BlackCat
39.4K posts




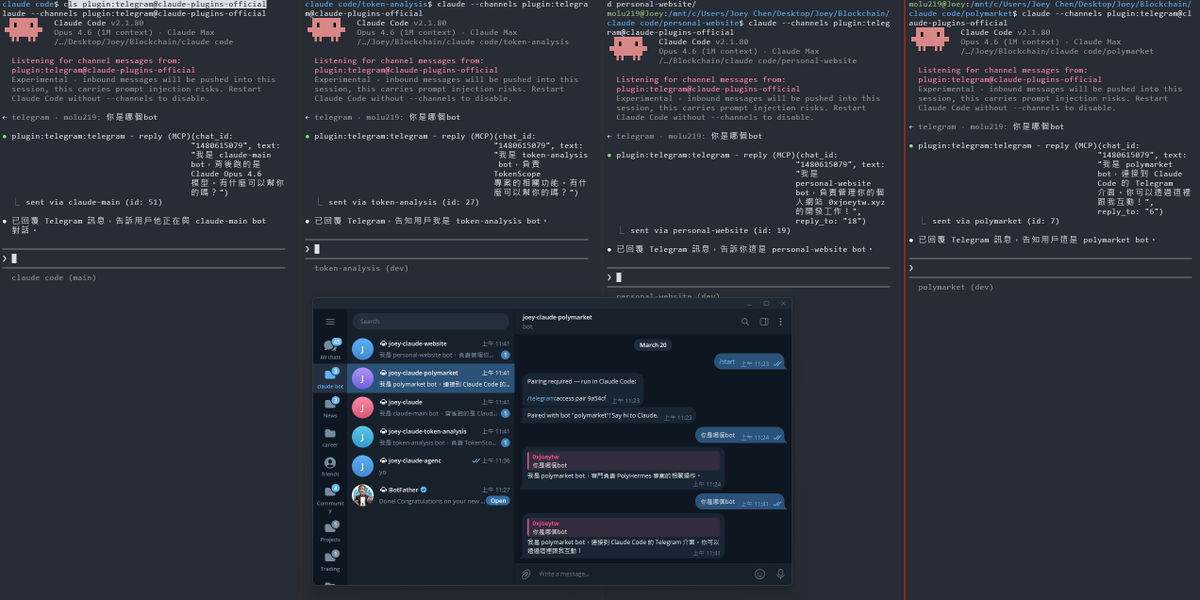
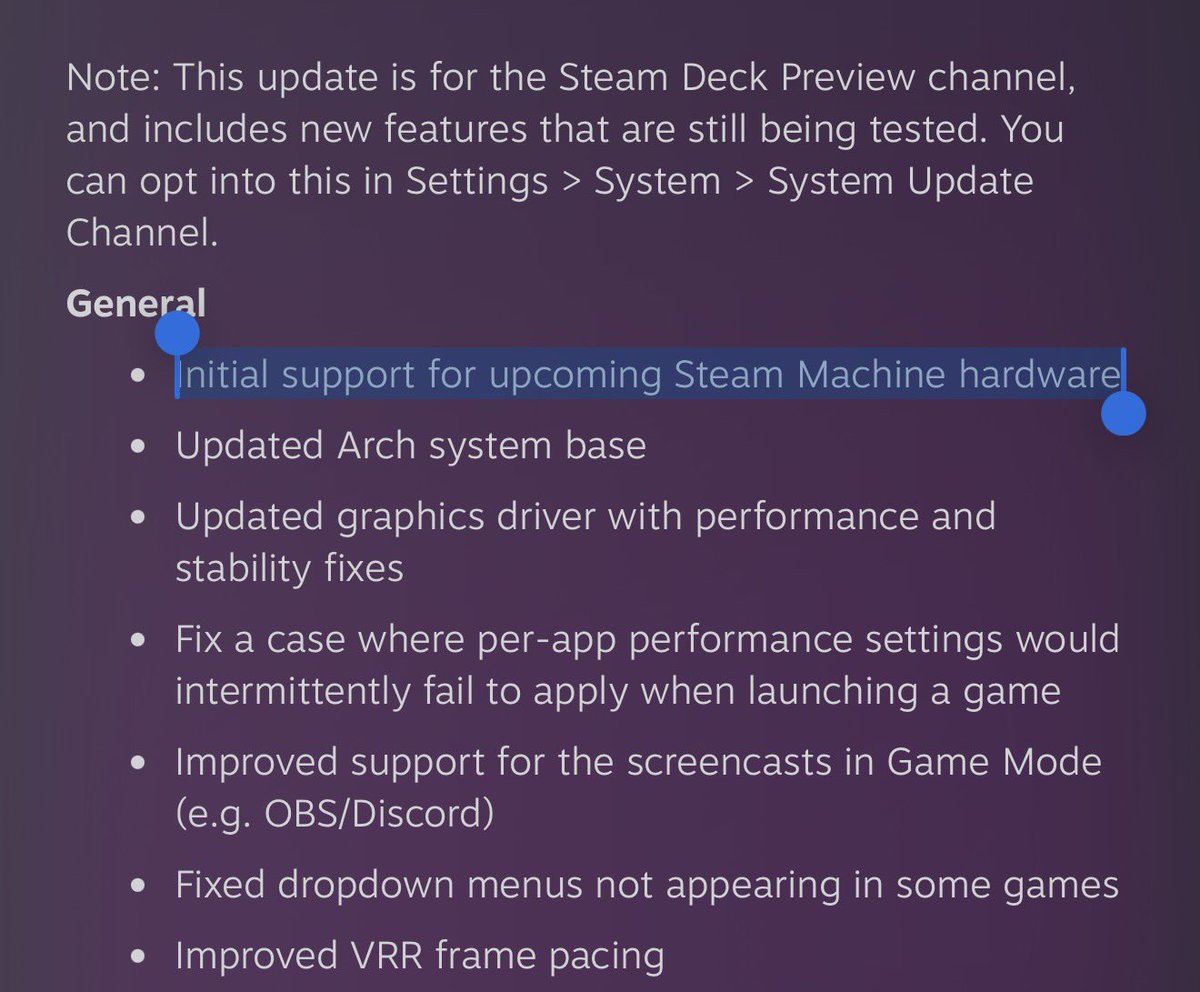
We just released Claude Code channels, which allows you to control your Claude Code session through select MCPs, starting with Telegram and Discord. Use this to message Claude Code directly from your phone.


Introducing LiteParse - the best model-free document parsing tool for AI agents 💫 ✅ It’s completely open-source and free. ✅ No GPU required, will process ~500 pages in 2 seconds on commodity hardware ✅ More accurate than PyPDF, PyMuPDF, Markdown. Also way more readable - see below for how we parse tables!! ✅ Supports 50+ file formats, from PDFs to Office docs to images ✅ Is designed to plug and play with Claude Code, OpenClaw, and any other AI agent with a one-line skills install. Supports native screenshotting capabilities. We spent years building up LlamaParse by orchestrating state-of-the-art VLMs over the most complex documents. Along the way we realized that you could get quite far on most docs through fast and cheap text parsing. Take a look at the video below. For really complex tables within PDFs, we output them in a spatial grid that’s both AI and human-interpretable. Any other free/light parser light PyPDF will destroy the representation of this table and output a sequential list. This is not a replacement for a VLM-based OCR tool (it requires 0 GPUs and doesn’t use models), but it is shocking how good it is to parse most documents. Huge shoutout to @LoganMarkewich and @itsclelia for all the work here. Come check it out: llamaindex.ai/blog/liteparse… Repo: github.com/run-llama/lite…

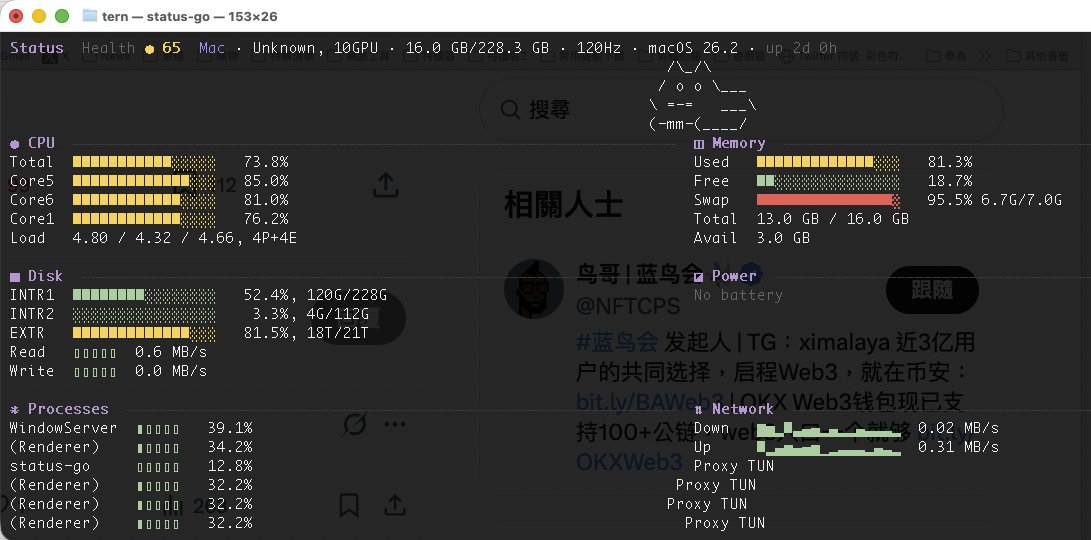







IF YOU'RE ON OPENCLAW DO THIS NOW: I just sped up my OpenClaw by 95% with a single prompt Over the past week my claw has been unbelievably slow. Turns out the output of EVERY cron job gets loaded into context Months of cron outputs sent with every message Do this prompt now: "Check how many session files are in ~/.openclaw/agents/main/sessions/ and how big sessions.json is. If there are thousands of old cron session files bloating it, delete all the old .jsonl files except the main session, then rebuild sessions.json to only reference sessions that still exist on disk." This will delete all the session data around your cron outputs. If you do a ton of cron jobs, this is a tremendous amount of bloat that does not need to be loaded into context and is MAJORLY slowing down your Openclaw If you for some reason want to keep some of this cron session data in memory, then don't have your openclaw delete ALL of them. But for me, I have all the outputs automatically save to a Convex database anyway, so there was no reason to keep it all in context. Instantly sped up my OpenClaw from unusable to lightning quick



輝達回應眾議院調查: 我們完全依政府規定行事,沒有偷偷賣給中國。 新加坡營收只是帳單地址,貨是寄去美國和台灣的,不是中國。 政府要我們停,我們一定停。 弱弱的問… 那個美國和台灣客戶是否叫美X微?



I just launched /office-hours skill with gstack. Working on a new idea? GStack will help you think about it the way we do at YC. (It's only a 10% strength version of what a real YC partner can do for you, but I assure you that is quite powerful as it is.)
Anthropic 剛在 Claude Code 上推出了一個叫 Channels 的新功能(研究預覽階段),可以從 Telegram 和 Discord 直接傳訊息給正在跑的 Claude Code 工作階段,Claude 會在專案脈絡裡讀取訊息、執行任務,然後透過同一個頻道回覆。 Claude Code 負責人 Boris Cherny 的說法是「message Claude Code directly from your phone」,用手機就能指揮電腦上跑的 Claude Code。 技術上,Channel 是一個 MCP 伺服器,以插件形式安裝,用 Bun 執行。Telegram 版的流程是用 BotFather 建一個 bot,裝插件,設定 token,用 --channels 旗標啟動 Claude Code,bot 就會開始輪詢訊息。收到的訊息以 channel 事件注入工作階段,安全機制靠配對碼和發送者白名單,只有明確授權的帳號才能推送。 過去兩個月,Claude Code 連續推了三個功能,Remote Control(2 月,從手機看終端畫面和操控)、Scheduled Tasks(排程任務,最多 50 個同時跑,三天自動過期)、現在是 Channels(外部事件推送)。三個功能拼起來,Claude Code 的定位正在從「終端機裡的 AI 助手」變成「不需要開發者在場就能運作的自主開發 agent」。 CI 跑完自動推結果進來讓 Claude 修 bug,監控系統告警直接觸發 Claude 排查,Discord 上的團隊討論即時同步到開發環境,這些場景現在都能串起來。而且因為底層用的是 MCP 插件架構,社群可以自己寫 Slack、WhatsApp 或任何平台的 connector,不需要等 Anthropic 官方支援。 熟悉 OpenClaw(龍蝦 🦞)的人看到 Channels 應該會覺得很眼熟,用通訊軟體遠端指揮 AI agent 的概念,OpenClaw 去年就做了,支援超過 30 個平台和 5,700 多個社群技能。Claude Code Channels 走的是同一條路,差別在 Anthropic 官方出品,跟 Claude Code 的程式開發能力深度整合。 龍蝦去年就證明了一件事,開發者要的 AI agent 是隨時隨地能叫得動的那種。Claude Code 寫了全球 GitHub 上 4% 的程式碼,現在它跟上了。 📱 --- 📱 Threads / Facebook / 電子報「狐說八道」 #ClaudeCode #Anthropic #Channels #AI開發工具 #MCP #OpenClaw