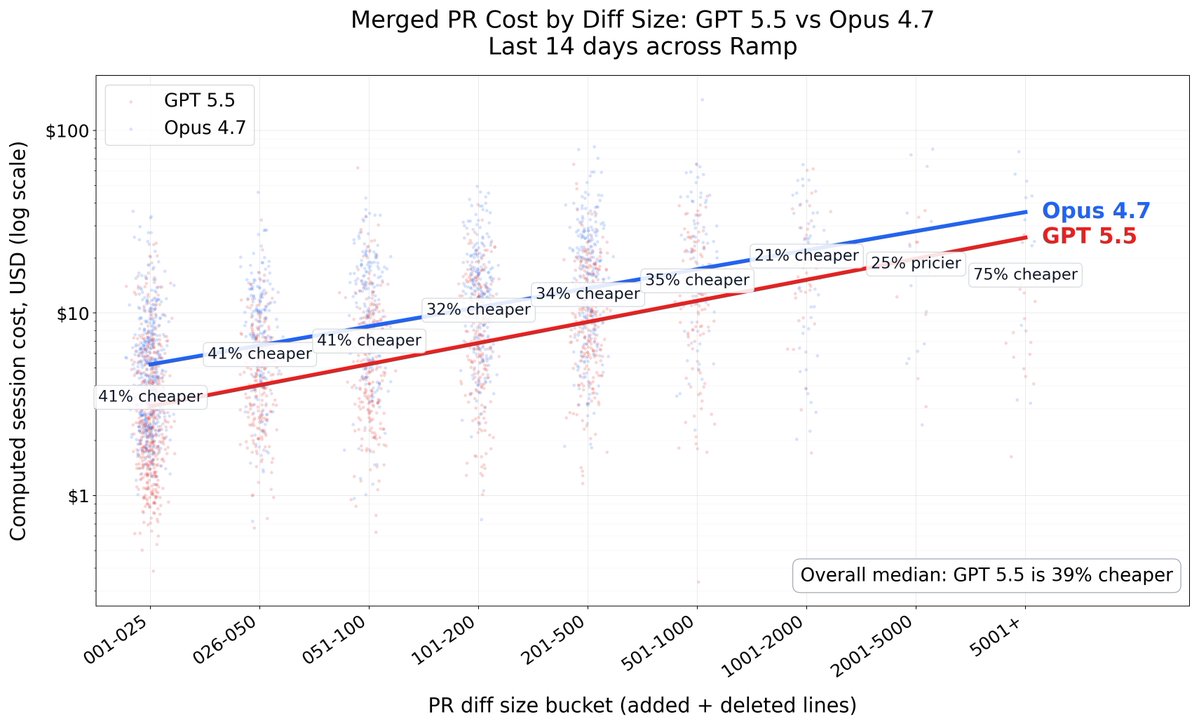
the gap between agent demos and agent deploys is not a model gap. it is a permissions and audit log gap
the model usually works. the org chart usually does not
x.com/LangChain/stat…
LangChain@LangChain
New Conceptual Guide: You don’t know what your agent will do until it’s in production 👀 With traditional software, you ship with reasonable confidence. Test coverage handles most paths. Monitoring catches errors, latency, and query issues. When something breaks, you read the stack trace. Agents are different. Natural language input is unbounded. LLMs are sensitive to subtle prompt variations. Multi-step reasoning chains are hard to anticipate in dev. Production monitoring for agents needs a different playbook. In our latest conceptual guide, we cover why agent observability is a different problem, what to actually monitor, and what we've learned from teams deploying agents at scale. Read the guide ➡️ blog.langchain.com/you-dont-know-…
English