あお / ao retweetledi
あお / ao
11.3K posts


あお / ao
@urora_blue
data scientist at 製造業🏭/ 2児のパパ / kaggle comp& discussion expert 🥈×2🥉×4/ 興味 : CV, 物理×機械学習 / 社会人博士🎓🐊
Katılım Kasım 2021
901 Takip Edilen529 Takipçiler

あお / ao retweetledi

LeWorldModelは画像から直接学習する新しいJEPA型世界モデル。予測損失+SIGReg正則化の2項のみで安定訓練し、15Mパラメータ・1GPUで学習可能。基盤モデル系より最大48倍速い計画を実現し、多様な制御タスクで高性能。
docswell.com/s/DeepLearning…
日本語
こういった記事にTabPFNとかのテーブル特化の深層学習モデルが登場しないのはなぜだろう?
※ツリー系の方が枯れた技術であり、いろいろな応用(解釈性とか)があるので一般的であるとは思ってる
zenn.dev/mkj/articles/f…

Kan Nishida 🇺🇸❤️🇯🇵@KanAugust
深層学習がすべてを置き換える。 私もそう思っていました。 画像、自然言語、音声。 あらゆる分野で圧倒的な成果を出してきた深層学習。 だからこそ、ビジネスの予測モデルでもいずれ主役になると。 しかし、現実は少し違います。 顧客データや売上データのような「表形式データ」の世界では、 精度の高い予測モデルを作りたいというとき、 いまだにXGBoostやLightGBMなど、ツリー系のモデルが一般的に使われます。 なぜ、最も進化しているはずの深層学習が、 ここでは勝てないのでしょうか? 答えはシンプルです。 データの構造が違うからです。 深層学習が得意なのは: 画像(空間的な構造) テキスト(順序・文脈) のように、意味のある構造を持つデータです。 一方で、表形式データはどうか? 年齢 収入 購買履歴 地域 これらは単なる「変数の集合」であり、画像や言語のような構造はありません。 つまり、 深層学習がうまく機能する前提そのものが、存在していないのです。 逆に、 XGBoostやLightGBMといったツリー系モデルの場合は、 「年齢 > 30 かつ 購買回数 > 3 なら…」 といった、 ルールベースのパターンを見つけるのが得意です。 そして現実のビジネスデータは、まさにこうしたルールの集合でできています。 アルゴリズムに優劣があるのではなく、 データに適材適所がある。 AIがどれだけ進化しても、この原則は変わりません。 むしろ今は、 「どのモデルを使うか」よりも 「どんなデータを扱っているか」を理解する方が重要です。 もしあなたが、 とりあえず深層学習を使って、一般的なビジネスデータに対して 予測モデルを作ろうとしてるが、精度が伸び悩んでいる のであれば、一度立ち止まってみてください。 そのデータ、本当に深層学習向きですか? このテーマについて、 より詳しく整理した記事を書きました。 qiita.com/KanNishida/ite…
日本語
あお / ao retweetledi

あれだけ大量の画像・動画をアップロードさせて、「S3のコストをどう抑えてるんだ?」ってずっと疑問だったけど、結局はライフサイクルルールで日数ごとにストレージクラスを移動という、めちゃくちゃ堅実な運用で凌いでた。ストレージクラス設計はマジでバカにできないな。
speakerdeck.com/fanglang/jia-z…
日本語
あお / ao retweetledi

我らがpytorch lightningにマルウェアが⋯
直近(2026年4月29日〜)バージョン指定なく最新版入れた、みたいなケースだと該当しそう⋯
YONEUCHI, Takashi@lmt_swallow
【侵害続報】下記パッケージにマルウェアが仕込まれています。インストールがないか、是非確認ください🙇 ・PyPI の lightning 2.6.2 及び 2.6.3(PyTorch 関連で利用されている。Quarantine 中) ・npm の intercom-client 7.0.4(ヘルプデスク、チャットボット系。未テイクダウン) 複数筋で TeamPCP に帰属され、共に月間10万超以上のDLがあります。なお Takumi Guard でもブロック済&ユーザーには実害がないことを確認してあります。 IoC (Exfil): zero[.]masscan[.]cloud
日本語

あお / ao retweetledi

codex appが使いやすいという噂がありちょっと使ってみたけど、自分には合ってない感じだなー
コード見なくてもいいという人や一つの画面でいろんなcodexの作業をマネージしたい人には向いているのかね
あお / ao@urora_blue
codex appからssh先のGPUサーバーのコンテナに接続できたぞ!
日本語
あお / ao retweetledi

あお / ao retweetledi

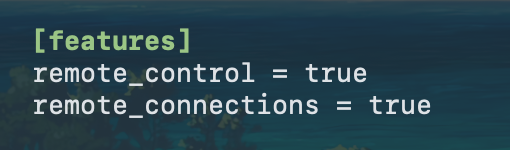
Codex App で SSH を使うやつ、どうも codex features に書いてある remote_control キーは使われなくて remote_connections (s 付きなことに注意!) が必要らしい
これを指定したら出てくるようになった
日本語
あお / ao retweetledi

Our W&B LEET TUI went viral.
So we made it way more powerful.
The big new unlock is workspace mode.
› Multi-run workspace. Live.
› Metadata filtering.
› System metrics.
› Console logs.
› Images in the terminal.
All in one workspace. All in your terminal. 🧵
English
あお / ao retweetledi

羽生さんの言語化力は相変わらず傑出している。研究にも通じる金言多数。
『差別化やオリジナリティーを出すということは、AI評価においてマイナスの手を意図的に選ぶことを意味する。AIの評価が低いことをどこまで許容するか。羽生氏は「マイナス500点だとちょっと受け入れられないけど、マイナス200点ぐらいならいいかな」と話す。その線引きに個性が生まれるのかもしれない。』
『自分が指したい将棋というものもある。攻撃的な将棋を指したいといった自分のスタイルを、いくらAIの評価が低くても、それはそれで貫いて指していくことも大事だと思います』
『AIの評価値は人間の目から見ると楽観的すぎるのです。AIが90%有利と出していても、人間の感覚では五分みたいなものがいくらでもある。(AIには)不安とか恐怖心が全くないので』
『人間はこれまで積み上げてきた美意識や美学、こだわりの中から手を選んでいるので、見にくい手、生理的に受け付けない手、違和感のある手を選ばない傾向がある。もしかするとそこに本当の宝の山があるかもしれない』
『その瞬間その瞬間で評判の高いことをやっていくのは選択肢として悪くないですが、10回、20回の選択の連続で見ると、一貫性がなく何を考えているのか分からないということになりかねない。過去から現在に至るまでを総括して、どういう方針や選択ができていたかを振り返り、それを基に次に何をやるかを考えていく。首尾一貫していることも一つの基準になります』
『AIを活用するというと、面倒なことを代わりにやってもらうケースが多い。人間の才能や能力、ポテンシャルを伸ばすという使い方はあまりされていない。教育や才能を伸ばす方向にも活用していけたら、すごく可能性があるんじゃないか』
#utm_term=share_sp" target="_blank" rel="nofollow noopener">itmedia.co.jp/enterprise/spv…
日本語
あお / ao retweetledi
