@hijunedkhatri @zomato @letsblinkit please tell me its not like all the other platforms that its 99% the case that the hiring team doesn't respond?
English
hypyaml
178 posts
@vbppl
horrendous at coming up with good variable names. wannabe (cracked eng)







We implemented @karpathy 's MicroGPT fully on FPGA fabric. No GPU. No PyTorch. No CPU inference loop. Just a transformer burned into hardware, generating 50,000+ tokens/sec. The model is small, but the idea is not: inference does not have to live only in software 👇











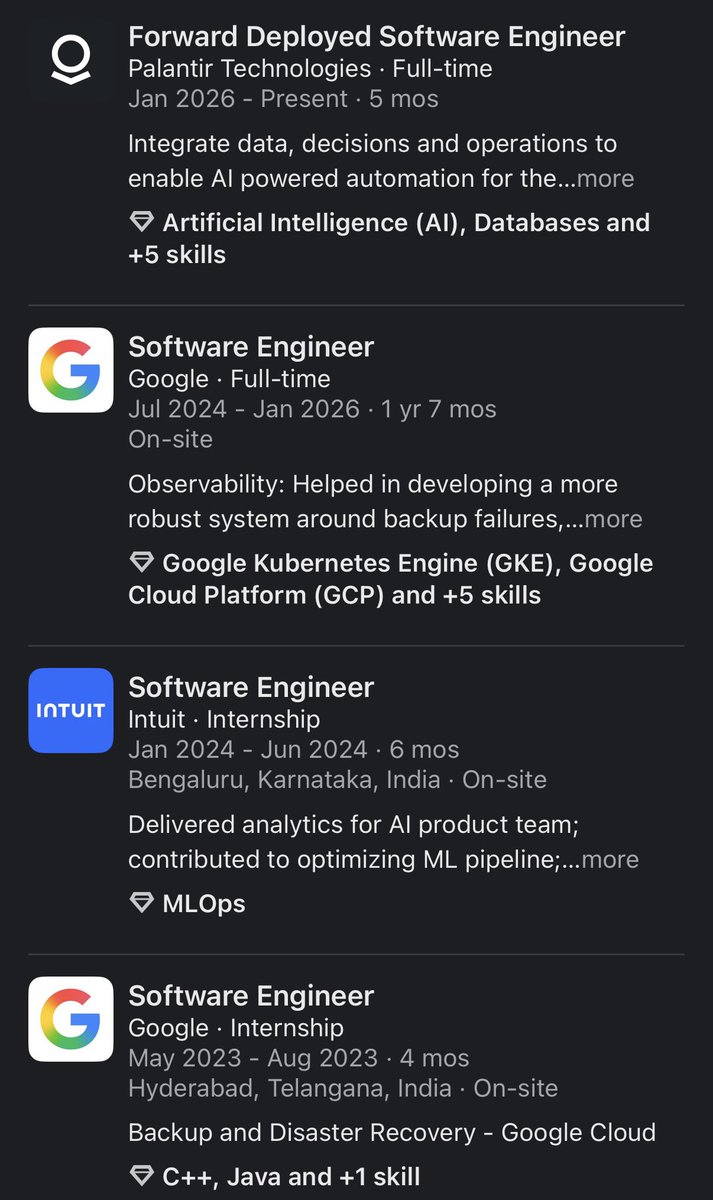
Anu is working at Palantir now😯