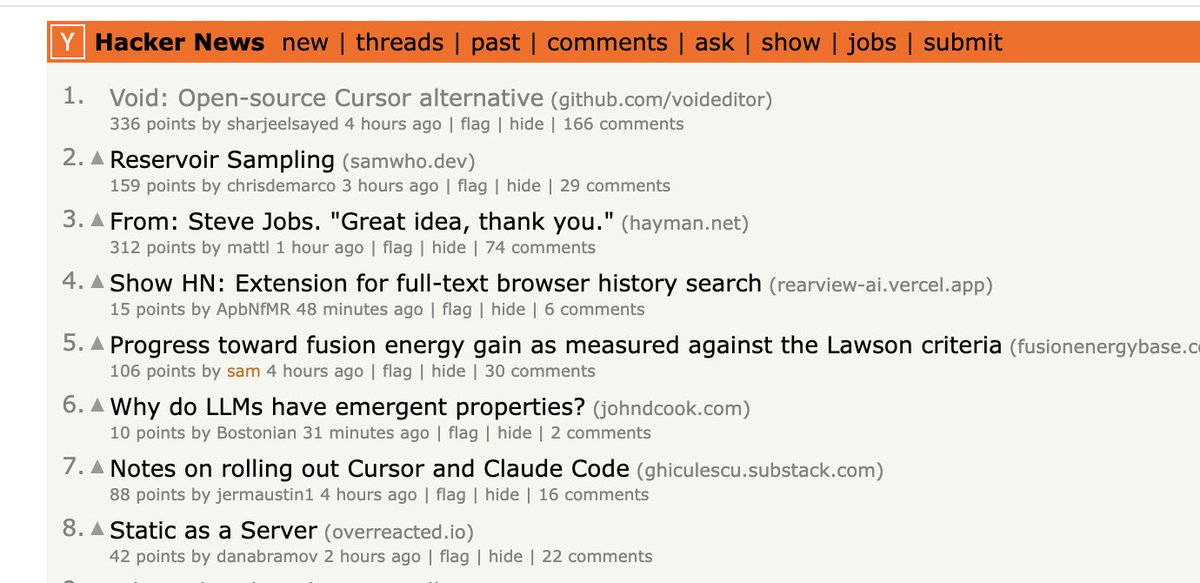
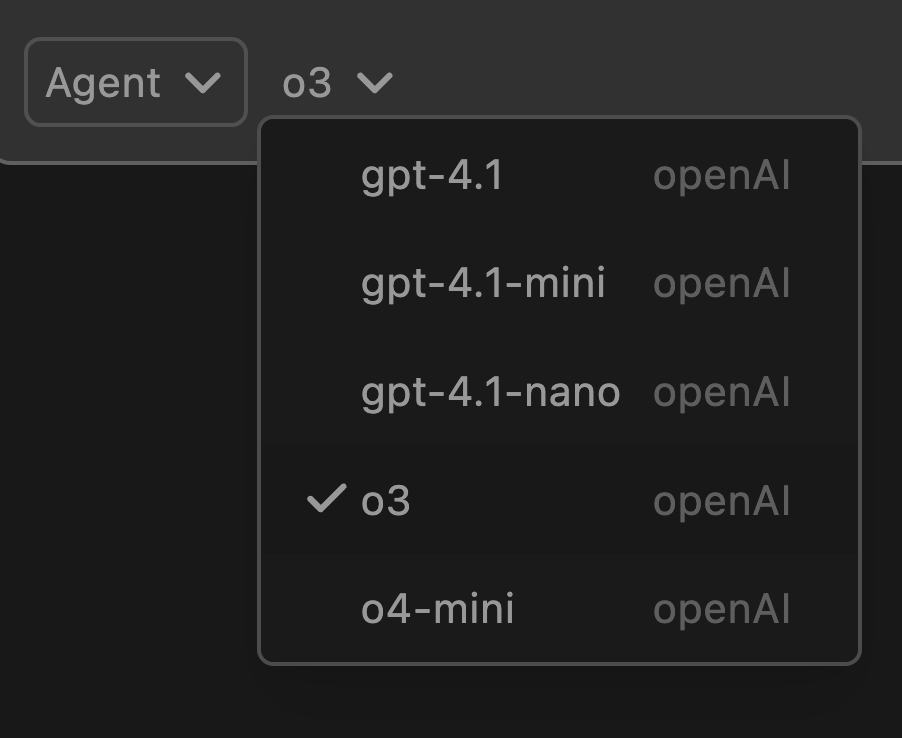
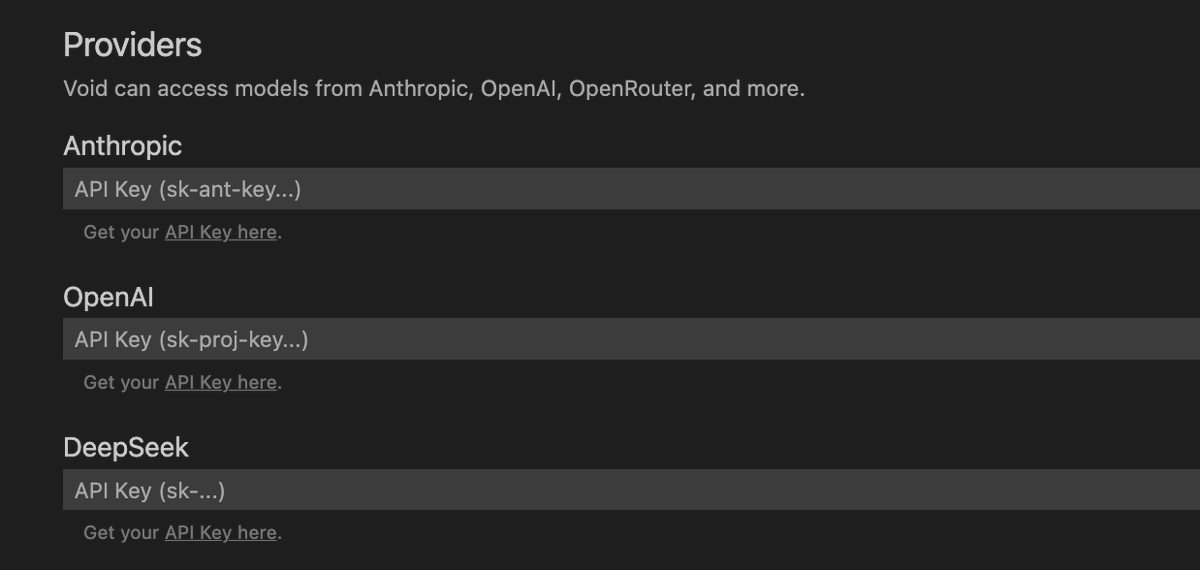
Void Editor (YC S24) retweetledi

gpt-oss is out!
we made an open model that performs at the level of o4-mini and runs on a high-end laptop (WTF!!)
(and a smaller one that runs on a phone).
super proud of the team; big triumph of technology.
English