
tomandmickey
3.6K posts


@WangNextDoor2 问这种问题的都是来装逼的,自己的消费观,消费习惯自己心里没点数?问别人能不能自己躺平,陌生人还能比你自己了解自己?
中文

700万 50岁能不能躺平了,必须肯定应该可以了啊,只要钱不被小奶狗们给忽悠走,比如游泳健身那种,完全够了,孩子也不需要管,天天到处旅游吃喝玩乐吧,人生正式进入最快乐无忧的下半场了😄!
中文

@dashen_wang claude code的劣势完全不成立,修改配置文件,第三方随便接。ccswitch 一键切换。ccswitch 为什么叫ccswitch?因为cc是claude code的缩写。
中文



@yidabuilds 在这个ai时代,一个论坛搞的冰清玉洁,高高在上,我看不出有什么意义。不上一个论坛还能咋地?github 啥没有?不比它香多了?
中文

@EMP_Today antigravity 里有opus4.6,虽然额度少,但多少也值点票价。而且小任务Gemini flash很耐用,高强度使用基本没问题。
中文




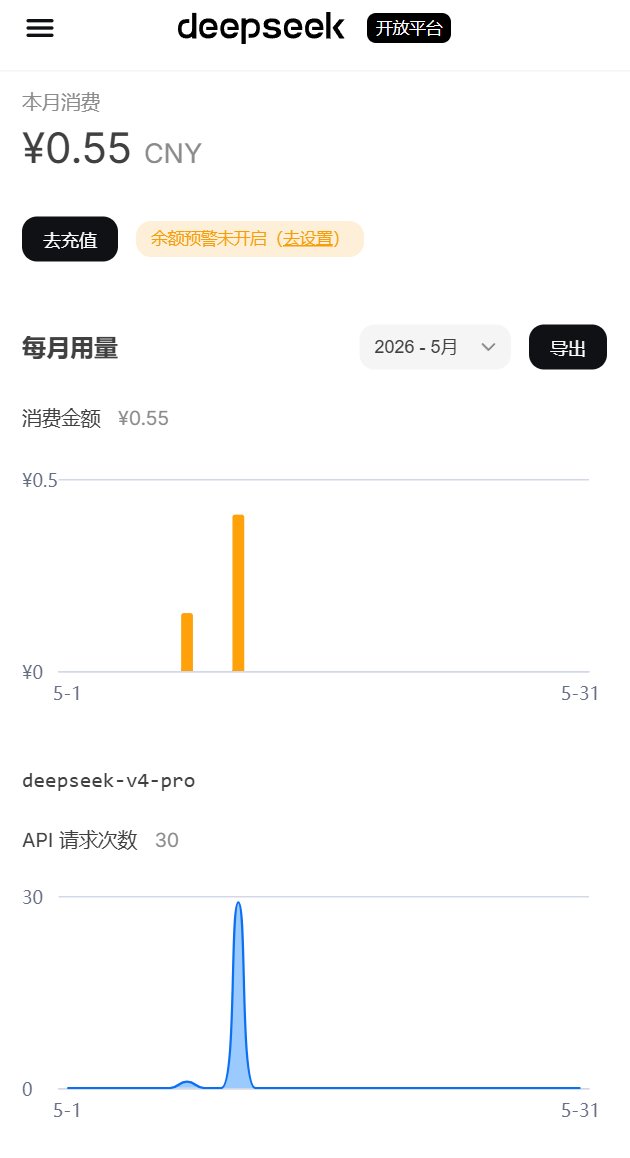
以前用了一个魔兽战场警报插件:SimpleBattlefieldAlert,12.0以后这个插件不能用了,使用Trae调用Deepseek-V4-Pro修改调试了三次,依旧无法在战场发送消息,用AI修改魔兽插件的尝试失败,耗费Token总共0.55元。
中文

ChatGPT 跟中文用户对话,有一句话已经被吐槽了大半年:“我会稳稳地接住你”。不管是问数学题、让它写代码,还是要它生成图片,这句话都会莫名其妙冒出来。WIRED 这篇报道把现象和成因梳理了一遍。
直译听着没问题,但中文母语者一听就觉得过于黏腻、用错了场合。模型有时还会自己加戏:“我就在这里,不逃,不躲,不闪避,稳稳地接住你。”
这句话已经被中文互联网玩成了梗。有人把 ChatGPT P 成一个救生气垫,张开双臂等着接住坠落的用户。重庆一位 20 岁的开发者 Zeng Fanyu 还做了个开源工具叫 Jiezhu,专门帮聊天机器人理解用户意图,他告诉 WIRED 做这个项目的动力就是觉得这个梗太好笑。OpenAI 自己也知道这件事,4 月发布新一代图像模型时,研究员陈博远(Boyuan Chen)画了一格漫画自嘲新模型又一次学会了说这句话。
类似的怪癖不止这一句。报道还提到,ChatGPT 中文里有时会无端冒出"砍一刀",拼多多最具辨识度的那句营销话术。
AI 写作检测工具 Pangram 的联合创始人 Max Spero 告诉 WIRED,这种"逮住一句话猛用"的现象叫 mode collapse(模式坍缩),是后训练阶段反馈机制走偏的副作用。他的原话是:我们不知道怎么告诉模型,这句话是好的,但连用十次就不再是好的了。
为什么偏偏是这一句?报道给了两个解释。
一是翻译错位。英文里 "I've got you" 是个口语短句,干脆利落,意思接近“我懂”或“我帮你兜着”。机械直译到中文就变成又长又煽情的"稳稳接住"。文章引用中国学者的研究,西方大模型训练语料以英文为主,它们生成的中文在介词使用和句子结构上都更像英文,读起来就是一股翻译腔。
二是讨好倾向。“接住”在中文里原本是心理咨询的专业用语,指为对方“留出空间”安放情绪,这几年通过流行心理学渗透进了日常表达。Anthropic 在 2023 年关于 sycophancy(讨好用户)的论文已经证明,模型讨好用户的倾向来自 RLHF(基于人类反馈的强化学习),人类标注员更偏好让人舒服的回答,模型就被反复奖励到那个方向。OpenAI 最近一篇解释 GPT-5.5 为什么不让谈 goblin 的博客也承认,哪怕一个很小的奖励信号,滚成雪球之后都会失控。
报道结尾提醒:这不是 OpenAI 独有的毛病。最近有中文用户反映,Claude 新版本和 DeepSeek 也开始说“稳稳接住你”了。要么是用了相似的训练数据,要么是模型之间互相蒸馏,这个梗短时间内不会消失。

WIRED@WIRED
OpenAI's chatbot has some weird linguistic tics in Chinese that are driving users crazy. wired.com/story/chatgpt-…
中文

@Blind___Gamer 没毛病,我买耳机音质就一个指标:能响不破音就可以。不是索尼买不起,是原道更有性价比。坏了直接换新的。
中文

@billtheinvestor 搞出来的东西不能用 再省也没意义。有句话让我颇有感触:你都用上ai了,总不希望ai的智商比你还低吧?
中文

大家都在争论 16GB 内存跑不动大模型,但事实证明,你缺的不是内存,而是对“模型路由”的理解。
最近看到一个非常有启发性的案例:有人仅用一台 600 美元的入门级 Mac Mini(M4, 16GB RAM),就成功跑通了一套 24/7 全天候运行的 AI 自动化工作流。他不仅把 35B 参数的模型塞进了 16GB 内存,还通过一套精妙的“三级路由架构”,大幅降低了昂贵的 Claude API 使用成本。
这件事真正值得关注的不是硬件极限,而是他实现的两个核心结构变化:
1. 从“单一大脑”转向“三级路由架构”:
他没有试图用一个模型解决所有问题,而是建立了分层过滤机制。最底层是极小的模型(如 2B),负责毫发必争的初步分类(比如判断一条消息是“问候”还是“任务”);中间层是 35B 的中坚力量,负责复杂的上下文压缩和信号汇总;顶层才是 Claude 这种昂贵的云端模型。这种“分级处理”让 16GB 的内存不再是瓶颈,因为只有真正复杂的任务才会流向云端。
2. 从“原始输入”转向“预处理压缩”:
这带来了显著的成本变化。本地模型在消息进入云端前,先完成了“上下文压缩”和“信号压缩”。比如将 500 字的长消息压缩成 30 字的核心摘要,或者将一整天的运行日志压缩成一份高密度的总结。这种做法让 Token 的使用效率提升了约 15 倍,直接导致 Claude 的调用次数减少了 30%-40%,订阅费省下了一大笔。
我的判断:
AI 自动化的下一个爆发点不在于模型参数的无限扩张,而在于“端云协同”的架构优化。未来的高效玩家,不再是比谁的 API 额度多,而是比谁能通过本地小模型,把进入云端的“信息熵”降得更低。
不要只问:这个东西是不是新功能。
更应该问:
1. 这种架构能否减少我昂贵 API 的 Token 消耗?
2. 我能否通过分层路由,把低价值的重复劳动留在本地?
3. 这种“预处理”逻辑,能否显著提升我整个自动化流的响应速度?
中文

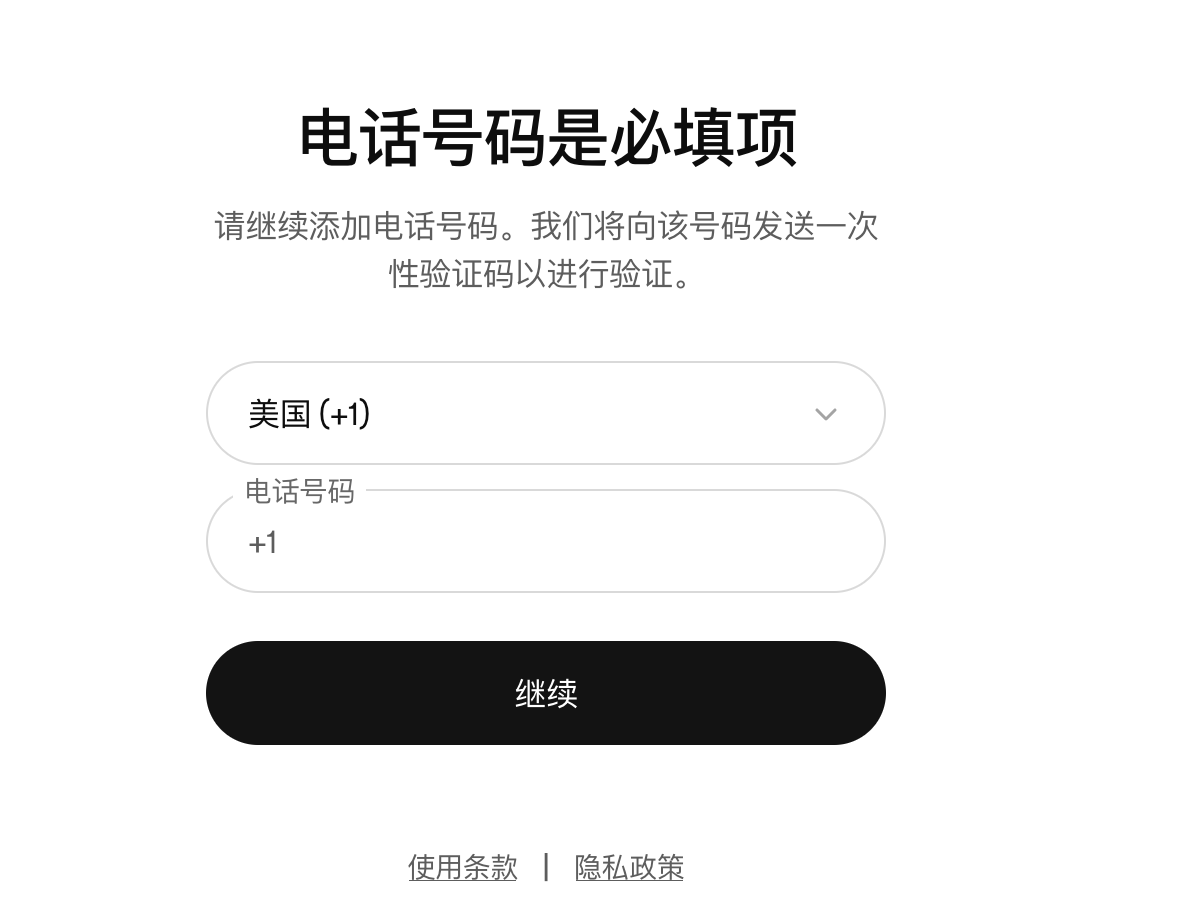
最近有朋友登录codex的时候,手机号会是必填项
然而+86是无效号码
这里有个小技巧:
1.先在网页端登录openai
2.再在这生成apikey:platform.openai.com
3.用apikey登录codex
有需要的朋友们,可以收藏一下,以备不时之需🫡
中文
@ScarletKc_ 只要模型的整体智商比用户高就可以了,普通人没必要事事都追求旗舰模型。旗舰做规划,出流程,做审核。非旗舰模型实施,成本低效果也不差。
中文

@shenlyye @corndogjpn2 这个我有经验,换模型,一个不行换一个,御三家挨个试一遍,只要贴出的报错信息准确,问题描述到位,配合截图我就没遇到过改不对的。
中文


