
Dillon Uzar
375 posts
Dillon Uzar
@DillonUzar
Building https://t.co/6ZEBsohKP9 | Compare LLMs across long context tests. Managing Member @ DeX Group LLC President @ Alkimi AI Corp Plus others.
New York Katılım Ağustos 2011
87 Takip Edilen772 Takipçiler

The bottleneck has so quickly moved from code generation to code review that it is actually a bit jarring.
None of the current systems / norms are setup for this world yet.
English
@deveshlogs @MoonshotAi @Google Agreed! I am also looking to run a couple more tests on K2.5, might post those results later if there is anything of note. I felt a little rushed to do this, but I also wanted to compare a couple of providers.
English

English
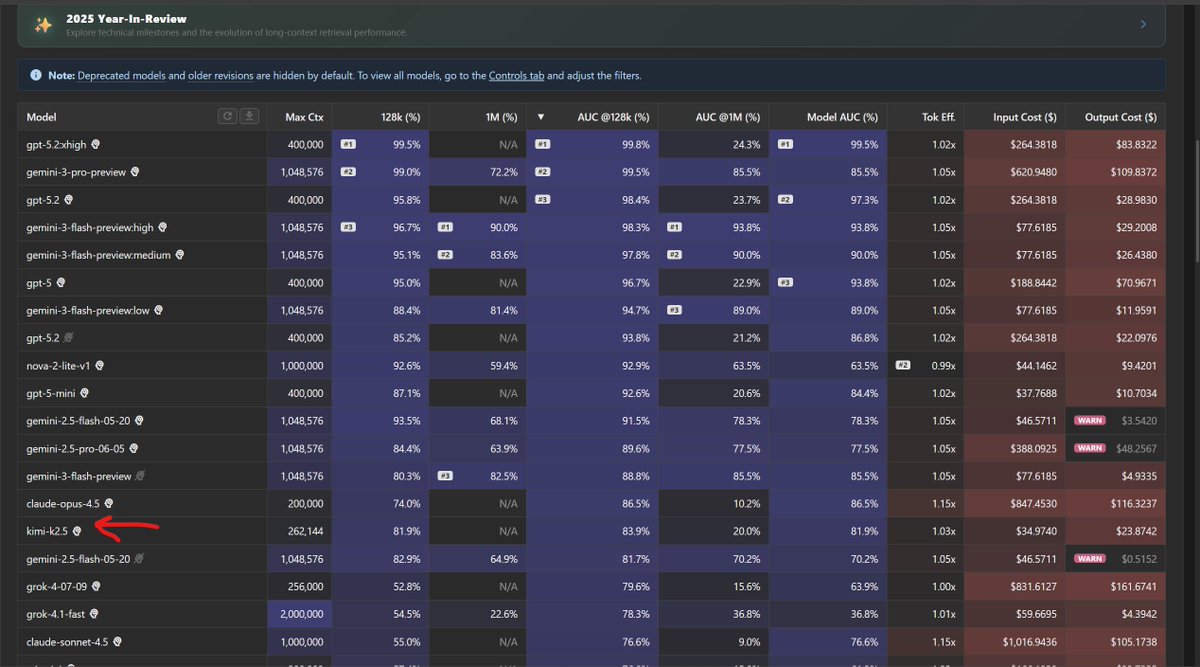
Context Arena Update: Added @MoonshotAI's Kimi K2.5 to the MRCR leaderboards (2-, 4-, 8-needle)!
K2.5 is a major step up from K2 and trades blows with @Google's Gemini 3 Flash (base) - beating it on 4 and 8-needle retrieval despite being half the cost.
moonshotai/kimi-k2.5:thinking results (@ 128k):
2-Needle Performance:
AUC: 81.9% (vs Gemini 3 Flash: 85.5%)
Pointwise: 81.9% (vs K2: 52.1%)
4-Needle Performance:
AUC: 55.6% (vs Gemini 3 Flash: 50.4%)
Pointwise: 56.3%
8-Needle Performance:
AUC: 30.4% (vs Gemini 3 Flash: 29.3%)
Pointwise: 26.9%
Full data: contextarena.ai
@Kimi_Moonshot
@GoogleDeepMind

English
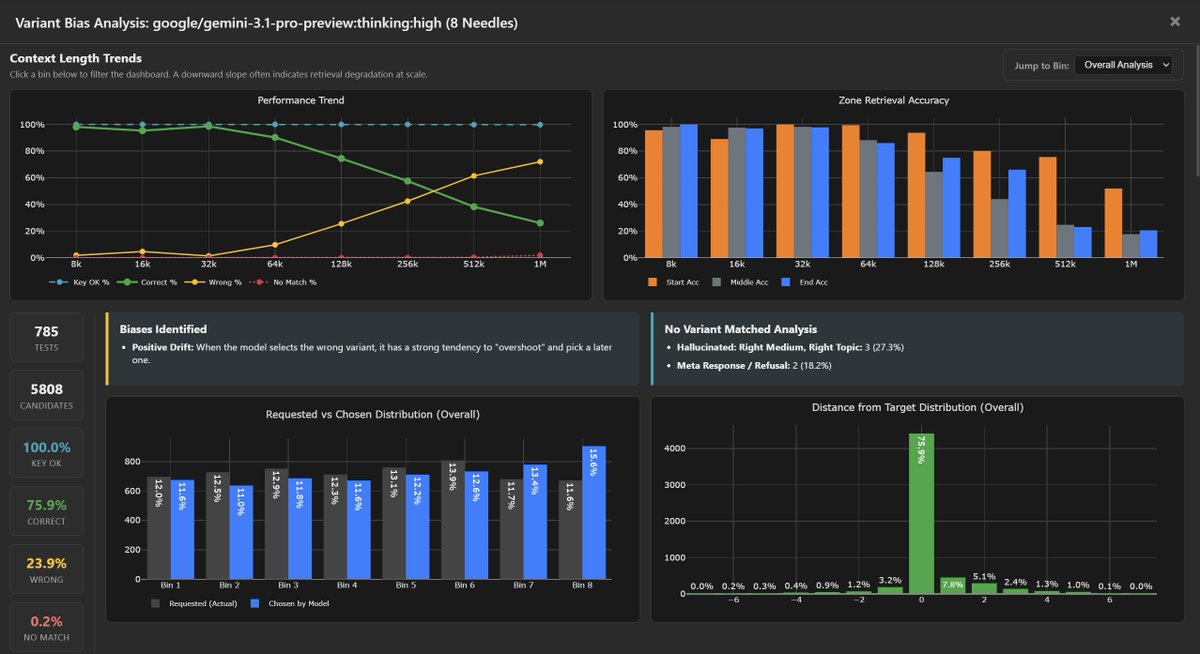
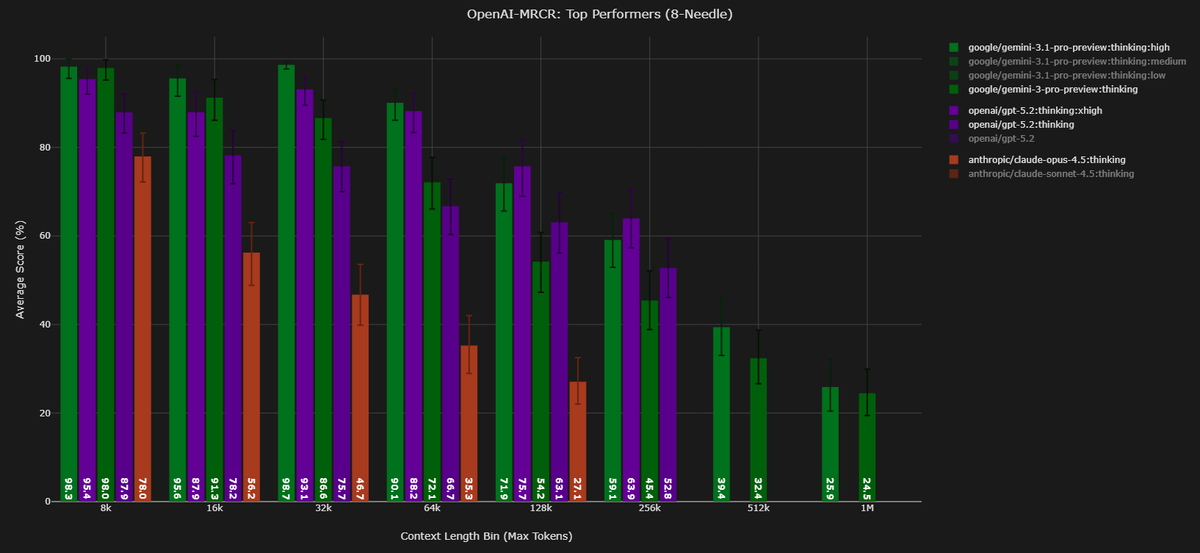
Gemini 3.1 Pro:thinking:high variant bias analysis (my new favorite analysis) on 8-needle MRCR:
75.9% correct | 23.9% wrong | 0.2% no match
One minor systematic bias detected: Positive Drift - when wrong, it overshoots to a later variant. No "Lost in the Middle," no recency bias, no creative hallucination.
On needle#8 (a needle close to the end), it tends to undershoot and pick an earlier result. This seems like new behavior compared to G3.0P.
Only GPT-5.2 and Gemini 3 Family results are as spot on as this is.
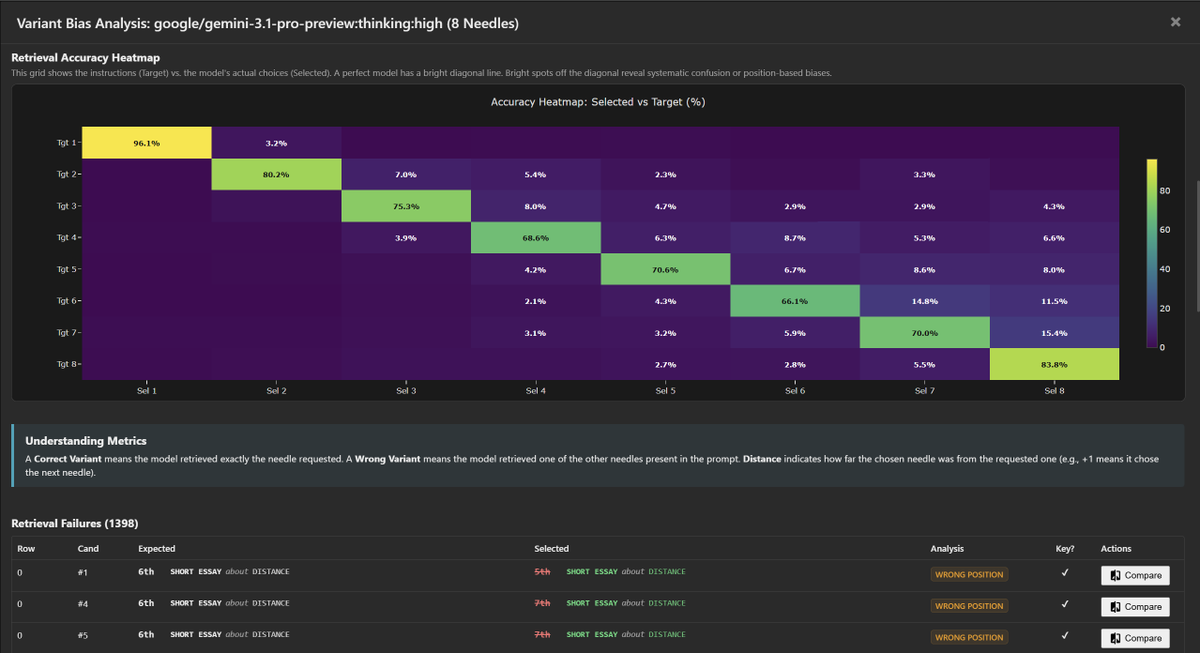
The accuracy heatmap shows a clean diagonal with tightly clustered near-diagonal errors. 1,398 retrieval failures across 5,808 candidates.
Full data: contextarena.ai (You can find this bias data under a "Bias" button found next to the model name in the leaderboard).
@GoogleDeepMind @googledevs
2/2
English
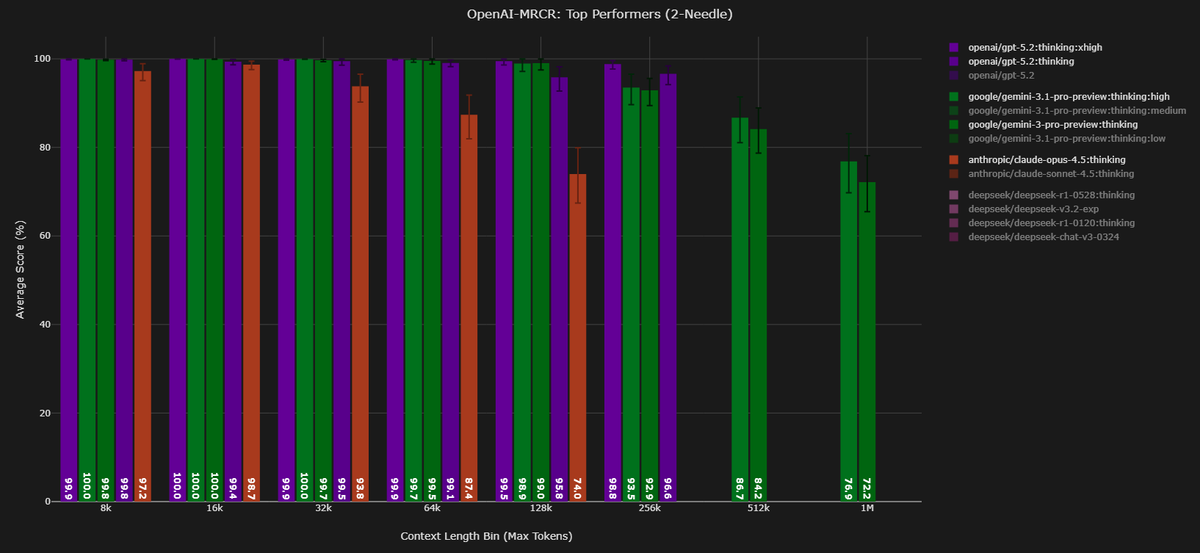
Context Arena Update: Added @Google's Gemini 3.1 Pro Preview to the MRCR leaderboards (2-,4-,8-needle)! Meant to send this out earlier today. Thanks to @GoogleDeepMind and others over there for early access!
Thinking budget barely matters on simpler retrieval - 2-needle AUC @128k spans just 0.6% across low/med/high. On 8-needle @128k, the gap widens to 7.2% (80.6% → 87.8%), showing G3.1P's updates pays off most on harder multi-needle tasks, as opposed to easier tasks.
At 128k, 3.1 Pro nearly ties @OpenAI's GPT-5.2:thinking:xhigh on 2-needle (99.6% vs 99.8%) and beats both GPT-5.2:thinking (87.8% vs 69.4%) and :xhigh (87.8% vs 86.1%) on 8-needle. Also higher than @AnthropicAI's Opus 4.5 across all needles (see x.com/DillonUzar/sta…). At 1M, solid improvement over Gemini 3 Pro, biggest gains on 8-needle (+9.5 pts).
Gemini 3 Flash leads at the 1M scale but falls behind 3.1 Pro at 128k.
AUC @128k (thinking:high):
2-Needle: 99.6% (vs GPT-5.2:xhigh: 99.8%, Opus 4.5: 86.5%)
4-Needle: 89.7% (vs GPT-5.2: 92.4%, Opus 4.5: 64.3%)
8-Needle: 87.8% (vs GPT-5.2:xhigh: 86.1%, GPT-5.2: 69.4%, Opus 4.5: 38.9%)
AUC @1M (best tier):
2-Needle: 87.8% (vs G3 Pro: 85.5%)
4-Needle: 63.6% (vs G3 Pro: 57.3%)
8-Needle: 48.5% (vs G3 Pro: 39.0%)
Full data: contextarena.ai
@AnthropicAI
@GoogleDeepMind @googledevs
@OpenAI @OpenAIDevs
1/2
English
@Jd3d4 @MoonshotAi @Google G3.1P is done, I'm just slow today😅. Meant to release it during announcement today.
Results will be live on the website in ~15min, but my post won't be till an hour for now.
English

English
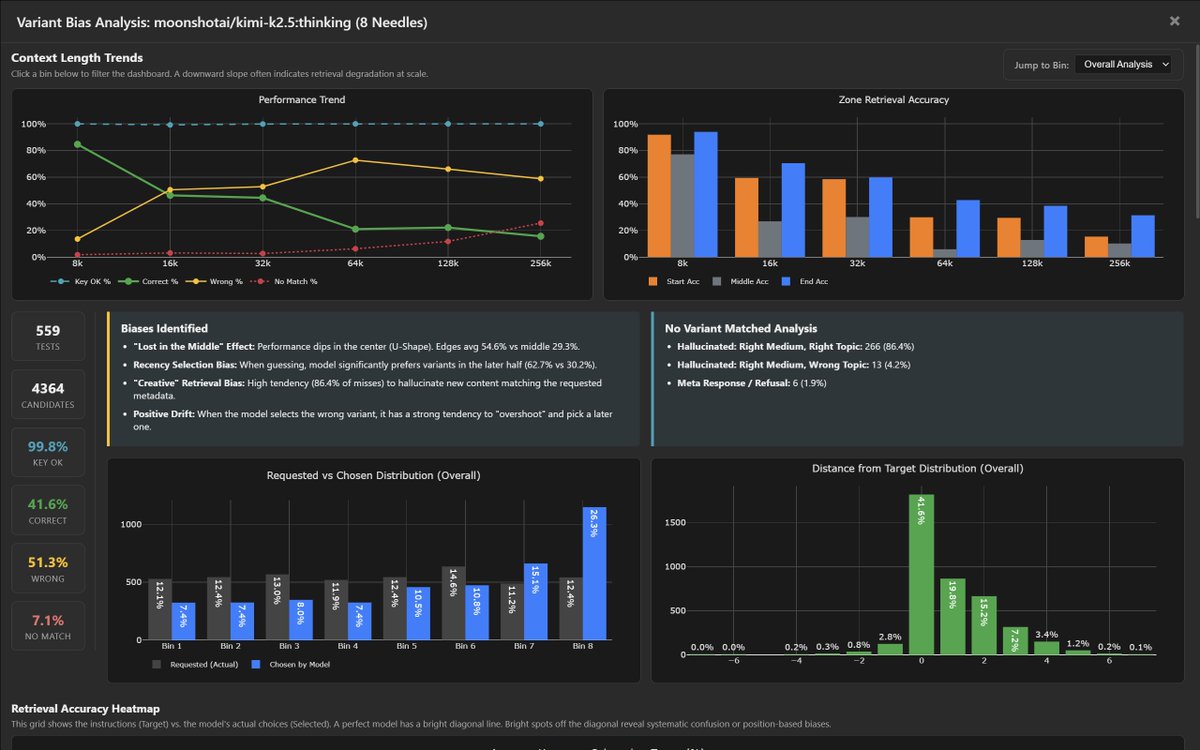
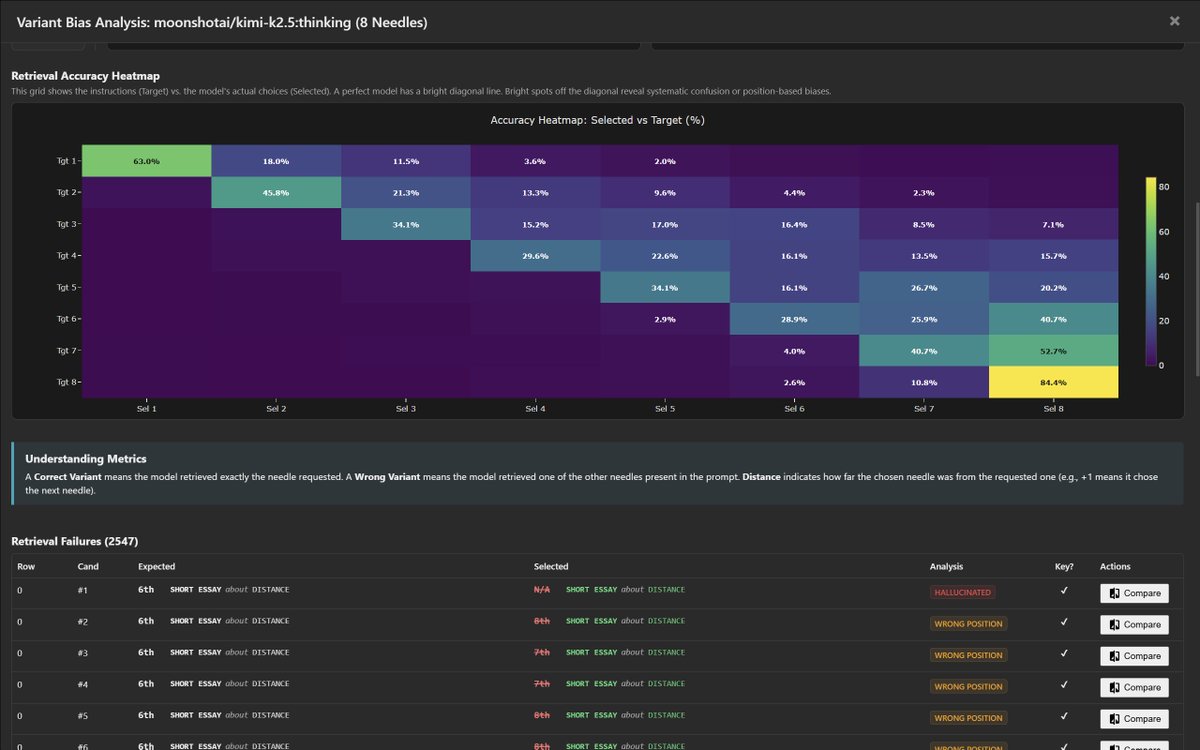
K2.5 Variant Bias Analysis (8-Needle):
The retrieval heatmap reveals a strong recency bias - K2.5 heavily favors later variants. When targeting early positions (Tgt 1-3), it frequently overshoots to later ones. Sel 8 dominates the confusion matrix with 84.4% selection rate when targeted, but bleeds into nearly every other row.
Biases identified:
- "Lost in the Middle" effect: edges avg 54.6% vs middle 29.3%
- Recency Selection Bias: significantly prefers later-half variants (62.7% vs 30.2%)
- "Creative" Retrieval Bias: 86.4% of misses are hallucinated content matching the requested metadata
- Positive Drift: when wrong, it overshoots to a later variant
51.3% of retrievals returned the wrong variant. 7.1% returned no match at all.
Full analysis: contextarena.ai
@Kimi_Moonshot
English

@DillonUzar Just a quick suggestion, after this update, could we get a banner area that shows the data refresh time and changelog on the newly added models? Thanks!
English
Getting back into benching some of the models that came out this year so far. Results are coming this next week, starting with K2.5. :)
English
@Oktai15 FYI, just wanted to follow-up. I'm very interested in the results. Just need a little bit of time. 200k results might come out soon-ish, with 1M at a later date.
English

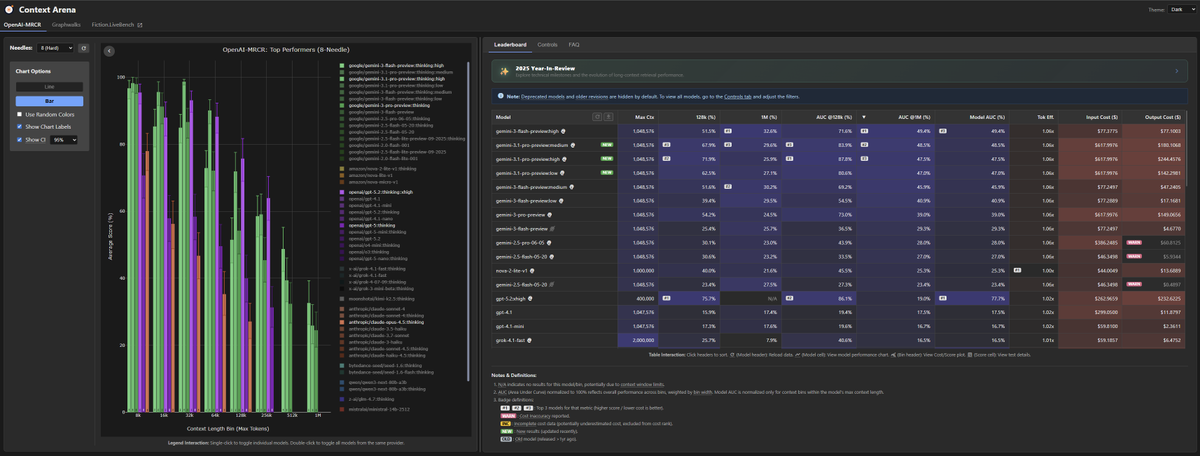
Context Arena: 2025 Year-In-Review ❄️
Inspired by the personalized recaps this year, I’ve put together a fun little technical recap into everything that happened in the arena! Plus a few new charts.
Explore the technical milestones of 2025:
contextarena.ai/2025
This was also fun experiment in building with AI: 3 different models had access to the full dataset to help craft the experience. The 'Leader' categories were curated by @AnthropicAI's Claude 4.5 Opus & @GoogleDeepMind's Gemini 3 Pro, and the majority of the code was generated by them, and prettified/tweaked by Gemini 3 Flash.
Note on data integrity: While models handled the presentation, the rankings are objective. All data is pulled via live database queries and double-checked for accuracy.
Enjoy! Hope you all like it!
And again, appreciate all of the help given this year! Happy Holidays!


English
@zzhonglol Hey Zhong! We just need an API endpoint to run the evaluation. We don't have public submission set up yet, but it's on our to-do.
Is an API endpoint something we can discuss?
English

@DillonUzar Hi Dillon! I am Zhong from Modelbest. We are preparing to release MiniCPM4.6, What is the specific format for model submission and evaluation on Context Arena leaderboard? Once the evaluation is complete, what is the procedure for including the model on the leaderboard?
English



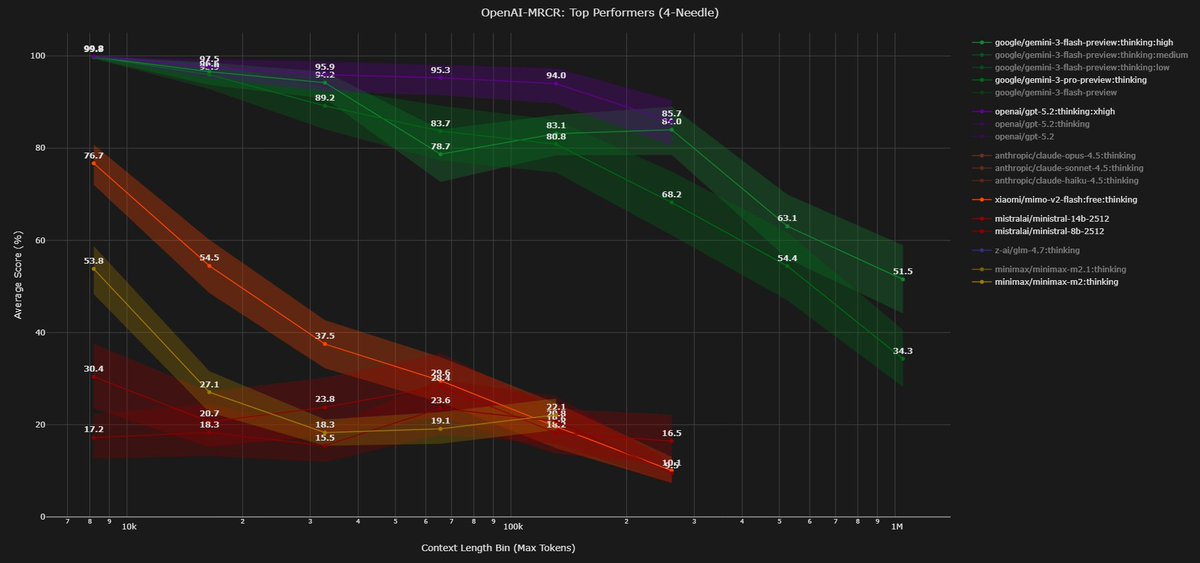
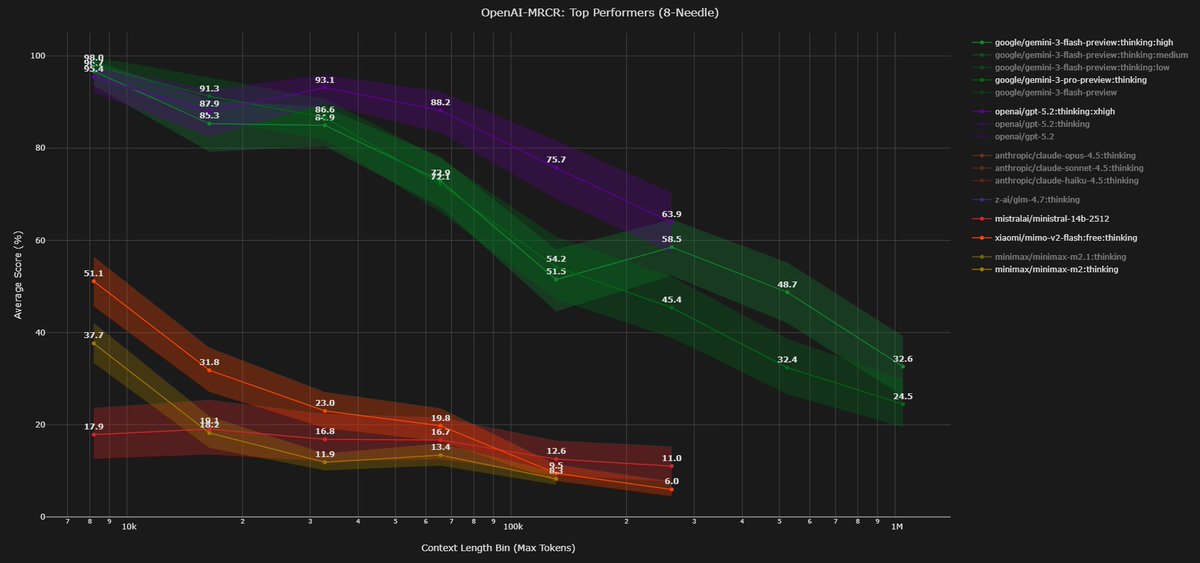
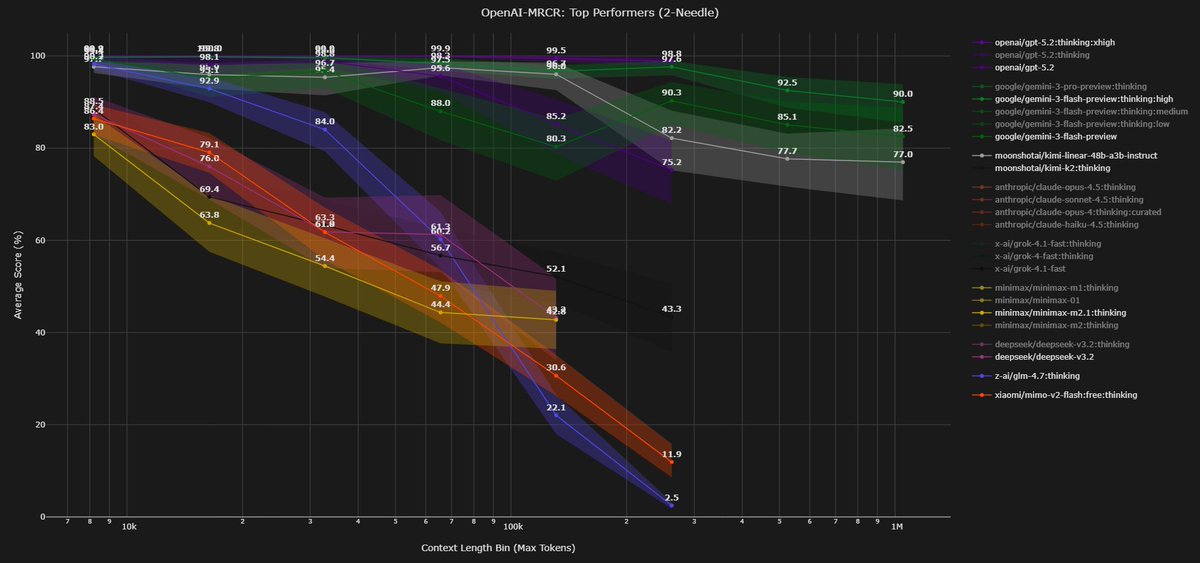
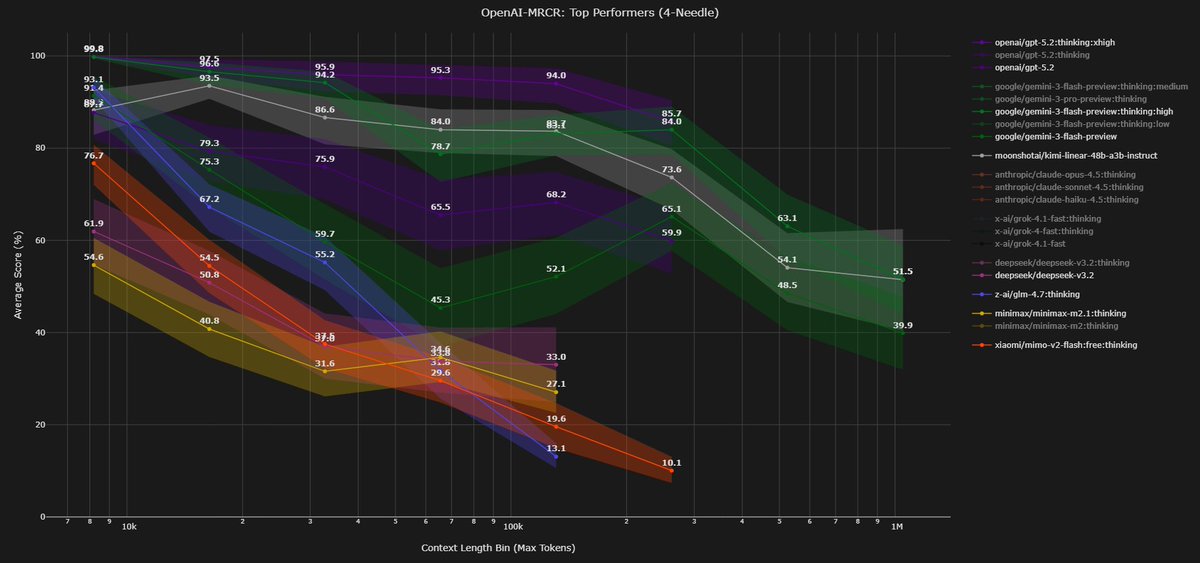
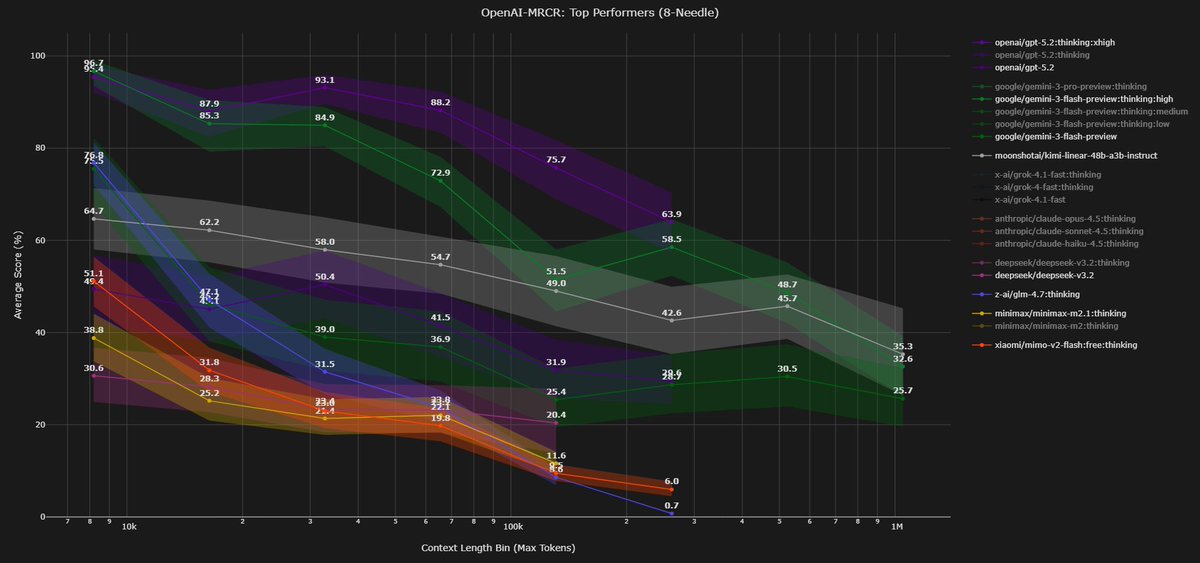
Looking at how different training choices impact long context using the openai MRCR bench (2 needle)
1) full attention vs hybrid
-> Kimi linear >>> K2 thinking
-> Qwen3 next > Qwen3 MoE
differences between the two setups:
- Kimi MLA for global (with NoPE) vs gated attention for Qwen
- Kimi delta net attention (KDA) vs gated delta net (GDA) for Qwen
- Kimi linear is not really overtrained, it is only on 5.7T tokens, whereas Qwen3 next is on 15T tokens. other things like sparsity and total params could also have an impact here
Kimi linear is really an outlier compared to all the other open models.
-> Minimax M1 >> M2/M2.1
despite the Minimax team saying that linear attention falls short on more complex "reasoning" bench, simple linear attention still performs better on MRCR. other factors could also matter here, like M1 being much bigger than M2. note that M2 uses QK Norm (should hurt LC) but with partial RoPE (should help LC)
2) post training
-> for deepseek (v3): instruct < thinking
-> for Minimax M1: instruct > thinking
-> M2.1 > M2: M2.1 is more "agentic" RL training, which is likely to involve quite long sequences
3) thinking budget / reasoning effort
-> v3.2 >> v3.2 speciale
-> (not shown in the graph) {gemini 3 flash, gpt5} high reasoning > {...} low reasoning
thinking more seems to lead to better performance on MRCR tasks for closed models, but it does not seem to work for deepseek, tho deepseek speciale is different than just a higher reasoning budget iiuc
4) other models not shown here and disclaimer
-> you can see GLM 4.7 and Xiaomi Mimo Flash v2 in recent @DillonUzar post (follow him, he is the one maintaining the context arena that reports all those evals!!). i’d say that Xiaomi is not bad considering the very small SWA size and the 5:1 ratio
-> training at a longer (> target) ctx length seems to be a good way to improve perf at the target context length
-> scaling params and training tokens is definitely not the answer to improve results on MRCR, see Kimi linear, tho i think it helps in a way obviously
-> i can't measure the impact of data, which is probably, as always, the biggest factor of improvement
-> MRCR is not representative of how you want your model to perform at long context in real life, but i think it is an ok proxy

English
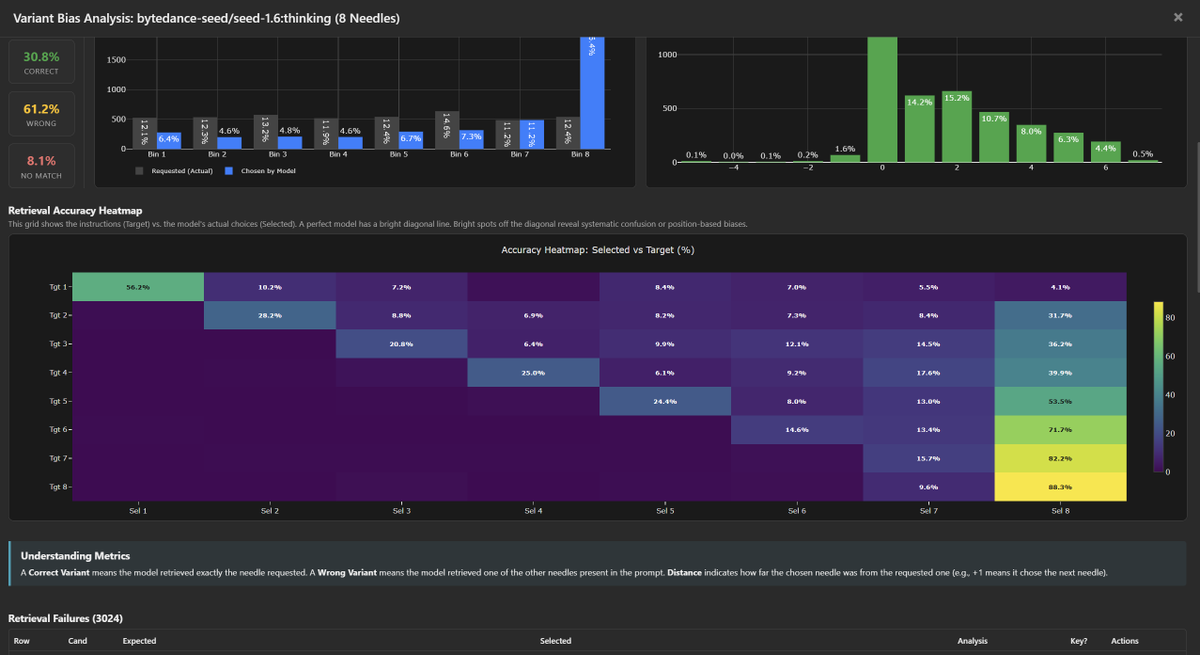
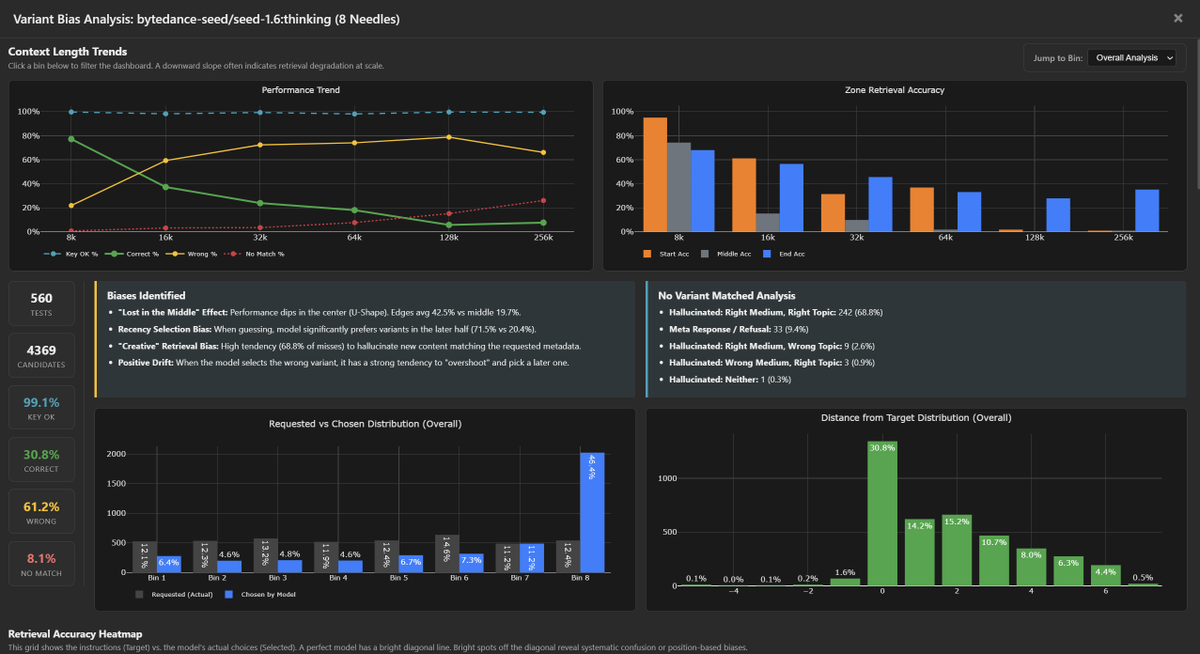
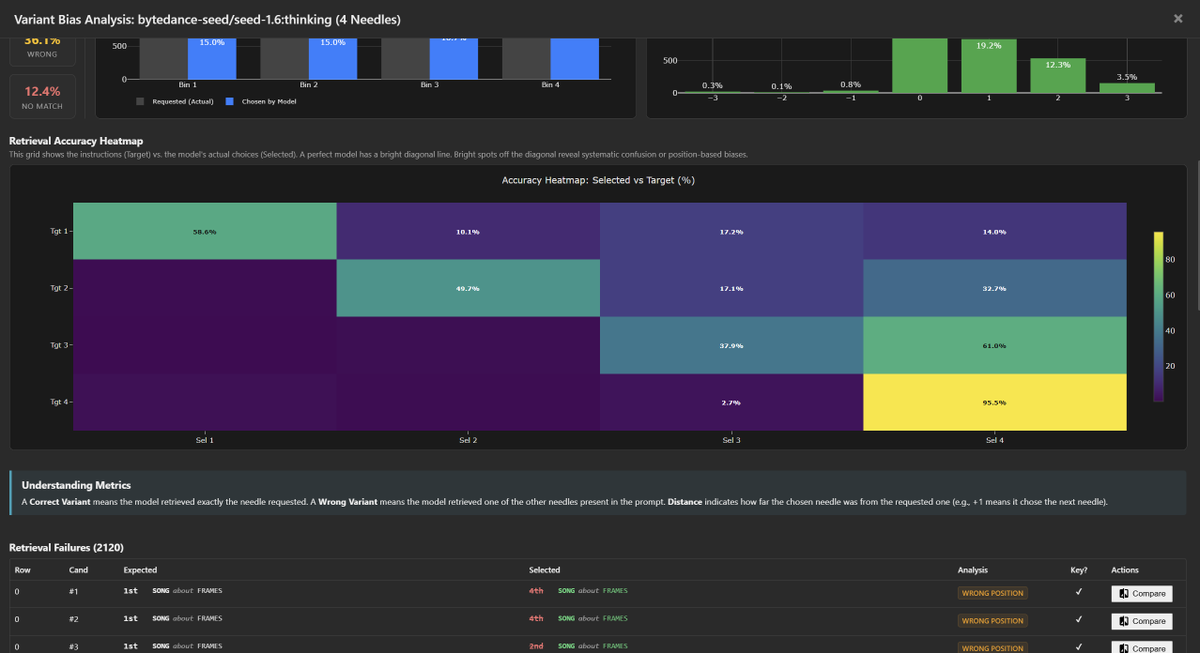
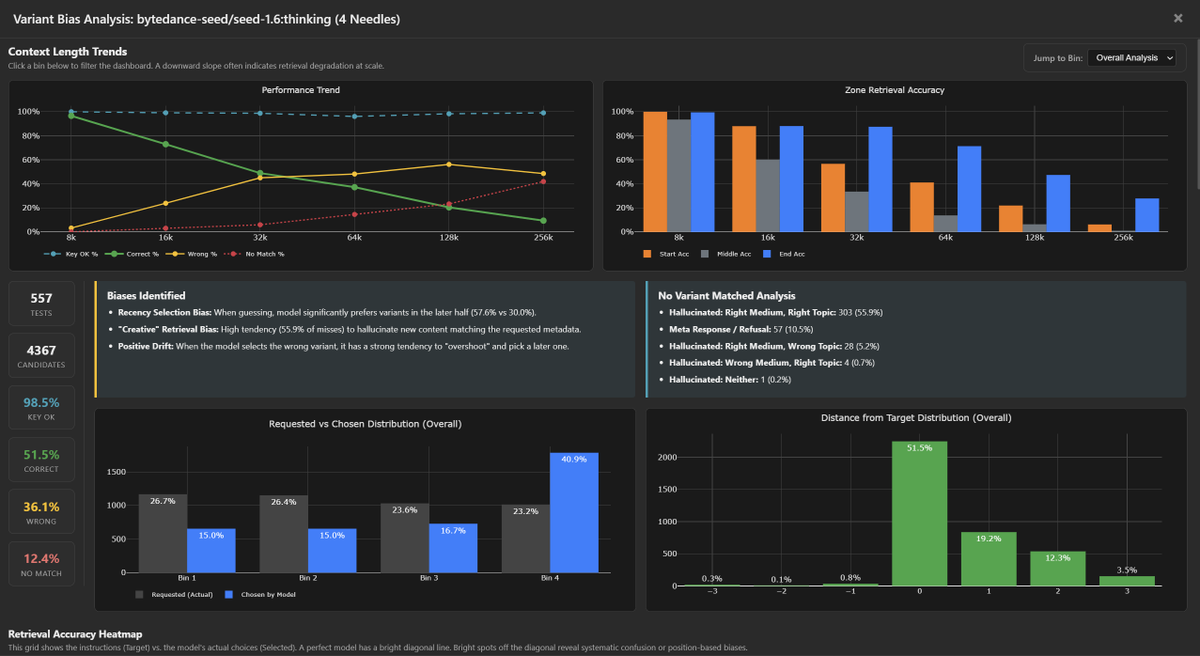
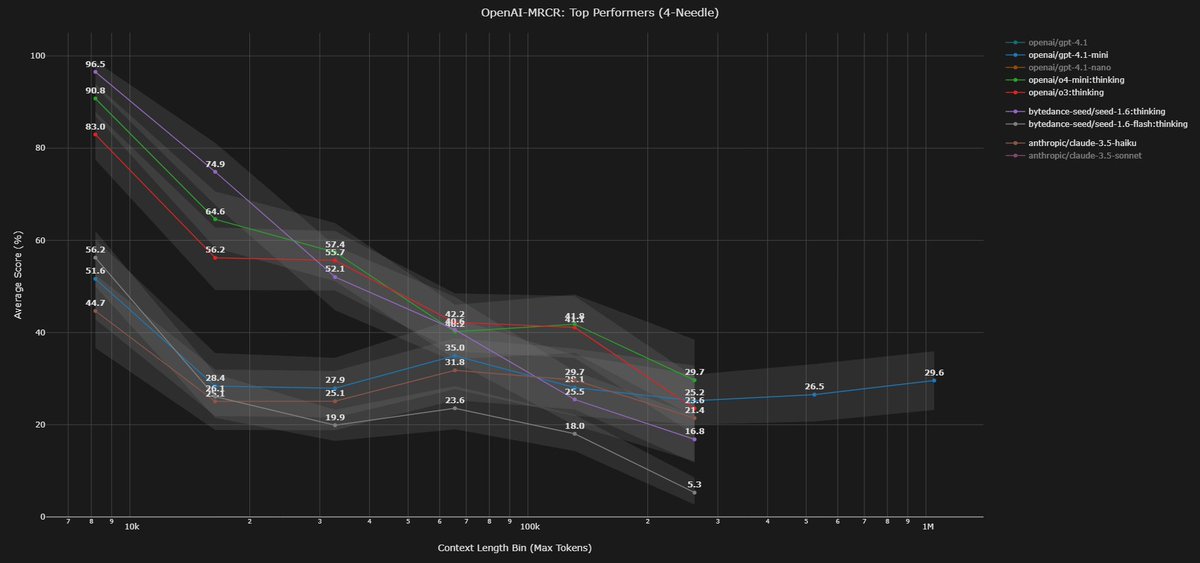
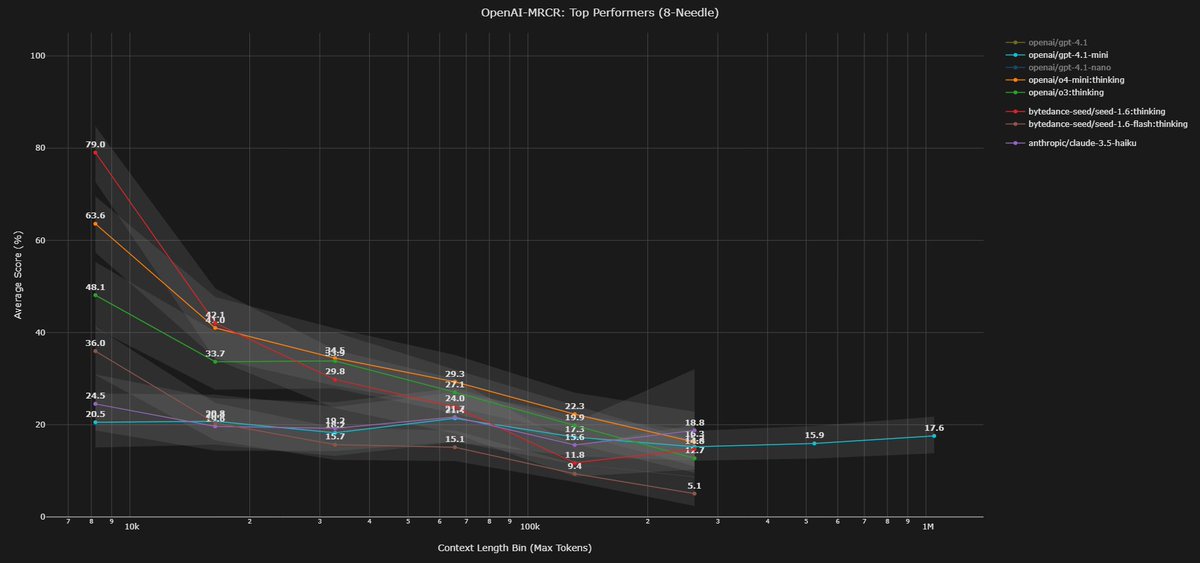
Diving deeper into bytedance-seed/seed-1.6:thinking bias / tendencies.
This model shares the "Positive Drift" pathology of the budget tier, but with one of the strongest "Lost in the Middle" effect.
Like many other models, both Seed-1.6 and Seed-1.6-Flash suffer from picking newer variants over the correct variant (usually picking the latest variant).
- 4-Needle Tgt 3: Returns Last (4) 61.0% vs Correct (3) 37.9%.
- 8-Needle Tgt 5: Returns Last (8) 53.5% vs Correct (5) 24.4%.
- 8-Needle Tgt 6: Returns Last (8) 71.7% vs Correct (6) 14.6%.
@ByteDance
English
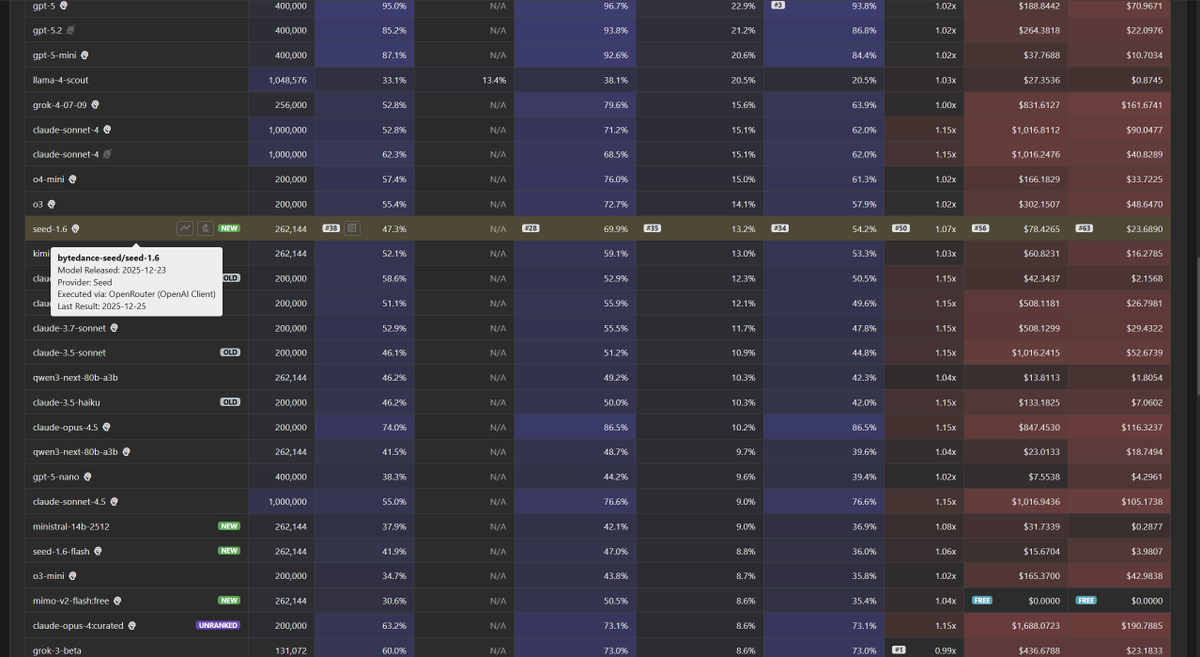
Context Arena Update: Added @ByteDance's Seed 1.6 and Seed 1.6 Flash to the MRCR leaderboards.
Seed 1.6 closely mimics the retrieval curve of @OpenAI 's reasoning models (o3 / o4-mini). It offers high fidelity at start, but follows a similar degradation slope as complexity increases.
Seed 1.6 Flash fits the budget tier profile defined by GPT-4.1 Mini and @AnthropicAI's Claude 3.5 Haiku. It provides good recall at short range before quickly dropping off.
bytedance-seed/seed-1.6:thinking results (@ 128k):
2-Needle Performance:
AUC: 54.2% (vs o3: 57.9%)
Pointwise: 47.3% (vs o4-mini: 57.4%)
4-Needle Performance:
AUC: 32.3% (vs o3: 39.6%)
Pointwise: 25.5%
8-Needle Performance:
AUC: 19.2%
Pointwise: 11.8%
Full data: contextarena.ai

English
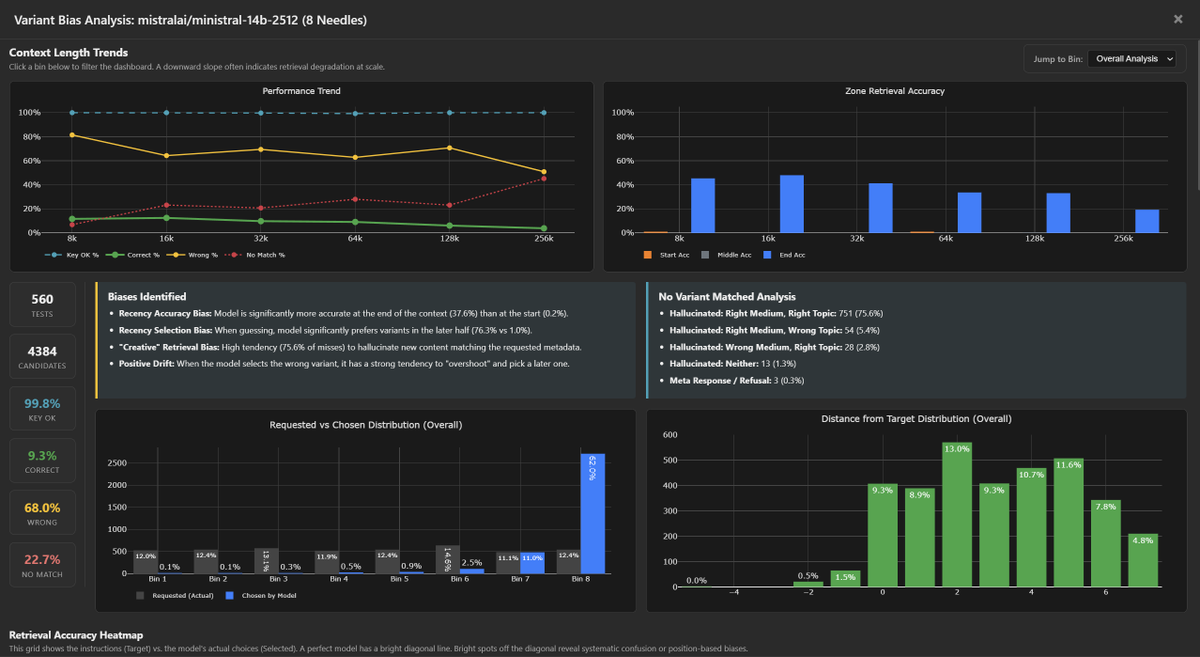
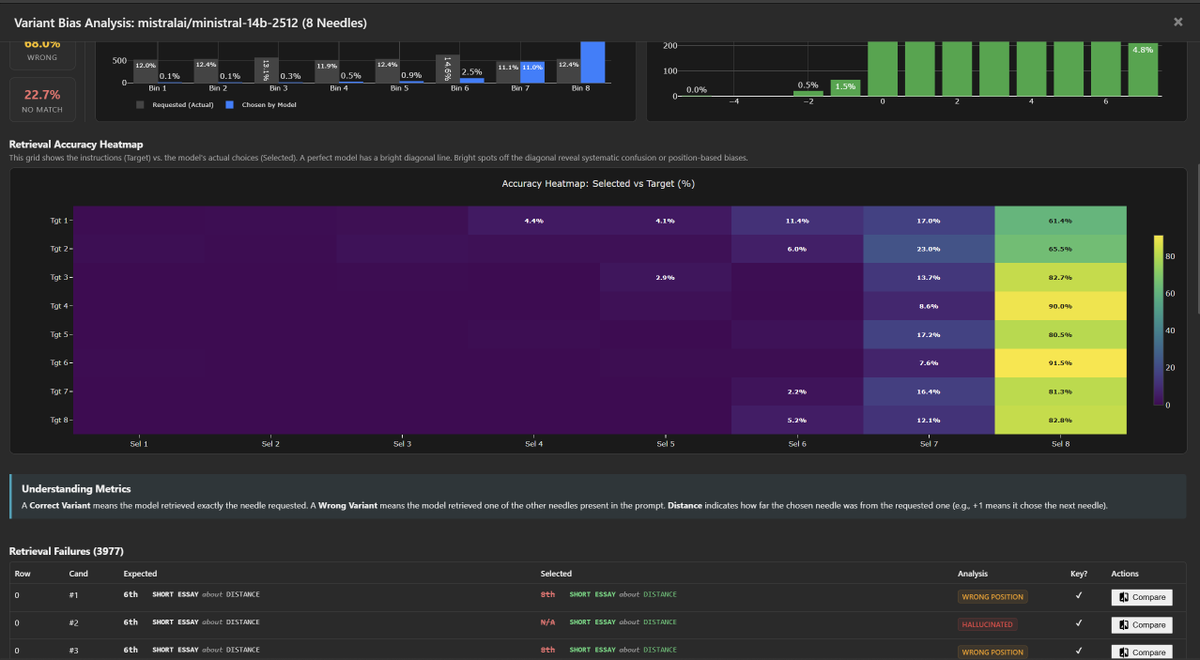
Diving deeper into ministral-14b-2512 bias / tendencies.
These models take "Positive Drift" and "Recency Selection Bias" to the limit, almost always picking the latest variant over any other, regardless of the instructions.
1. The "Final-Variant" Wall
Regardless of what is requested (Needle 1 through 8), the model overwhelmingly returns Needle 8.
- Tgt 1 → 8: 61.4%
- Tgt 4 → 8: 90.0%
- Tgt 6 → 8: 91.5%
2. Start-of-Context Blindness
The model is effectively blind to the first half of the context, but that is likely due to its recency bias when selecting a model.
- Start Accuracy: 0.2%
- Recency Accuracy: 37.6%
Takeaway: While the "flat" performance curve is a little deceptive. The model is simply defaulting to the last thing it saw, almost every single time.
@MistralAI
English
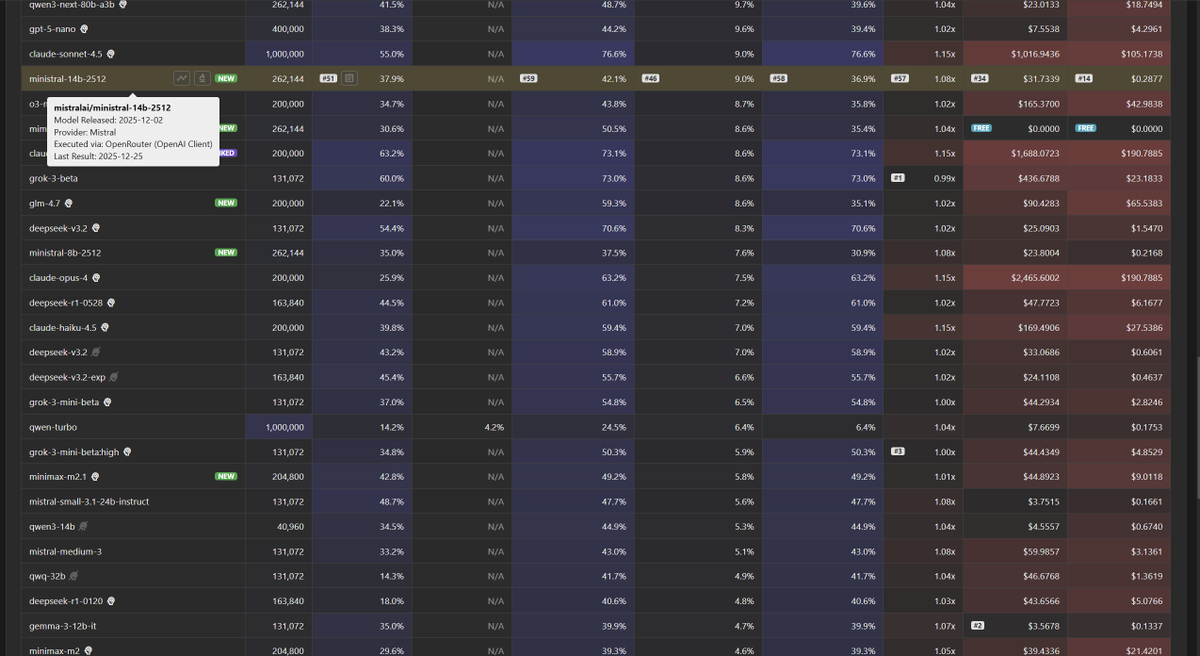
Context Arena Update: Added @MistralAI's: Ministral-14b, 8b, and 3b.
Ministral's curve is rather flat, maintaining the same level across all context lengths. (However, see the next tweet)
Scaling returns are diminishing: The 14B model offers very little tangible retrieval advantage over the 8B variant, with both tracking nearly identical paths.
Ministral-14b-2512 results (@ 128k):
2-Needle Performance:
AUC: 42.1% (vs Mimo V2: 50.5%)
Pointwise: 37.9% (vs Ministral 8b: 35.0%)
4-Needle Performance:
AUC: 24.1% (vs Mimo V2: 32.6%)
Pointwise: 18.2% (vs Ministral 8b: 20.8%)
8-Needle Performance:
AUC: 15.9%
Pointwise: 12.6%
Full data: contextarena.ai

English
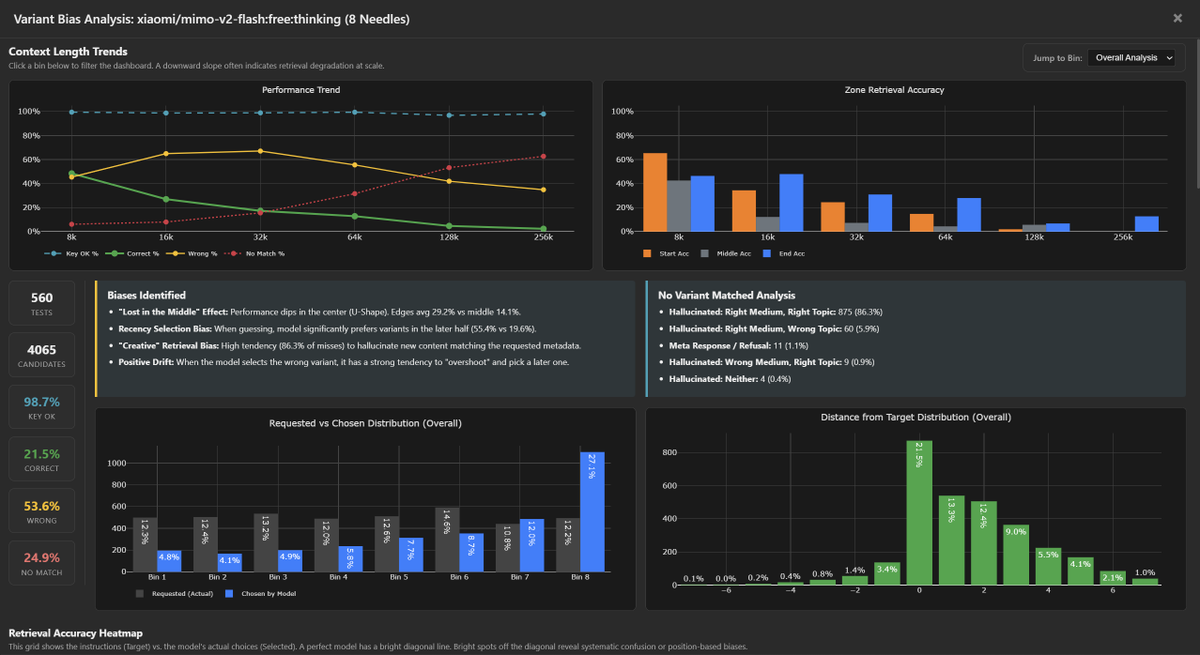
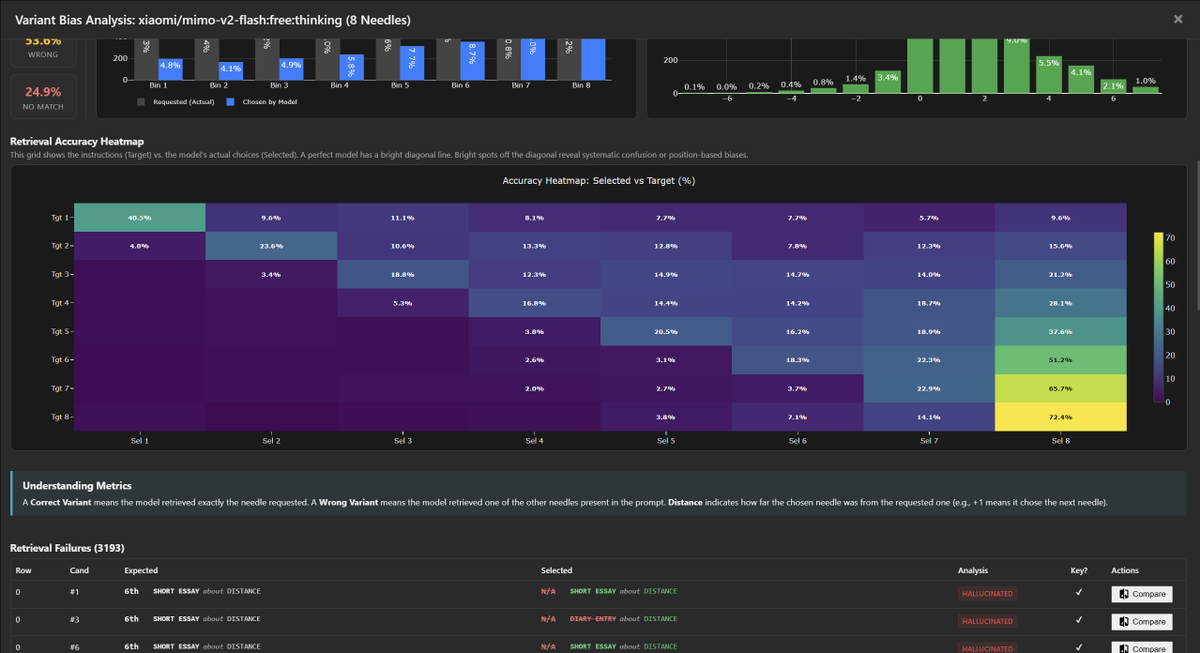
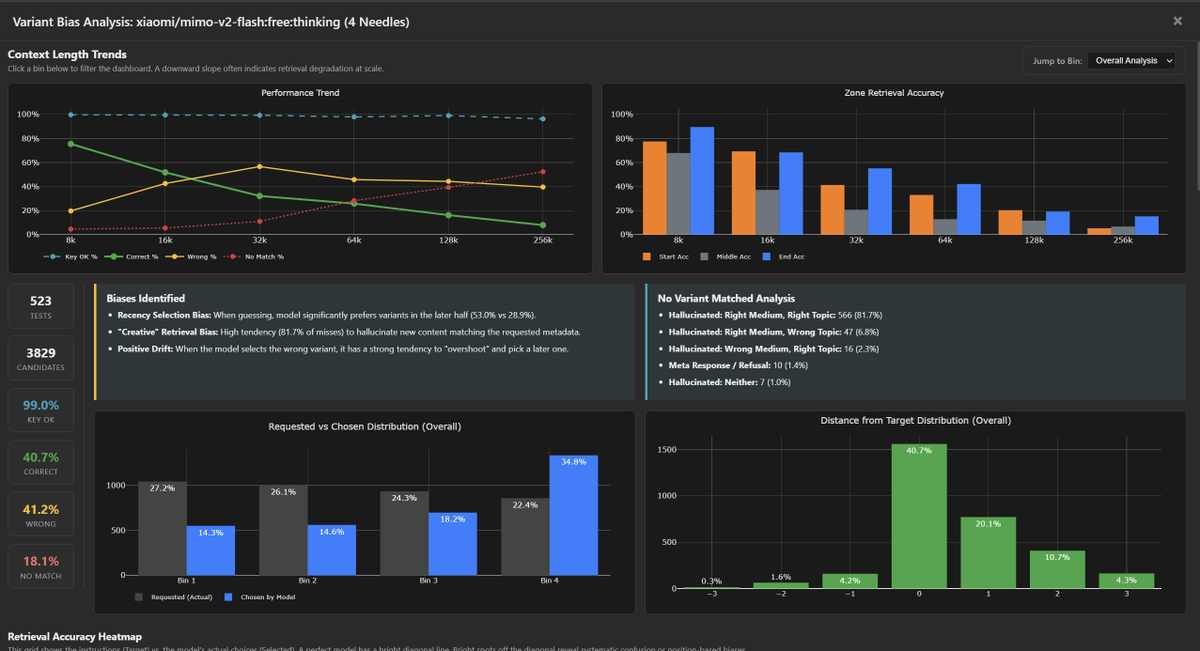
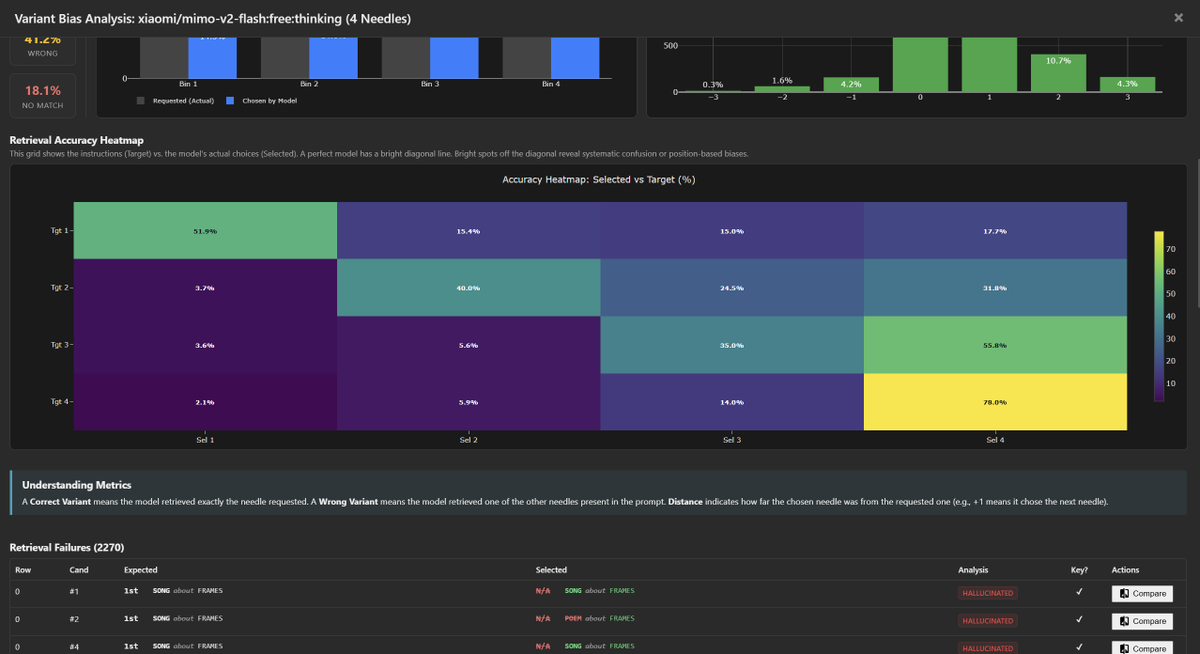
Similar to MiniMax, we see two distinct characteristics: Extreme "Positive Drift" and "Creative Overreach."
1. Positive Drift / Forward Bias
The model displays a severe preference for the final variant in the context. When confused, it anchors to the last entry rather than just the next one.
- 4-Needle: Tgt 3→4 (55.8%) vs Tgt 3→3 (35.0%)
- 8-Needle: Tgt 6→8 (51.2%) vs Tgt 6→6 (18.3%)
2. "Creative" Biases
Mimo is instruction-compliant regarding keys, but suffers from confident confabulation when retrieval fails:
- Key Hash Stability: Better than M2.1. It successfully outputs the verification key ~99% of the time.
- Creative Hallucinations: In ~81-86% of misses, it invents a *new* needle (Right Topic/Medium) rather than retrieving.
- Refusals: Extremely low (~1%). Unlike a few other models, it almost never breaks character to ask for clarification.
Reviewing the hallucinations, the reasoning is often opaque. The model simply generates a random variant in it reasoning that fits the requested format (Topic/Medium) to fill the gap, without a clear indication in the chain-of-thought of where it originated.
Attached is the 8-needle and 4-needle bias analysis.
@Xiaomi
English
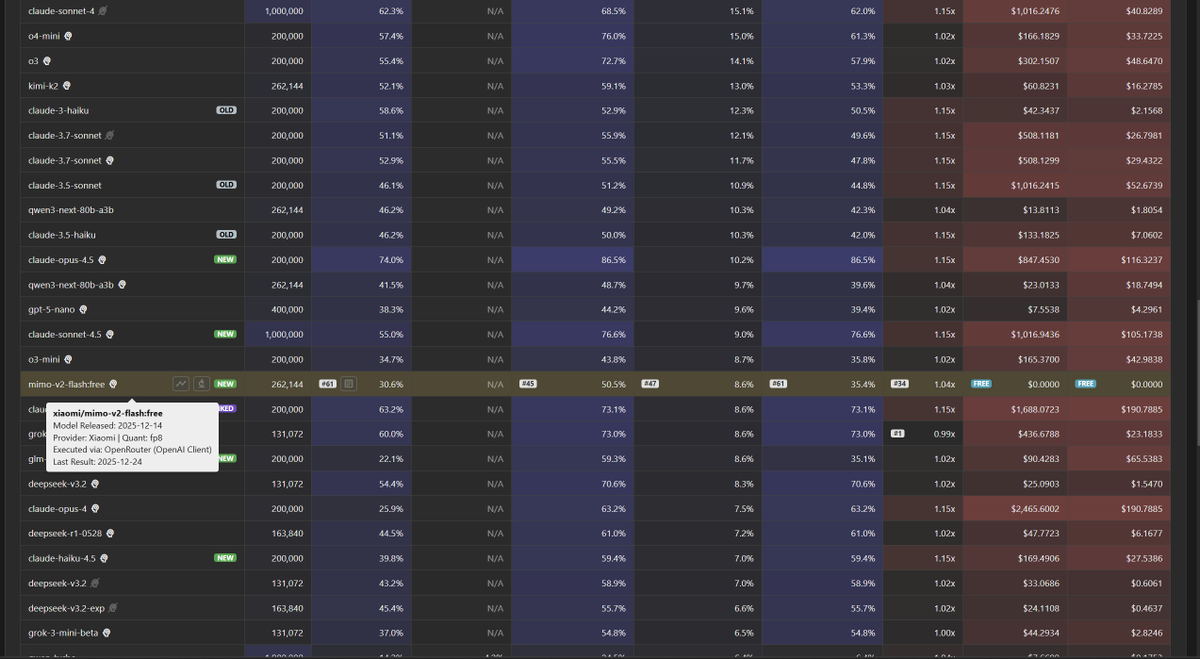
Context Arena Update: Added @Xiaomi's mimo-v2-flash [12-14] to the MRCR leaderboards (2-, 4-, 8-needle).
Currently listed as free (on @openrouter), and $0.10 per 1M input and $0.30 per 1M output otherwise, Mimo delivers surprising utility before the context curve steeply degrades.
Its retrieval profile tracks remarkably close to @minimax_ai's M2.1, while using roughly double the reasoning tokens. Mimo matches M2.1's stability (AUC) across all tests, allowing it to edge out @GoogleDeepMind's Gemini 2.5 Flash Lite Thinking in overall retention.
2-Needle Performance (@ 128k):
AUC: 50.5% (vs MiniMax M2.1: 49.2%)
Pointwise: 30.6% (vs Gem 2.5 Flash Lite Think: 39.6%)
4-Needle Performance (@ 128k):
AUC: 32.6% (vs MiniMax M2.1: 33.3%)
Pointwise: 19.6% (vs Gem 2.5 Flash Lite Think: 25.5%)
8-Needle Performance (@ 128k):
AUC: 19.9%
Pointwise: 9.5%
Full data: contextarena.ai
English