Kunal retweetledi

We just released a new challenge today ❗
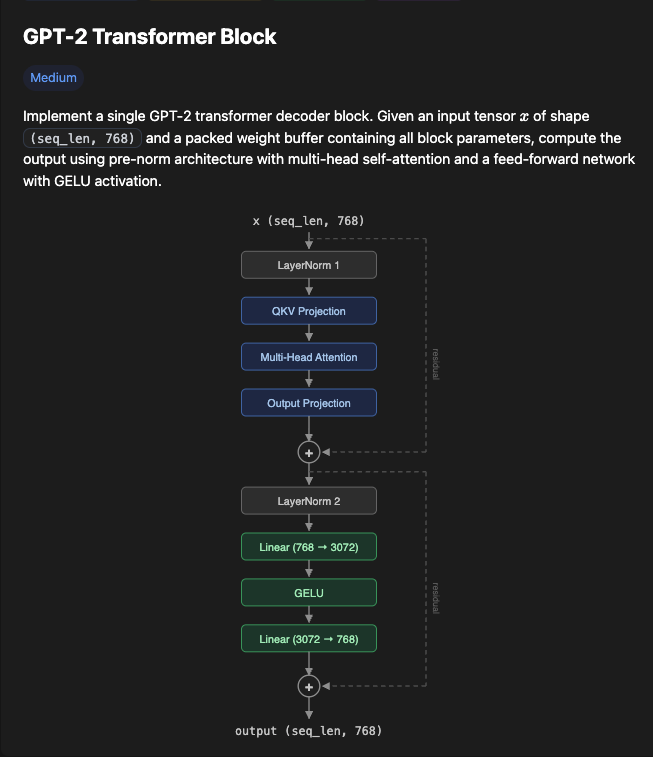
GPT-2 (120M) Transformer Block
Compose multiple kernels into a full transformer block. The first of many upcoming challenges focused on real-world inference optimization.
Write your solution in CUDA, Triton, PyTorch, JAX, Mojo, or CuTe DSL and benchmark it on state-of-the-art GPUs like the H100, H200, and B200, and more.
English