Volodymyr T retweetledi

Shoutout to the community for making a product on Train at Home -- A whole tool to monitor the entire TAH fleet, alpha flows, and training states! trainathome.ai/en

English
Volodymyr T
271 posts






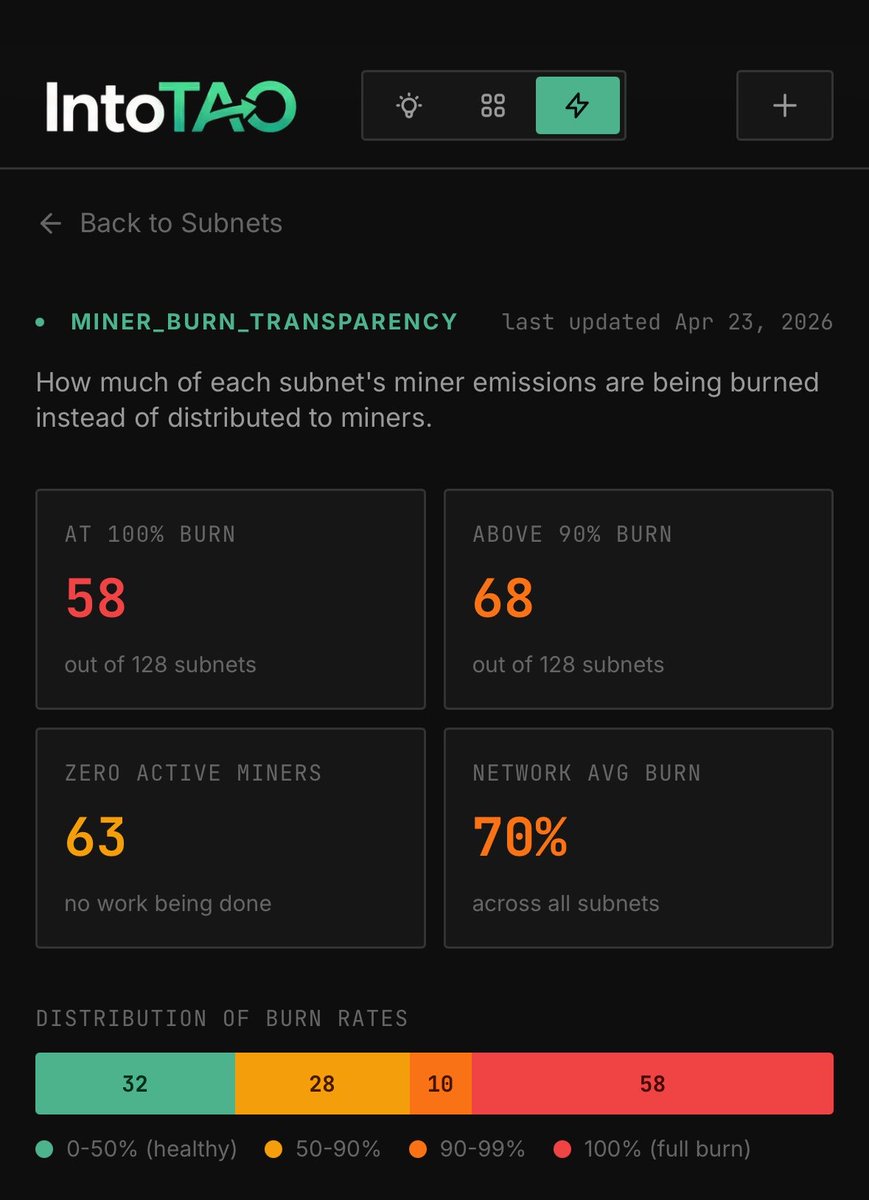
Most bittensor subnets have had miner burn at 100% for months. Many of them have been on podcasts and garnering attention, with no product in sight. Ask subnet owners why you should hodl their token when they launched a subnet that wasn't ready yet. If you hodl their alpha, you are the exit liquidity


thank you to @DCGco for hosting an incredible summit and for inviting me to participate in “The Tipping Point: From Experiments to Category Leaders” alongside @tm0klc (@manakoai) and @macrocrux (@MacrocosmosAI), moderated by @LindsMikeStone once again reminded of the amazing people building this ecosystem and shaping the future of decentralized technology grateful for the opportunity to share what we’re building @metanova_labs with the power of #bittensor leaving inspired, with many great new connections * future is bright *


Exciting news - GPT-Image-2 by @OpenAI has claimed the #1 spot across all Image Arena leaderboards! A clean sweep with a record-breaking +242 point lead in Text-to-Image - the largest gap we’ve seen to date. - #1 Text-to-Image (1512), +242 over #2 (Nano-banana-2 with web-search aka gemini-3.1-flash-image) - #1 Single-Image Edit (1513), +125 over #2 (Nano-banana-pro aka gemini-3-pro-image) - #1 Multi-Image Edit (1464), +90 over #2 (Nano-banana-2) No model has dominated Image Arena with margins this wide. Huge congratulations to @OpenAI on this major breakthrough in image generation! More performance breakdowns by category in the thread below.

Welcome Salesforce Headless 360: No Browser Required! Our API is the UI. Entire Salesforce & Agentforce & Slack platforms are now exposed as APIs, MCP, & CLI. All AI agents can access data, workflows, and tasks directly in Slack, Voice, or anywhere else with Salesforce Headless 360. Faster builds, agentic everything. 🚀 #Salesforce #Agentforce #AI venturebeat.com/ai/salesforce-…





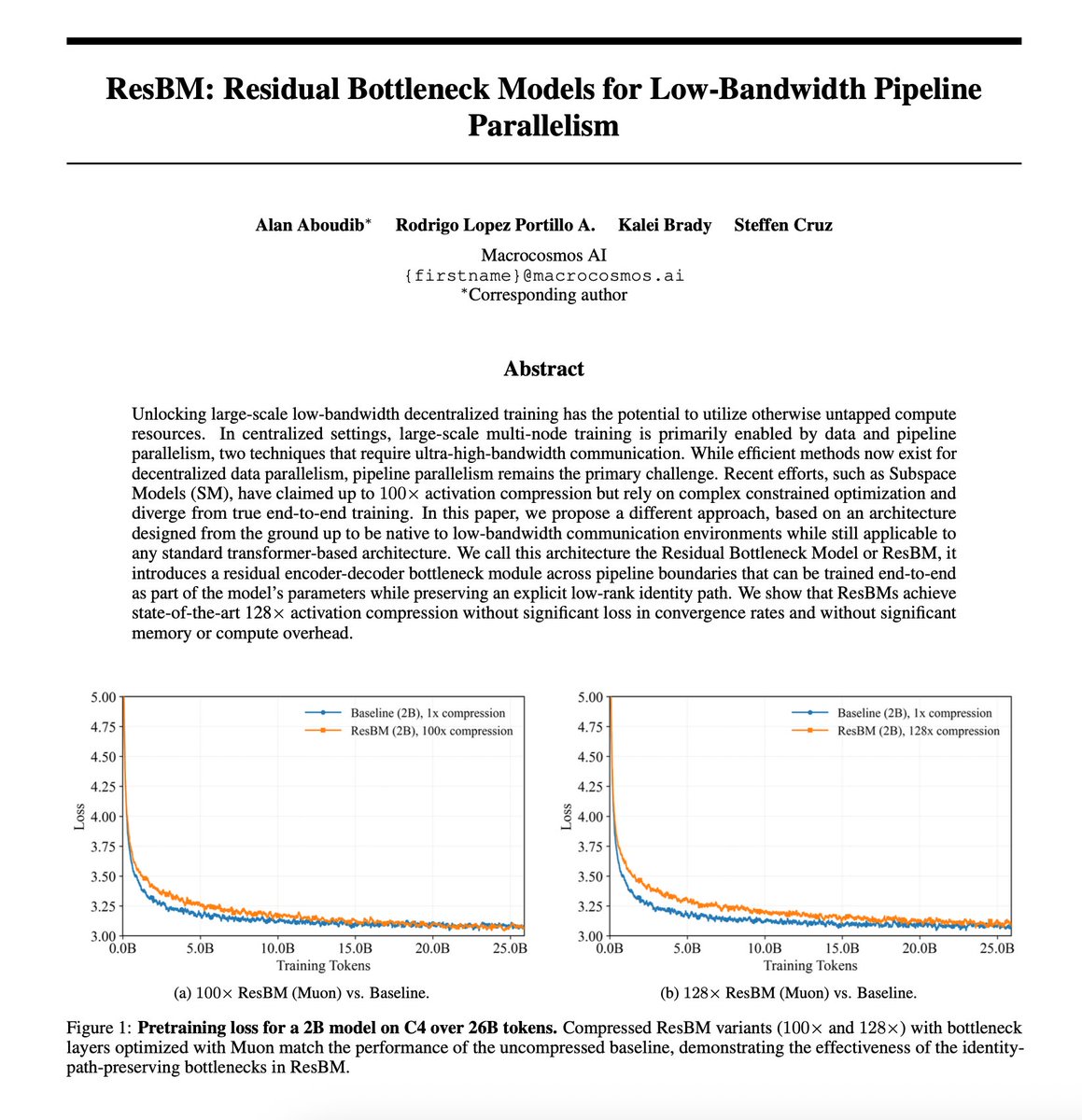
Training frontier models over the internet requires new techniques. Today, we present ResBM, a residual encoder-decoder bottleneck architecture that enables 128x activation compression for low-bandwidth distributed pipeline parallel training. Developed for @IOTA_SN9, we show SOTA compression without significant loss in convergence rates, increases in memory, or compute overhead. Expect the full paper release in the next 72 hours.