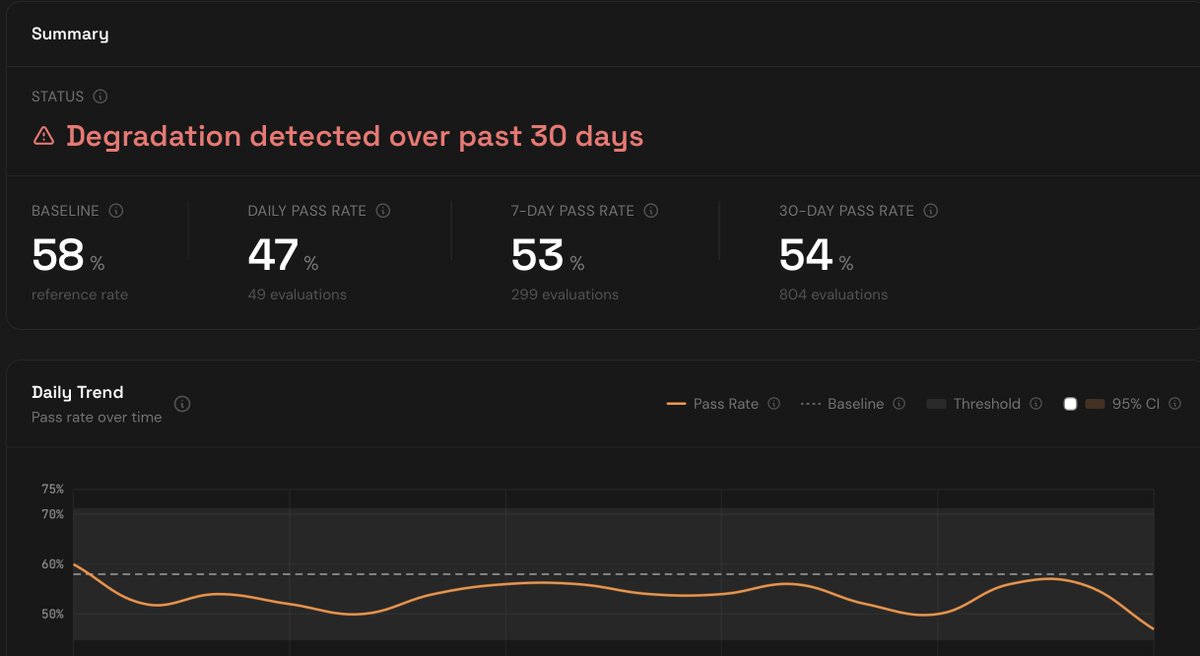
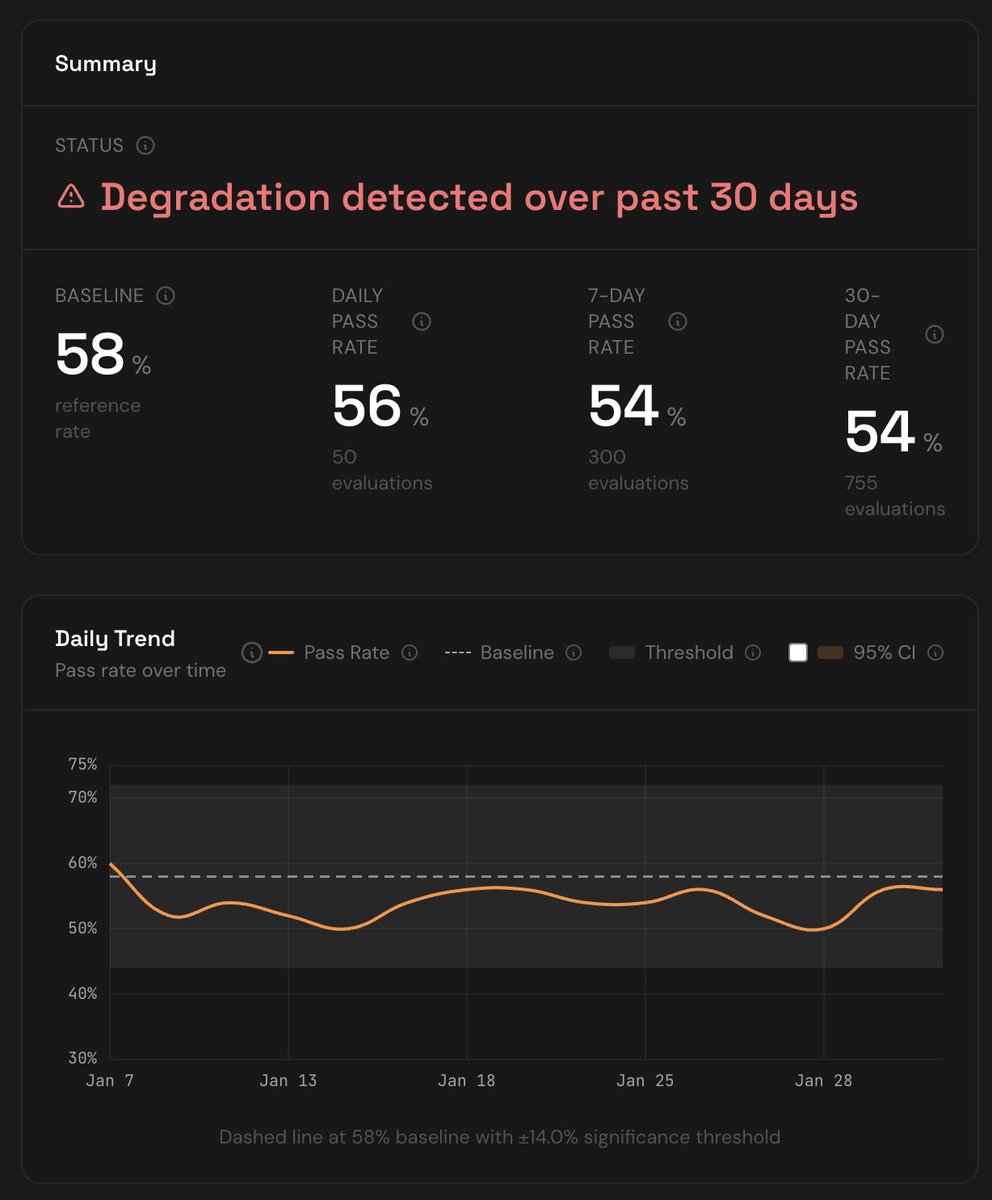
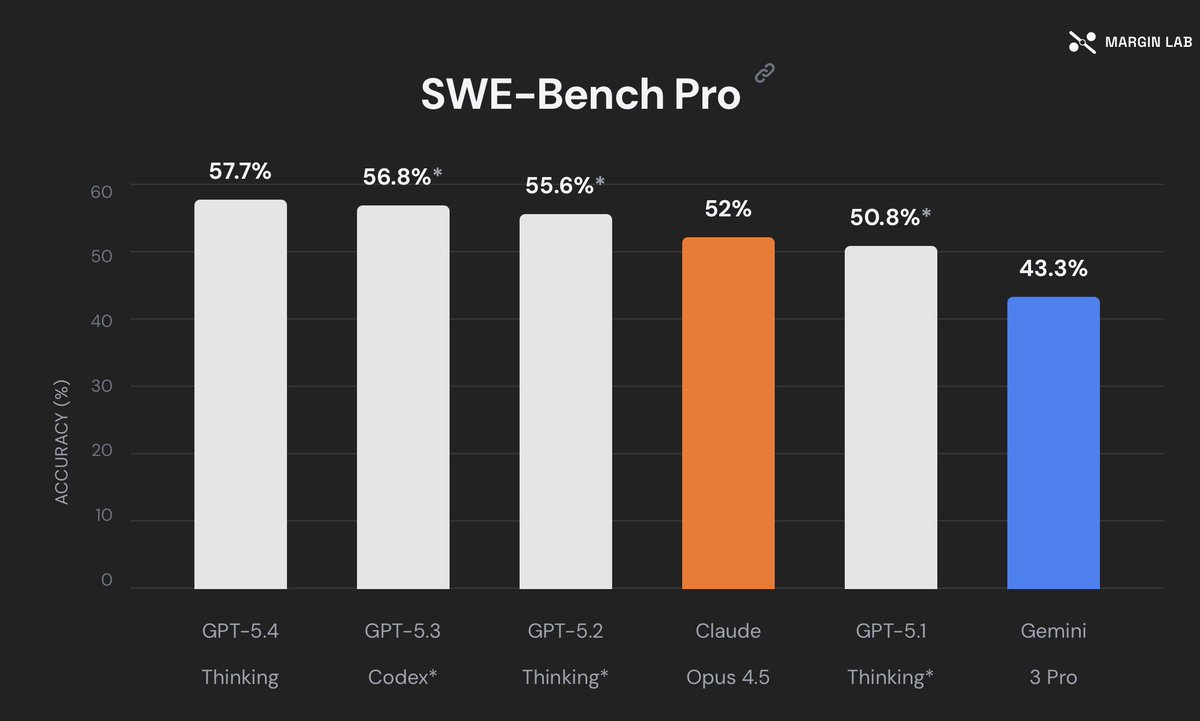
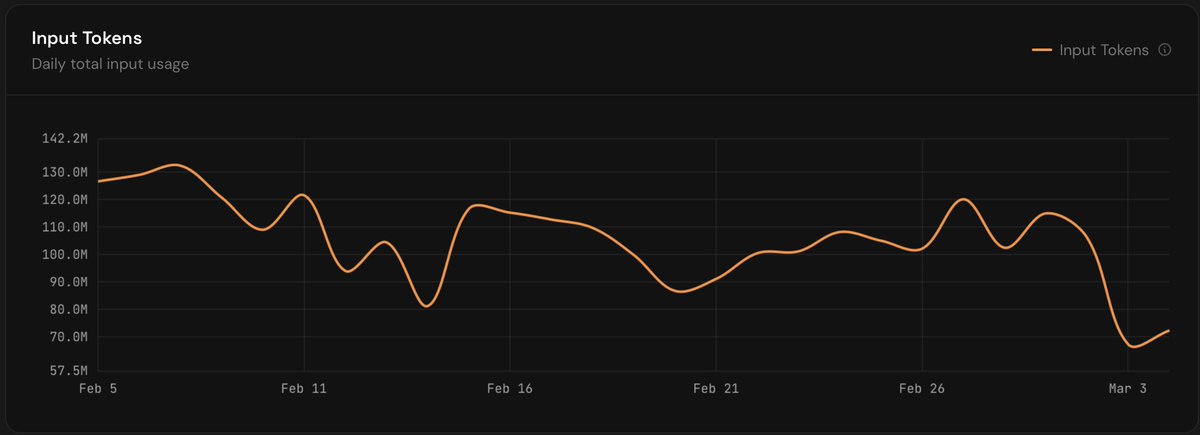
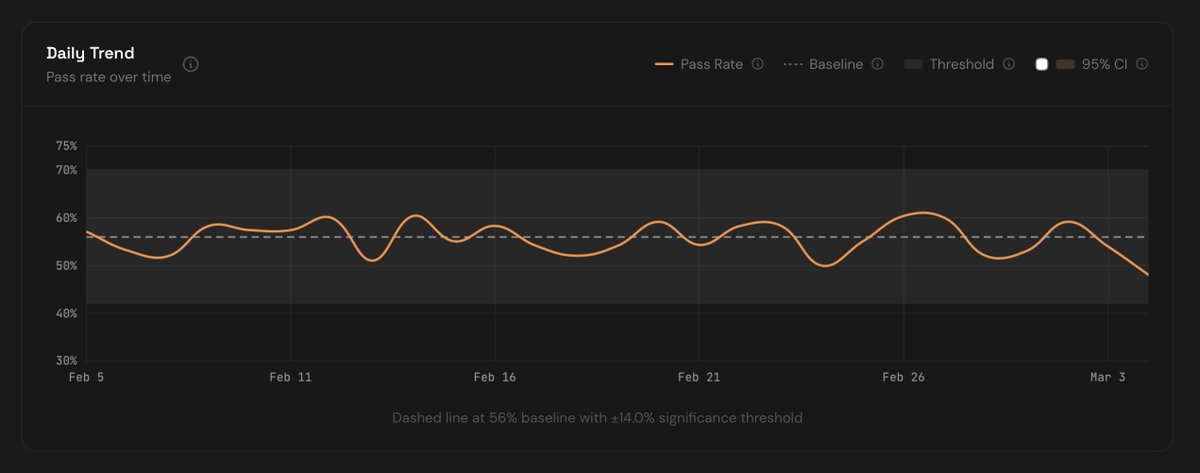
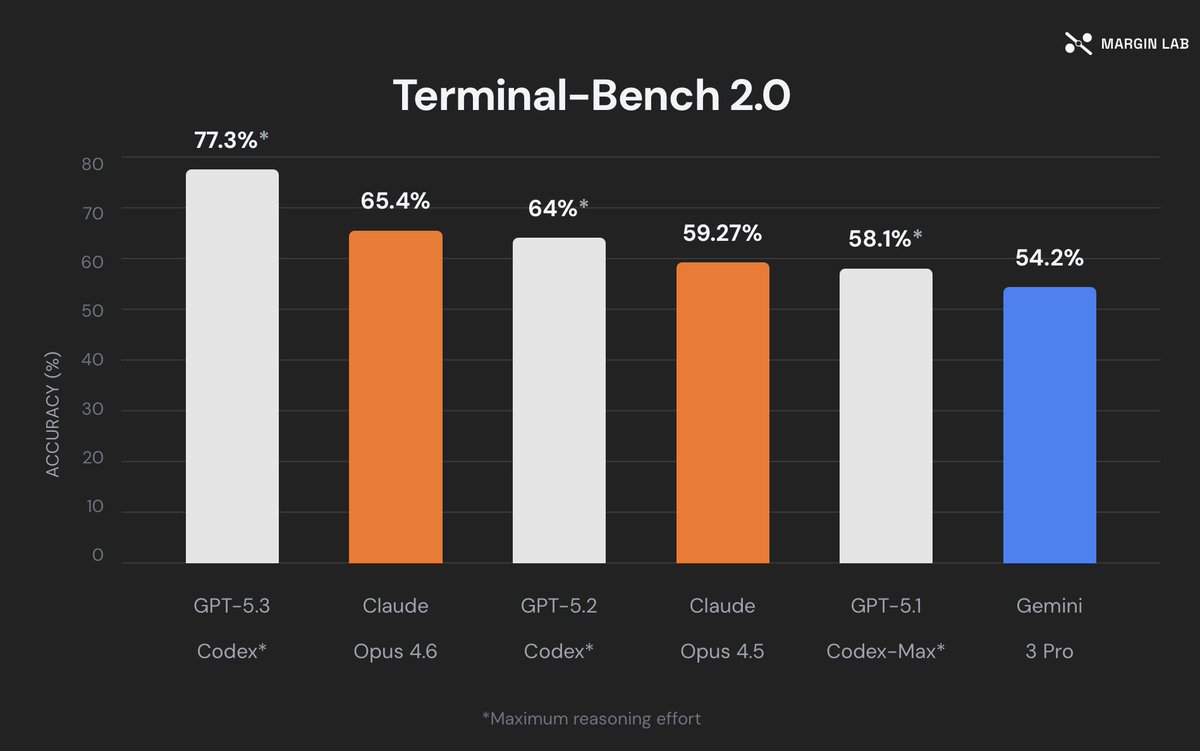
We are seeing a sustained statistically significant degradation in Claude Code with Opus 4.7 since last Friday May 22nd at marginlab.ai/trackers/claud…
English
Margins
27 posts
really good post on why agentic coding evals are so noisy and might vary by several percentage points between runs





I have never experienced a more dumb Claude Code than today, I have to start coding myself again cause it makes so many Low IQ mistakes, they must be nerfing it now that Opus 4.6 is out or something is up