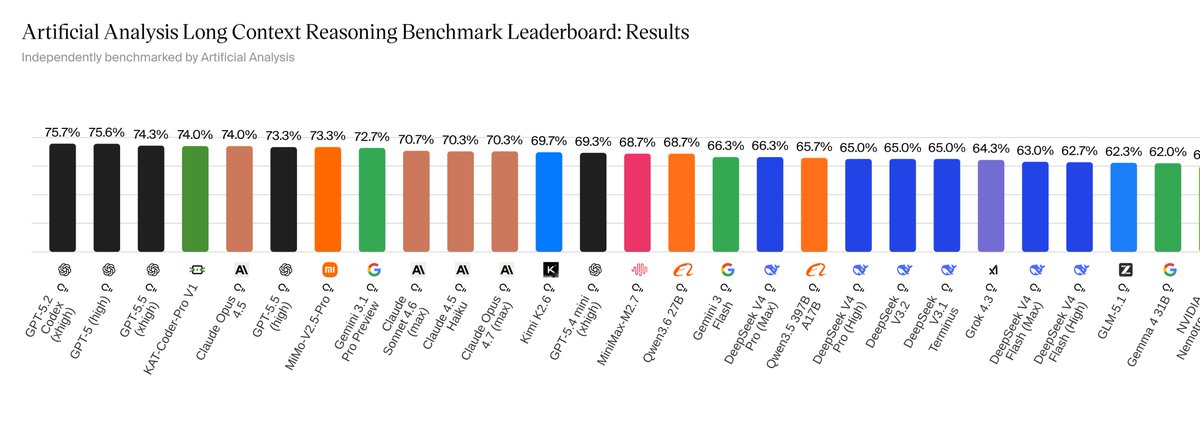
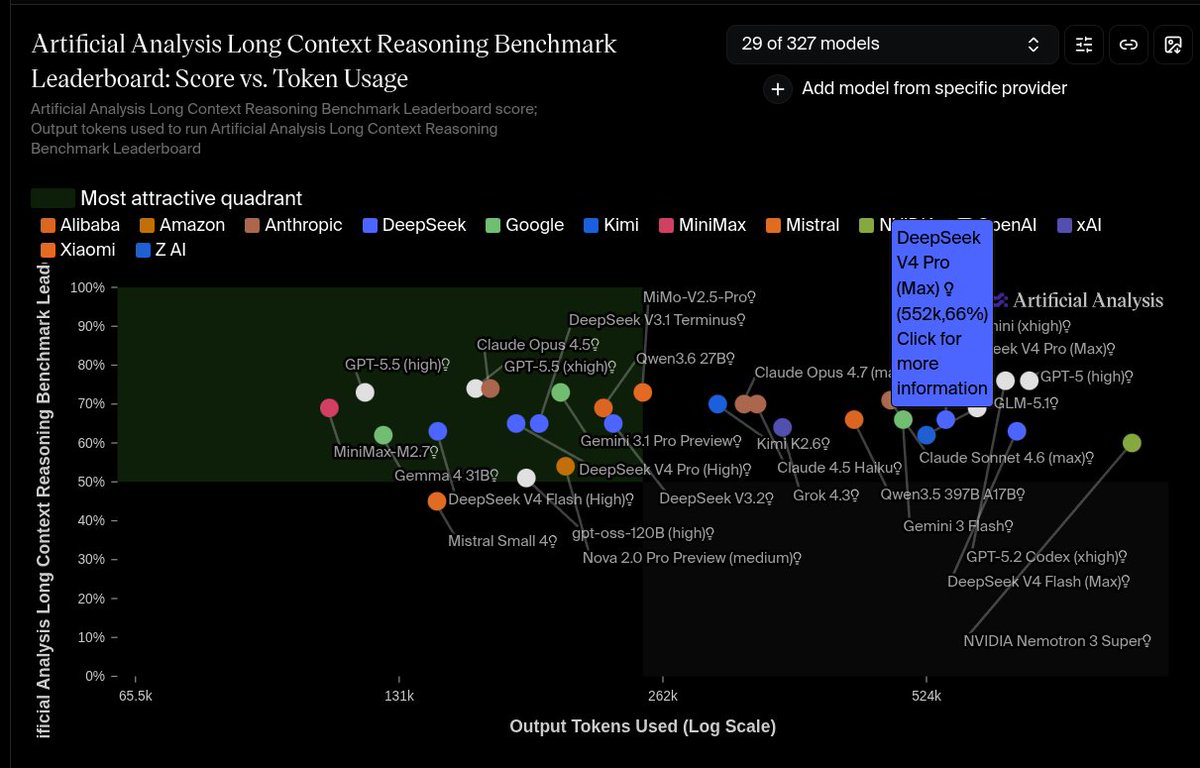



🚀 Meet Qwen3.6-27B, our latest dense, open-source model, packing flagship-level coding power! Yes, 27B, and Qwen3.6-27B punches way above its weight. 👇 What's new: 🧠 Outstanding agentic coding — surpasses Qwen3.5-397B-A17B across all major coding benchmarks 💡 Strong reasoning across text & multimodal tasks 🔄 Supports thinking & non-thinking modes ✅ Apache 2.0 — fully open, fully yours Smaller model. Bigger results. Community's favorite. ❤️ We can't wait to see what you build with Qwen3.6-27B! 👀 🔗👇 Blog: qwen.ai/blog?id=qwen3.… Qwen Studio: chat.qwen.ai/?models=qwen3.… Github: github.com/QwenLM/Qwen3.6 Hugging Face: huggingface.co/Qwen/Qwen3.6-2… huggingface.co/Qwen/Qwen3.6-2… ModelScope: modelscope.cn/models/Qwen/Qw… modelscope.cn/models/Qwen/Qw…

> been paying $200/month for cloud AI APIs > laptop: M2 MacBook, 16GB RAM > tried running models locally, garbage quality after 4K tokens > read this TurboQuant breakdown on Tuesday > applied 3-bit KV cache compression > same MacBook now runs 100K token conversations > quality: identical to cloud > cancelled all API subscriptions Wednesday > it's been 3 days > saved $200/month forever > with a free algorithm from a free paper > my MacBook didn't change. the math did

You can now enable Claude to use your computer to complete tasks. It opens your apps, navigates your browser, fills in spreadsheets—anything you'd do sitting at your desk. Research preview in Claude Cowork and Claude Code, macOS only.

I packaged up the "autoresearch" project into a new self-contained minimal repo if people would like to play over the weekend. It's basically nanochat LLM training core stripped down to a single-GPU, one file version of ~630 lines of code, then: - the human iterates on the prompt (.md) - the AI agent iterates on the training code (.py) The goal is to engineer your agents to make the fastest research progress indefinitely and without any of your own involvement. In the image, every dot is a complete LLM training run that lasts exactly 5 minutes. The agent works in an autonomous loop on a git feature branch and accumulates git commits to the training script as it finds better settings (of lower validation loss by the end) of the neural network architecture, the optimizer, all the hyperparameters, etc. You can imagine comparing the research progress of different prompts, different agents, etc. github.com/karpathy/autor… Part code, part sci-fi, and a pinch of psychosis :)