Artificial Analysis@ArtificialAnlys
Google is once again the leader in AI: Gemini 3.1 Pro Preview leads the Artificial Analysis Intelligence Index, 4 points ahead of Claude Opus 4.6 while costing less than half as much to run
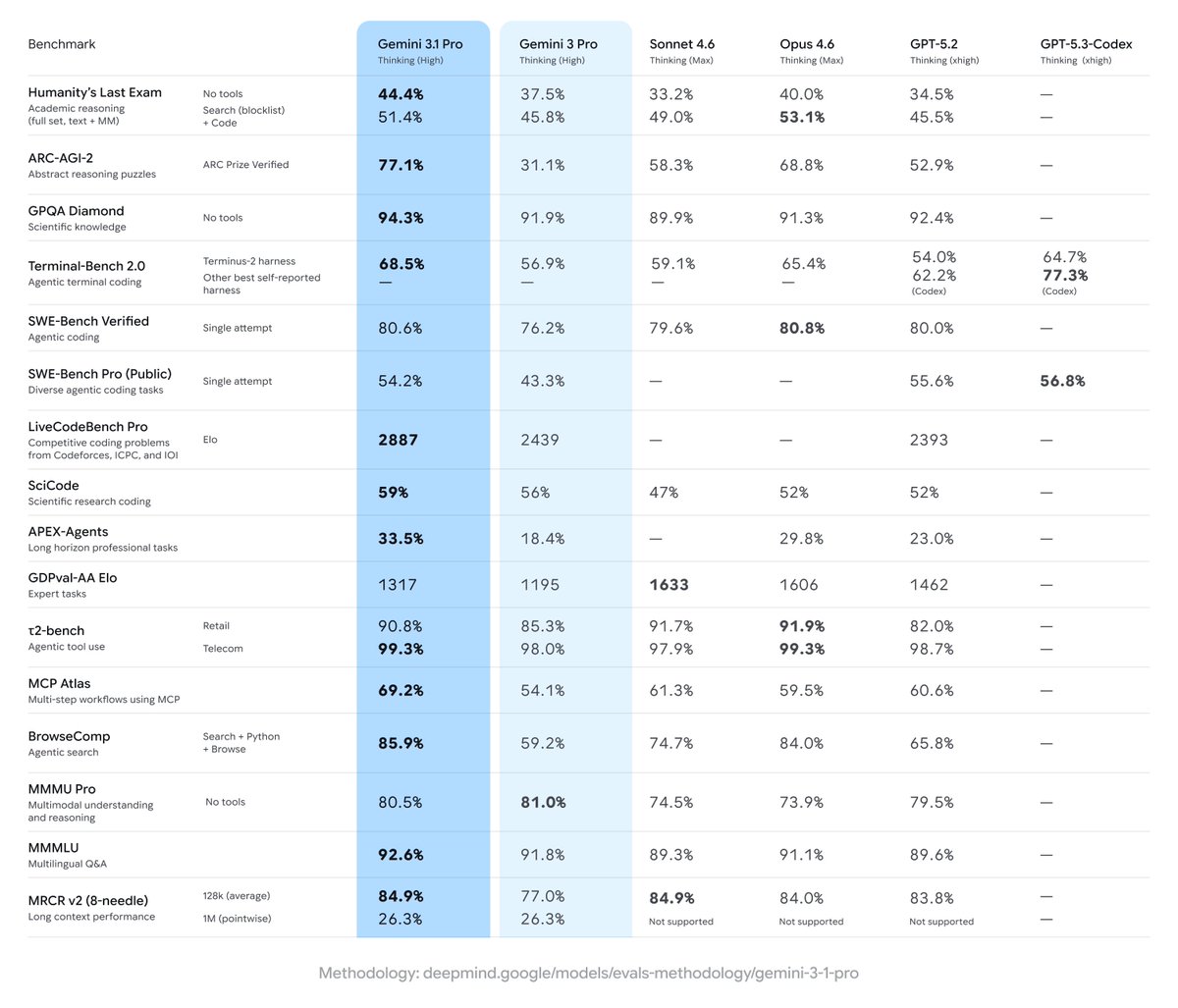
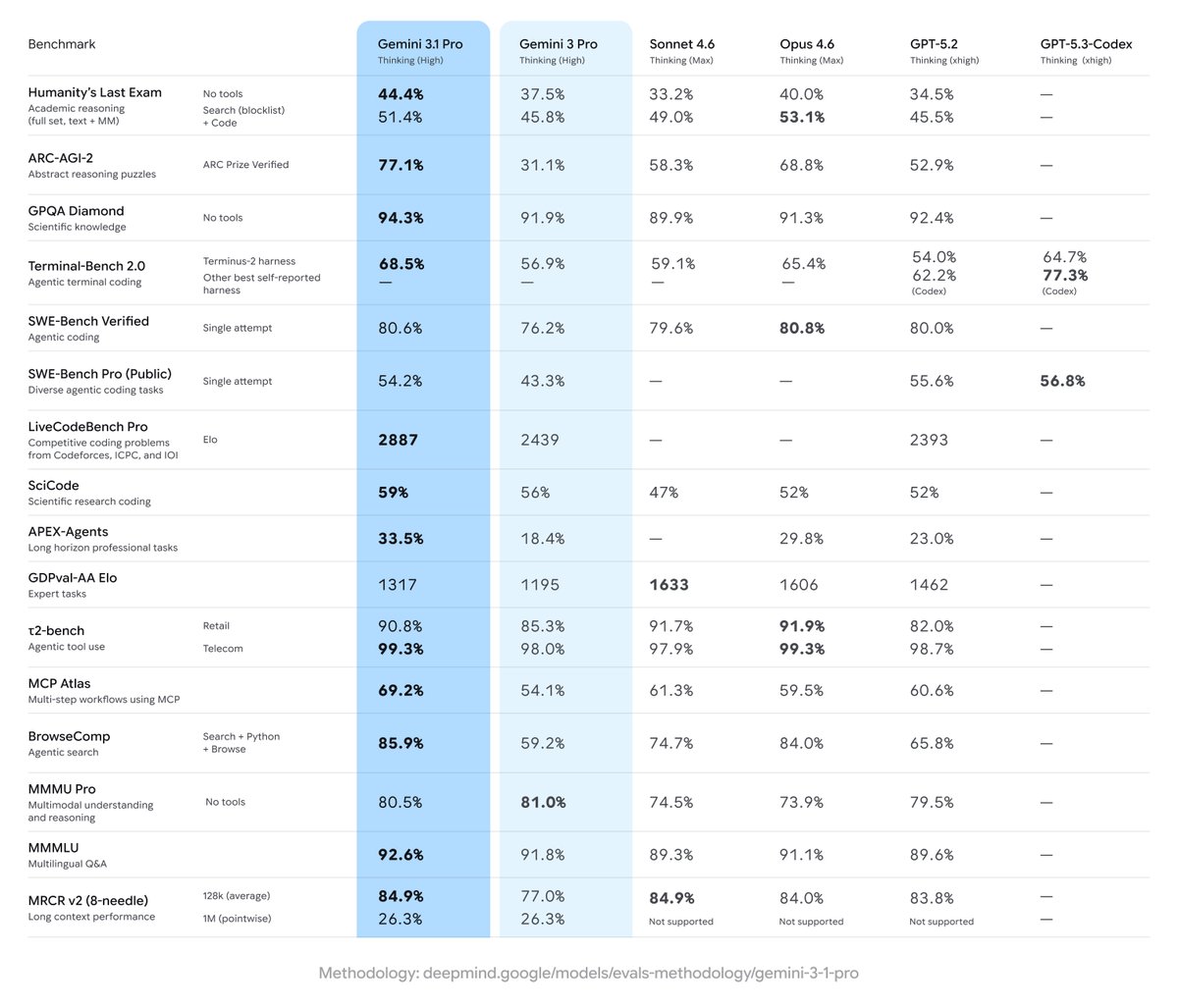
@GoogleDeepMind gave us pre-release access to Gemini 3.1 Pro Preview. It leads 6 of the 10 evaluations that make up the Artificial Analysis Intelligence Index and improves significantly over Gemini 3 Pro Preview across capabilities, with the biggest gains in reasoning and knowledge, coding, and hallucination reduction.
Gemini 3.1 Pro Preview also remains relatively token efficient, using ~57M tokens to run the Artificial Analysis Intelligence Index (+1M from Gemini 3 Pro Preview), lower than other frontier models at max reasoning settings such as Opus 4.6 (max) and GPT-5.2 (xhigh). Combined with lower per-token pricing, Gemini 3.1 Pro Preview is cost-efficient among frontier peers, costing less than half as much as Opus 4.6 (max) to run the full Intelligence Index, though still nearly 2x the leading open-weights model, GLM-5.
Key Takeaways:
➤ State-of-the-art intelligence at lower costs: Gemini 3.1 Pro Preview is leading 6 of the 10 evaluations that make up the Artificial Analysis Intelligence Index at less than half the cost to run of frontier peers from @OpenAI and @AnthropicAI. It obtains the highest score in Terminal-Bench Hard (agentic coding), AA-Omniscience (knowledge & hallucination), Humanity’s Last Exam (reasoning & knowledge), GPQA-Diamond (scientific reasoning), SciCode (coding) and CritPt (research-level physics). The CritPt score is particularly notable, scoring 18% on unpublished, research-level physics reasoning problems, over 5 p.p. above the next best model
➤ Improved real-world agentic performance, but not leading: Gemini 3.1 Pro Preview shows an improvement in GDPval-AA, our agentic evaluation focusing on real-world tasks, but is still not the leading model in this area. The model increases its ELO score over 100 points to 1316 (up from Gemini 3 Pro Preview), however still sits behind Claude Sonnet 4.6, Opus 4.6, GPT-5.2 (xhigh), and GLM-5
➤ Leading coding abilities: Gemini 3.1 Pro Preview leads the Artificial Analysis Coding Index, achieving the highest score in both Terminal-Bench Hard (54%) and SciCode (59%)
➤ Reduced hallucinations: Gemini 3.1 Pro Preview shows a major improvement in tendency to guess incorrectly when it doesn’t know the answer, reducing its AA-Omniscience hallucination rate by 38 p.p. from Gemini 3 Pro Preview
➤ Maintained token and cost efficiency: Gemini 3.1 Pro Preview improves without material increases in cost or token usage. It uses only ~2% more tokens to run the Artificial Analysis Intelligence Index than Gemini 3 Pro Preview, and keeps the same pricing ($2/$12 per 1M input/output tokens for ≤200k context). Its cost to run the Artificial Analysis Intelligence Index of $892 is less than half of frontier models such as Opus 4.6 (max) and GPT-5.2 (xhigh), though still ~2x the cost of leading open weights models such as GLM 5 ($547)
➤ Google takes top 3 spots in multi-modality: Gemini 3.1 Pro Preview ranks #1 on MMMU-Pro, our multimodal understanding and reasoning benchmark, ahead of Gemini 3 Pro Preview and Gemini 3 Flash, reinforcing Google’s leadership in multimodal reasoning
➤ Other model details: Gemini 3.1 Pro Preview retains the same 1 million token context window as its predecessor, and includes support for tool calling, structured outputs, and JSON mode