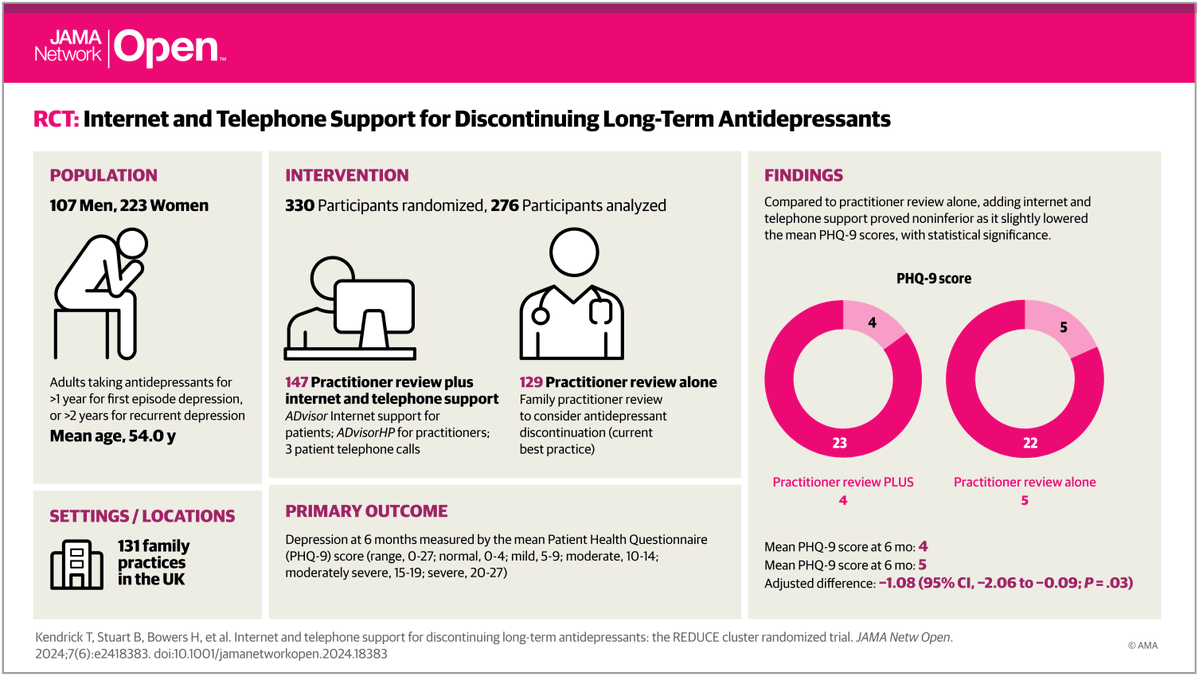
Sabitlenmiş Tweet

🚨 The HHS led by Dr. Oz and RFK Jr. just dropped a major policy letter pushing for deprescribing, shared decision-making, and non-pharmacological treatments in mental health care.
The key message: meds are essential, but shouldn't be the only tool in the toolbox 🧵

English