
@teortaxesTex It's not just lack of understanding - it's mechanistically nontrivial.
English
Timoleon (Timos) Moraitis
2.1K posts
@timos_m
Building brain-like AI @noemon_ai Previously @Huawei @IBMResearch @ETH_en @UZH_en @ntua

The AI posts are getting noticeably worse lately. wtf do you mean "this isn't resilience—it's infrastructure"


@kalomaze It feels like everything fun was defined in the 90s and now we are just scaling

Its very possible that LLM trained on newtonian physics may never come up with relativity to explain cosmic scale gravity. In that case Einstein would have to intervene and solve it instead. But would he have had come up with it, assuming he offloaded all the physics problem solving to LLMs? I think this is serious problem. Undoubtedly many GOATs are only GOATs because they built all the intuition from problem solving themselves. Grothendieck famously reinvented measure theory from scratch when he was teenager. If people offload their RL envs they couldve used, to LLMs, we will never get the next Einstein



it's fascinating how much of AI development was prophesied ahead of time... even reading through old RL texts, it's as if the authors knew they were only playing with toy problems in preparation for the "real RL" to come in the distant future


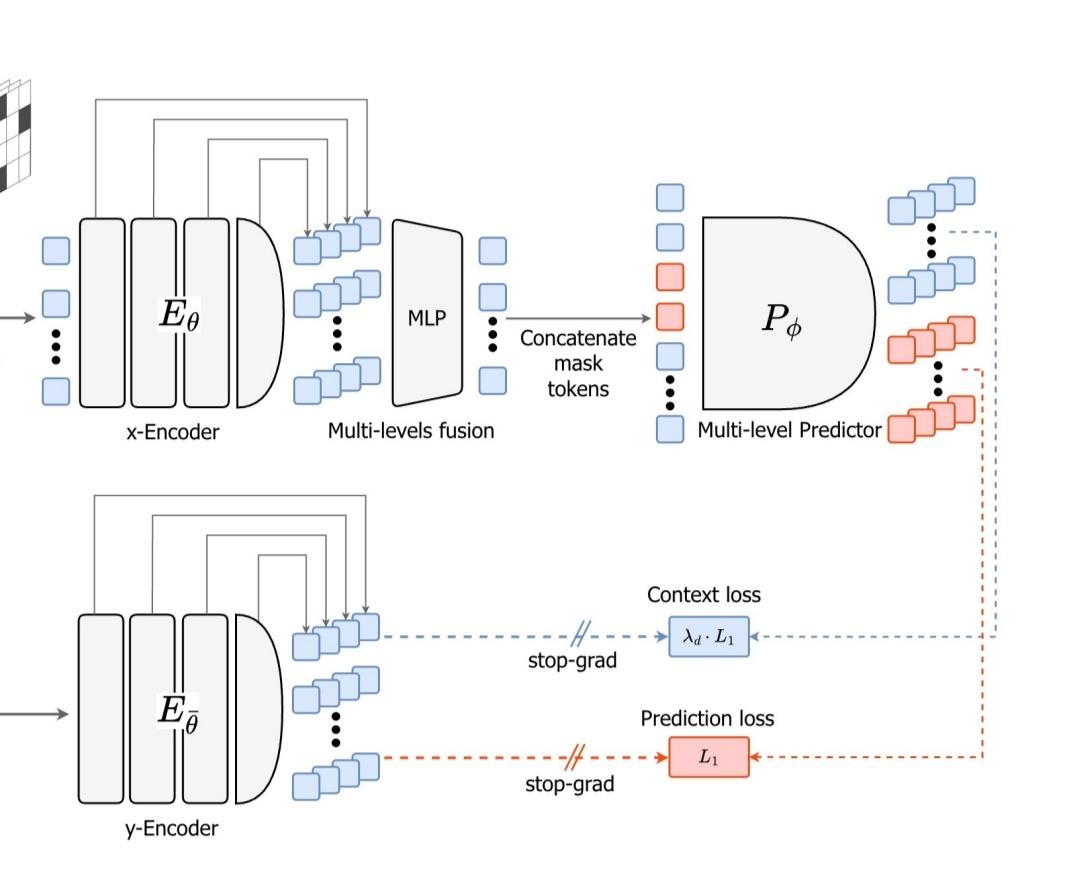

> prediction will be recasted as a hierarchical objective distributed across multiple levels of abstraction and temporal horizons along the depth of the model while being dynamically modulated to support optimally adaptive inference and learning

@SuryaGanguli @noemon_ai Yes, that older work is public github.com/NeuromorphicCo…

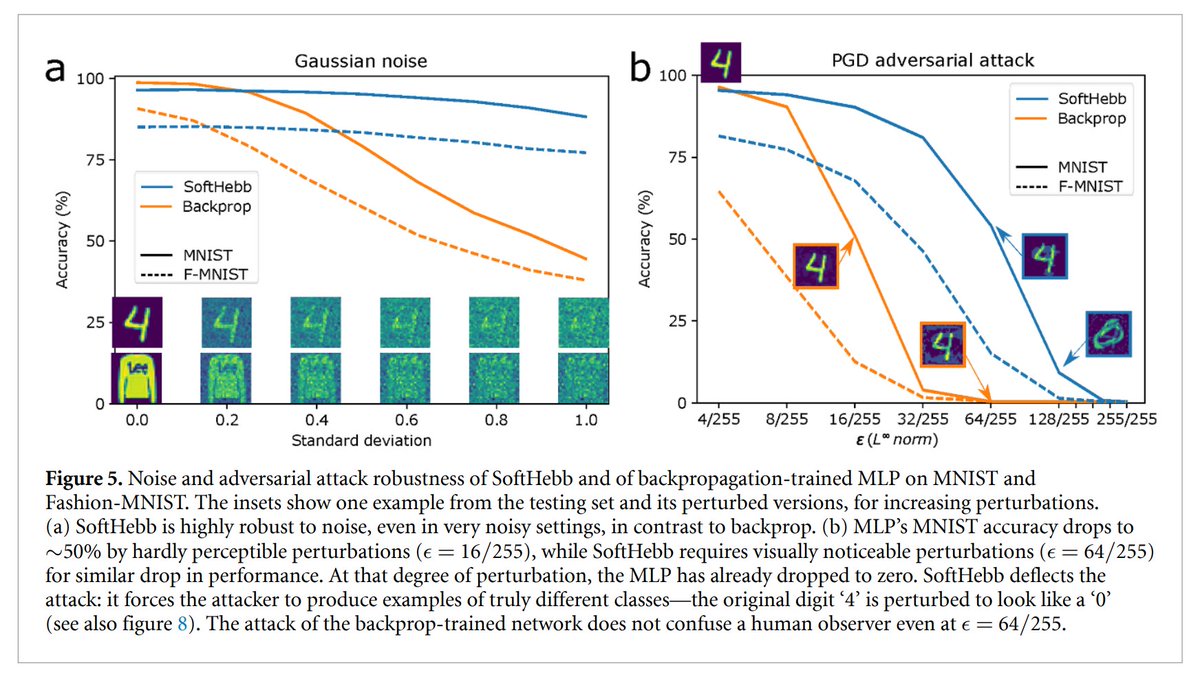
Our new paper: "Solving adversarial examples requires solving exponential misalignment", expertly lead by @AleSalvatore00 w/ @stanislavfort arxiv.org/abs/2603.03507 Key idea: We all want to align AI systems to human values and intentions. We connect adversarial examples to AI alignment by showing they are a prototypical but exponentially severe form of misalignment at the level of perception. The fact that adversarial examples remain unsolved for over a decade thus serves as a cautionary tale for AI alignment, and provides new impetus for revisiting them. We shed light on why adversarial examples exist and why they are so hard to remove by asking a basic question: what is the dimensionality of neural network concepts in image space? For ResNets, and CLIP models, we show that neural network concepts (the space of images the network confidently labels as a concept) fill up almost the ENTIRE space of images (~135,000 dimensions out of ~150,000 for ImageNet & ~3000 out of 3072 for CIFAR10). In contrast natural image concepts are only ~20 dimensional. This indicates exponential misalignment between brain and machine perception (neural networks perceive exponentially many images as belonging to a concept that humans never would). This also explains why adversarial examples exist: if a concept fills up almost all of image space, ANY image will be close to that concept manifold. We further do experiments across > 20 networks showing that adversarial robustness inversely relates to concept dimensionality, though the most robust networks do not completely align machine and human perception. Overall the curse of dimensionality raises its ugly head as an impediment to both adversarial examples and alignment: if can be difficult to get AI systems to behave in accordance with human intentions, values, or perceptions over an exponentially large space of inputs. See @AleSalvatore00's excellent thread for more details: x.com/AleSalvatore00…

Billionaire Marc Andreessen says he has "zero" introspection, and that the idea itself is a modern invention.
Models trained with certain biologically-inspired local learning rules rather than backpropagation can be MUCH more robust to adversarial attacks, as we have shown in the past. Our view at @noemon_ai is that the locality of Hebbian plasticity in certain architectures leads to more compositional features, which in turn helps address the binding problem and adversarial robustness. In this new framework of "Perceptual Manifold" (PM) by @AleSalvatore00, @stanislavfort and @SuryaGanguli, our models would have measurably smaller PM than the backprop-trained ones.





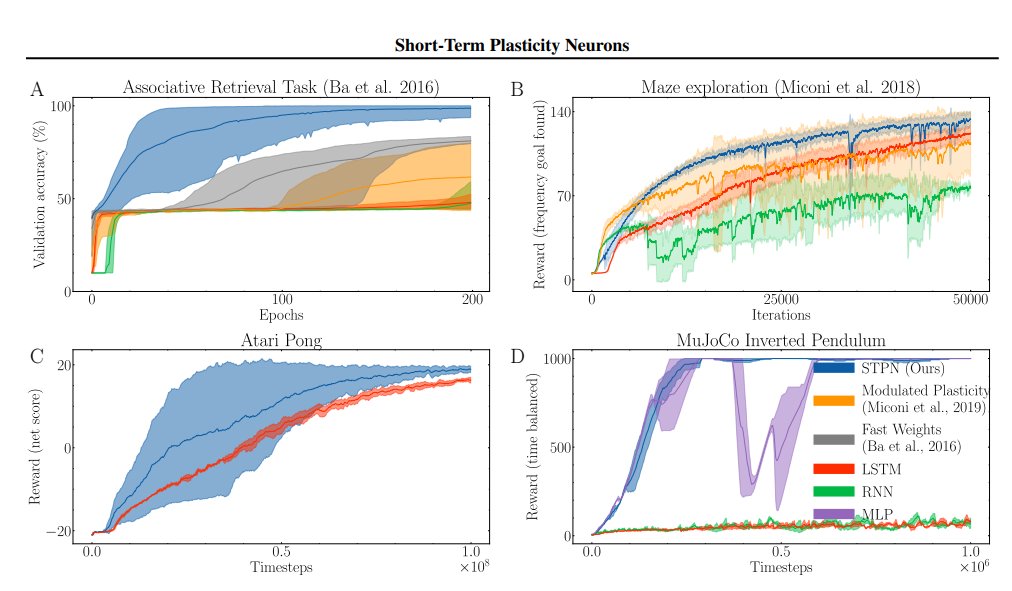
Sam Altman just said in his new interview, that a new AI architecture is coming that will be a massive upgrade, just like Transformers were over Long Short-Term Memory. And also now the current class of frontier models are powerful enough to have the brainpower needed to help us research these ideas. His advice is to use the current AI to help you find that next giant step forward. --- From 'TreeHacks' YT Channel (link in comment)

