Benjamin xu
835 posts

如果互联网彻底中断,有没有替代方案?
完全的替代可能找不到,但是使用 LoRa 协议,可以自己组建一个通信网,实现多人群聊功能,信号覆盖整个城区。
每个人的设备成本只需几百元人民币,这应该是目前最便宜、最简单的个人通信网。ruanyifeng.com/blog/2026/05/w…


中文


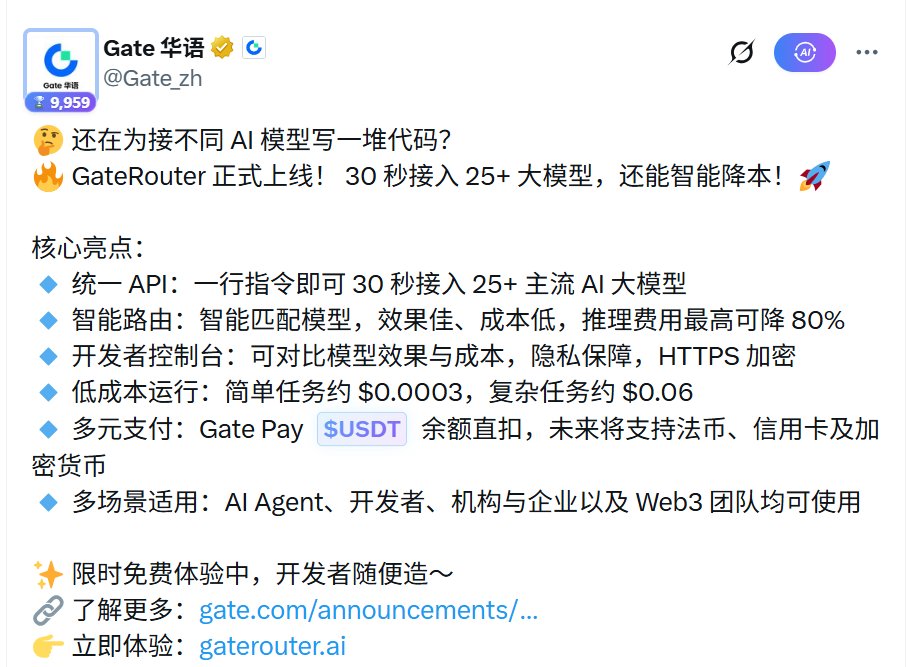
如何长期免费使用Claude opus 4.6、GPT-5.4这些最优质的大模型及其API?
菜狗带来宝藏级别教程
我今天刷推,看到Gate家出了模型中转站
本来都划走了,看到了“限时免费”
又去问了下客服,说未来很长一段时间都不会收费!
不管是玩agent,还是应用开发都能拿来随便造。
必须分享出来,顺便涨粉丝
官方文档写的也比较全,网址我放在截图里了,进去用gate账号登录就能免费使用,不收费就一直用。
如果你手里钱不多,就不要老老实实走官方订阅,用模型中转站就好,大部分人的隐私并不值钱,想办法实现token自由才是优先级最高的事情。



Researcher_王十三@ResearchWang
中文
Benjamin xu retweetledi

Benjamin xu retweetledi

🤯 解码 Agent Harness,当所有人都在教你怎么用 AI Agent,这本书带你拆开它。
42万字拆解 AI Agent 的 Harness 骨架与神经 —— Claude Code 架构深度剖析,15 章从对话循环到构建你自己的 Agent Harness。
github.com/lintsinghua/cl…

中文

Benjamin xu retweetledi

My intention was simple: to ask Peter @steipete for his thoughts. As a founder, he sees things from a different height and angle, and I wanted to hear his ideas and suggestions.
Never expected an untranslated Chinese image to stir up so much noise in the AI era.
Asking when you don't know isn't shameful. Whether he replies or not is entirely up to him — I was already prepared to be ignored. No pressure, no entitlement.
To everyone on X: let's respect each other. Happy to discuss and learn together with what limited knowledge I have.
Cander@Cander_zhu
China users have already come up with all sorts of creative ways to use OpenClaw. As the founder @steipete , do you think this approach is reasonable? #openClaw
English
Benjamin xu retweetledi


说实话,研究完字节跳动 OpenViking 的底层逻辑,我后背出了一层冷汗
回头看看我自己跑了几个月的 OpenClaw,我突然意识到一个很可怕的事:
我们要么是在浪费钱,要么是在冒着炸掉服务器的风险在裸奔
大家玩 OpenClaw,最常用的场景是什么?
chatbot是陪聊,但🦞是让它干活
爬数据、清日志、改配置。
但大家有没有发现一个现象:
刚开始它很稳,但跑了一天后,你问它“把刚才的报错修复一下”,
它可能会把昨天另一个项目的报错代码贴给你
为什么?
我想了很久,以前我觉得是模型幻觉
但结合 OpenViking 的理论,我才明白:
这是“概率匹配”的必然结果
我们现在的 RAG(检索增强生成)
本质上是在搞“赌博”
把 OpenClaw 产生的所有 session.jsonl 切碎扔进向量库
当你要它“修复配置”时,它是在几万个碎片里,靠“语义相似度”去猜哪一个碎片最像现在的场景
在工程领域,概率就是不确定性,而不确定性就是炸弹。
如果它只有 90% 的概率猜对“这是测试环境的配置”,那剩下的 10% 就是把你生产库给扬了的风险
OpenViking 这个“文件系统范式”,给我最大的震撼
它省 Token,更重要的是让它戒掉了赌瘾
它把 Agent 的记忆从“一锅粥”,变成了“档案柜”
1. 从“猜哪一个”进化到“找这一个”
以前是赌运气,纯赌狗
现在引入 L0(摘要)和 L1(概览)之后,它有了逻辑路径。
当你问“怎么修复数据库”时,
它会直接锁定 /系统维护/数据库/今日报错 这个目录,完全物理屏蔽掉 /历史归档/上周报错 这个目录
不是看谁长得像,而是看谁在正确的位置
2. 结构即安全
这句话我琢磨了很久。
为什么人类工程师不容易搞混环境?因为我们脑子里有目录树
OpenClaw 之前之所以会“上下文污染”,是因为它试图用扁平的脑子去处理立体的工程
它分不清“上周的删除指令”和“今天的备份指令”有什么层级区别,在它眼里,那都是 text
人脑不是用来处理碎片的,人脑是用来理解结构的
3. 向量库不是大脑,只是硬盘
我们以前太迷信 Vector DB 了。
但在 OpenViking 的逻辑里,向量库只是底层的硬盘。
没有文件系统的硬盘,就是一堆废铁。它给 OpenClaw 装上的,是一个能管理硬盘的 OS
这就好比:
以前的 OpenClaw,
是个喝醉了的管理员,手里拿着一堆便利贴(碎片),看到哪张像就执行哪张
现在的 OpenClaw(如果加上这个思路),是个清醒的工程师,手里拿着操作手册,先翻目录,再翻章节,最后执行
对于能操作系统的 Agent 来说,健忘只是笨,但逻辑混乱是致命的。
所以,如果你的 OpenClaw 也经常:
聊久了就把不同项目的逻辑搞混
让你不敢把 root 权限交给它
那我强烈建议你,别再盯着 Prompt 优化了。
如果不解决“记忆结构”的问题,你的 Agent 永远只是个随时可能爆炸的玩具
最后,我想说
“Agent 的终局之战,不在于谁的模型参数更大,而在于谁能构建出更符合逻辑的记忆宫殿。”
混乱的数据湖无法诞生智能,层级分明的图书馆才能
好了,那话不多说。
这个方向,我觉得就是 OpenClaw
这种“实干型”Agent 唯一的出路
为了服务器的安全,咱们得赶紧动起来了

huangserva@servasyy_ai
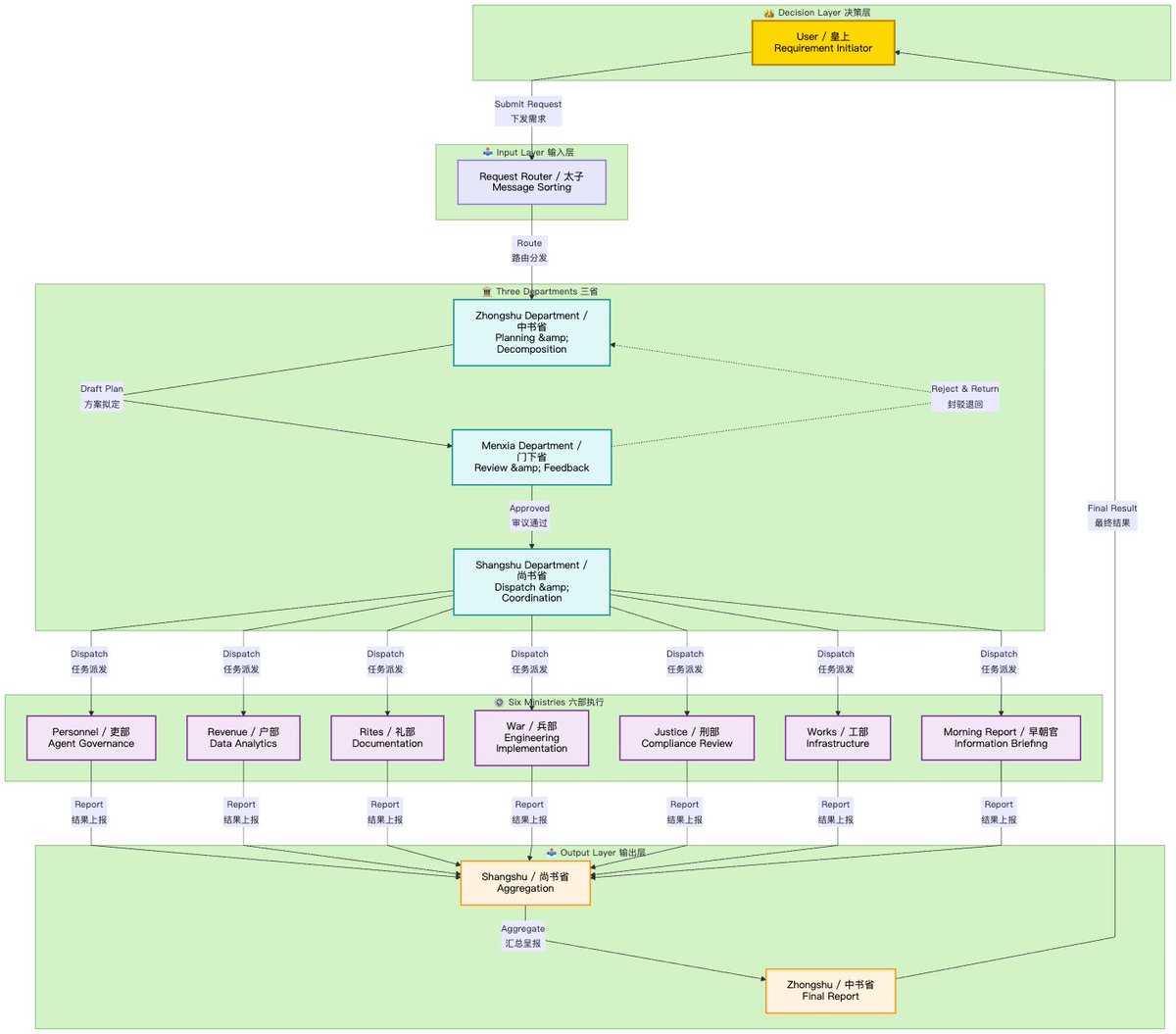
我靠,这个记忆系统很牛逼!强烈推荐🔥!! 字节跳动开源的 OpenViking,可能指明了 Agent 记忆进化的终局 现在的 Agent 普遍有“健忘症”或“幻觉”,根源在于传统的 RAG 模式太扁平了:把万卷书切成碎片扔进大桶,搜索时在大桶里捞针,这叫“平面检索”。 OpenViking 的降维打击:用“文件系统”重构记忆。 它建立了一套立体的“虚拟目录”: 1. L0 (摘要):先看文件夹目录,瞬间定位领域。 2. L1 (概览):确定相关,再读大纲,极度节省 Token。 这种“目录递归检索”的思想,让 Agent 从“造书签”进化到了“造图书馆索引”。 虽然底层依然挂载着向量库(Milvus/Chroma),但上层的管理逻辑已经是立体化操作了。 这套“文件系统范式”,才是 Agent 真正拥有大脑的样子。 核心差异: 以前:搜“代码”,给你 100 条不相干的碎片。 现在:先定项目目录,再定具体文件,最后才看逻辑行。 如果你也在被 Agent 的长文本幻觉困扰👇 github.com/volcengine/Ope…
中文
Benjamin xu retweetledi

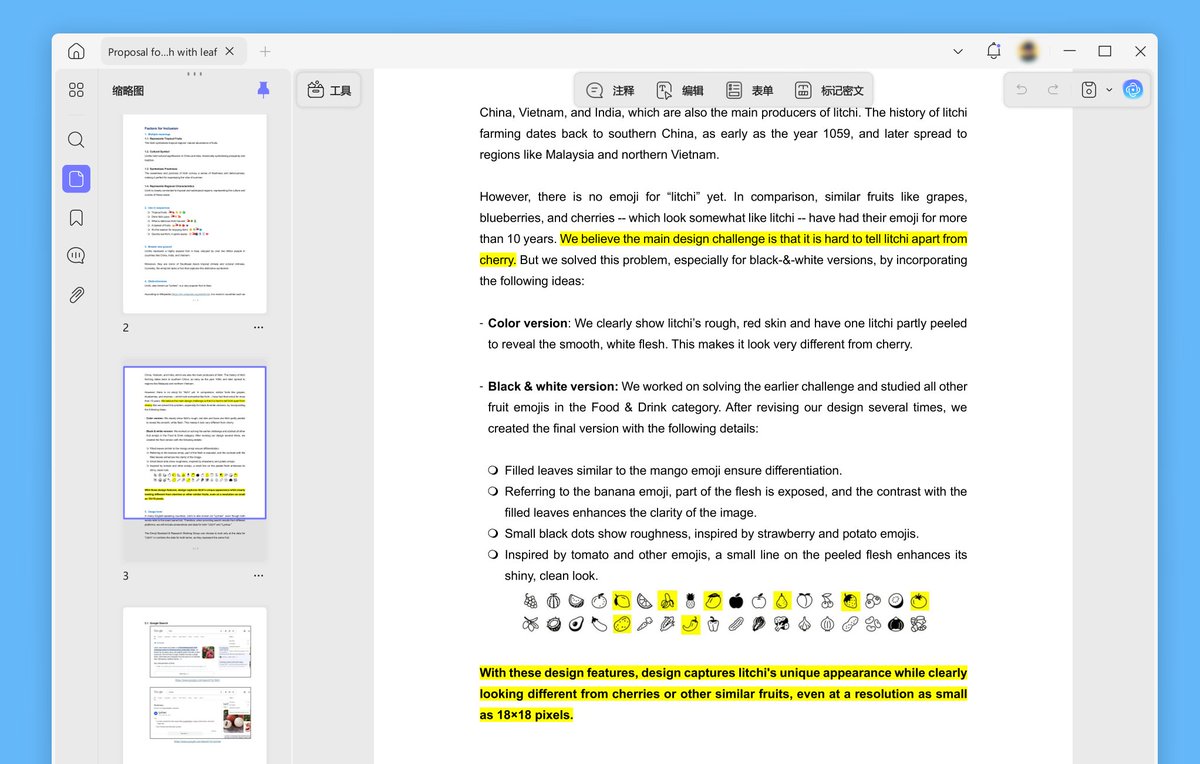
那么多年下来,葡萄🍇、樱桃🍒 都有自己的 Emoji,为啥"荔枝"却没 emoji 呢?
今年上半年,我和我司设计师按照标准流程,向 Unicode 协会提交了"litchi"的 emoji 设计稿 / 申请函,就是下图。
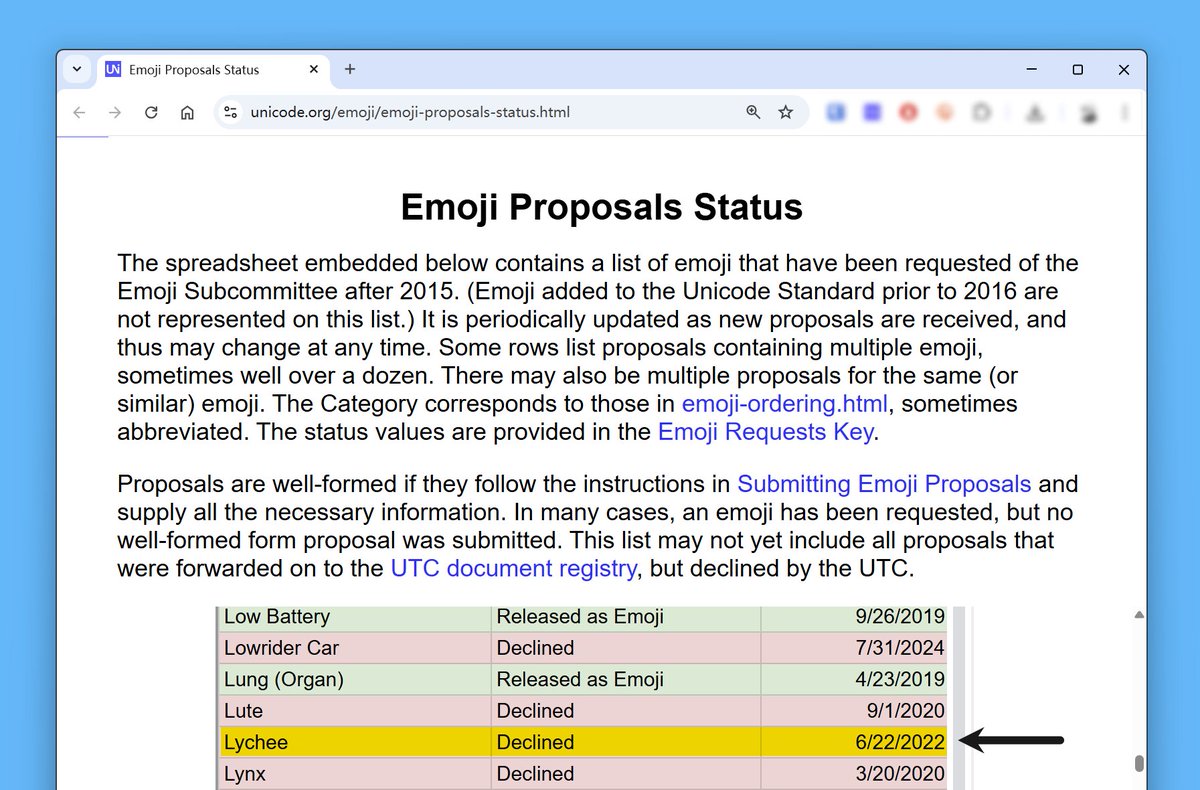
为什么是"litchi" 而不是"lychee"? 是因为 Unicode 协会规定被拒绝的 emoji 表情有 4 年的冷却期,而其他人申请的"lychee" 在 2022 年被拒绝。
万幸"荔枝"有两个英文单词!
Unicode 协会的官网上,明确将在 2025年11月30日公布 emoji 的申请结果,也就是未来 10 天。
希望大家转发点赞互动支持一下。
万一我们设计的"荔枝"emoji 真被收录了,发券!


中文
Benjamin xu retweetledi

如果说所谓没有AI味,或许是说一般人的写作句式不规则、逻辑跳跃、有小错和细节。
那么或许可以试一下下面的Prompt ,但是最重要记住AI现在也是人更超越一般人:
【1. 用词与句式
- 70% 句子长度 < 18 词;偶尔插入 < 6 词的独立短句。
- 使用常见口语连接:and, but, so, anyway, you know.
- 每段至少包含一个具象细节(气味、手感、具体对象)。
2. 叙事与结构
- 采用第一人称或“我/我们”叙述,加入个人小片段(真实或拟真)。
- 不做完整封闭结论,最后一段留一点未决疑问。
3. 语用特征
- 保留一两处自我否定或转折(“其实…但回头想想…”)。
- 允许一两个轻微重复或改写,而不影响理解。
4. 技术采样参数(如需)
- temperature 0.9–1.1;top_p 0.9;top_k 40–60。
- frequency_penalty 0.3;presence_penalty 0.6。】
宝玉@dotey
有网友问我有没有去除 AI 味的提示词,说实话,真没有,包括网上号称能去掉 AI 味的提示词我都试过,没有靠谱的。 这其实是个悖论:如果 AI 知道自己有 AI 味,它就不会写出 AI 味,你让它自己去掉 AI 味它都不知道怎么写出没有 AI 味的内容。 就我的经验,要让写出的内容没有 AI 味,第一要靠模型,越是参数大能力强的模型效果越好,比如 GPT-4.5 是我测试下来最好的,其次是 Gemini 2.5 Pro。Claude 对于有些特定提示词写作效果非常好,比如可以去看看李继刚分享的那些,但是普通提示词写出来 AI 味特别重。 提示词角度最好是你提供几篇范文给它参考,让它照葫芦画瓢会好一点。
中文

Benjamin xu retweetledi

推荐阅读:《逃离“Vibe幻觉”:为什么90%的AI用户,最终会沦为认知“寄生者”?》
> AI带来的“心流”快感,正是一种名为“Vibe”的幻觉陷阱。它让90%的用户在不知不觉中,沦为认知上的“寄生者”,其个人成长在触及AI能力天花板时便戛然而止。这背后,是一种深刻的“认知反投射”原理在悄然运作。本文将首次为你揭示这一陷阱的本质,并绘制一张逃离平庸、通往“认知共生”的唯一地图,助你成为驾驭AI、实现能力指数级增长的未来新物种。

𝙩𝙮≃𝙛{𝕩}^A𝕀²·ℙarad𝕚g𝕞@TaNGSoFT
最近通过两篇文章,本质上是提醒大家改变对LLM的认知,用好LLM的元认知力,构建好本体做好投射,就可以取得LLM认知共生指数级放大的能力。既适用于个人,也适用于企业。 至于放大指数,最后大家拼的是验证能力。😄 也是大家说的用好AI的人、和认知寄生拉大差距,甚至淘汰不用AI的人的关键所在。 逃离“Vibe幻觉”:为什么90%的AI用户,最终会沦为认知“寄生者”? mp.weixin.qq.com/s/8cr7CksDErYF… 企业BI·by·AI:无“本体”,不落地|MVO实践篇 mp.weixin.qq.com/s/cpyzuWmaxJNC…
中文