Sabitlenmiş Tweet
uint256_t
50.3K posts


uint256_t retweetledi

MN-Coreは「データ移動は高いので、全PE共有メモリなんてあるわけない」というノリがあり、LシリーズはDRAMすらPE localな領域になりました
特にKVキャッシュはDRAM領域をかなり上のレイヤでもメモリレイアウトを把握する必要があり、vLLMを使うとはいかず……
みたいなのが楽しそうと思う人はぜひ
Preferred Networks@PreferredNetJP
【中途採用】現在PFNで開発中の生成AI推論向け半導体 MN-Core™ LシリーズのLLMサービングエンジン開発チームでエンジニアの募集を開始しました! MN-Coreシリーズのコンパイラエンジニア、ランタイムソフトウェアエンジニアも引き続き募集中です(リプライ参照)👇 Lシリーズは生成AIの推論に必要な高帯域幅を実現するため、3D積層DRAM技術を採用したアクセラレータです。本LLMサービングエンジンは、コンパイラが生成したプログラム、ランタイム環境、DRAM上でのデータ処理を緊密に協調させることで、超低遅延なLLM推論を実現することを目的としています。 ハードウェア開発者と密接に連携しながら最先端のLLM推論アクセラレータ向けソフトウェアの開発に携わってみたいという方は、募集の詳細をご覧ください! open.talentio.com/r/1/c/preferre…
日本語
uint256_t retweetledi


uint256_t retweetledi
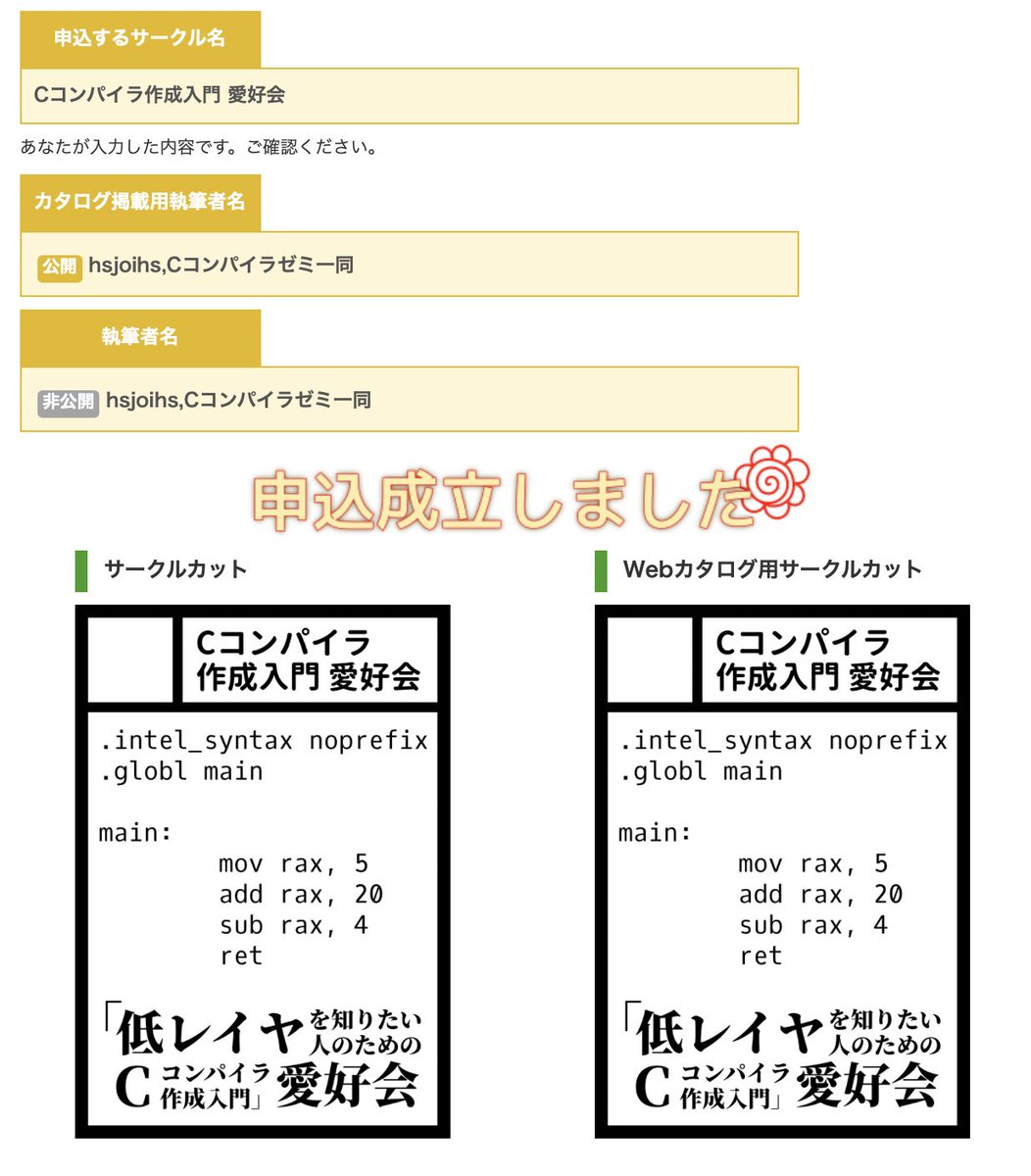
セキュリティ・キャンプ2026全国大会では、私はCコンパイラゼミを「担当いたしません」。
つまり、気兼ねなく夏コミに参加できるということです。
ということで、受かれば #コミックマーケット108 にてサークル名『「低レイヤを知りたい人のためのCコンパイラ作成入門」愛好会』での頒布を行います。
日本語
uint256_t retweetledi

非常に珍しいLLMの推論エンジンを0から(半導体から)作る仕事があります。dl.acm.org/doi/10.1145/36… を見てもわかるようにLLMというよりもむしろOS自作みたいな仕事です。
日本語








(1/n) I recently joined @trymirai, where we are working on LLM inference targeting Apple Silicon. Lately I've been digging into quantization.
LLM inference is mostly memory-bound. The byte/FLOP ratio is high enough that a lot of the machine's time goes to moving data around instead of doing compute. Quantization helps with that in general, but on Apple Silicon there's an extra payoff: the GPU has a fast W8A8 path. If both weights and activations are INT8, you can use that path for prefill and speculative-decoding verification.
Weights are easy since they're static and can be quantized offline. Activations are where the real pain starts.
English
