
Vadim Borisov, PhD
280 posts

Vadim Borisov, PhD
@vdmbrsv
co-founder @tabularis_ai
Tübingen, Germany Katılım Ocak 2016
834 Takip Edilen837 Takipçiler
we accepted ugly progress bars for 10+ years
time to fix that
chugchug 🚂 is here, finally
pip install chugchug
GIF
English
Early preview. If you're running LLM APIs, high-volume inference pipelines, or just tired of watching your dataset tokenization progress bar crawl -- reach out, happy to set up a demo.
#LLM #MLOps #Inference
English
Numbers:
43× faster than tiktoken on short prompts
~12× lower encode latency
~14× lower decode latency
~6× faster batch throughput
Drop-in replacement for HuggingFace tokenizers.
English
We built tuetoken -> a tokenizer up to 43× faster than tiktoken (@OpenAI) and @huggingface tokenizers. Early preview.

English
Vadim Borisov, PhD retweetledi

Introducing the Synthetic Data Playbook: We generated over a 1T tokens in 90 experiments with 100k+ GPUh to figure out what makes good synthetic data and how to generate it at scale
huggingface.co/spaces/Hugging…

English
Vadim Borisov, PhD retweetledi

This paper introduces YapBench, a benchmark that measures when LLM chatbots add needless extra text to simple prompts.
Many of these chatbots answer tiny requests with long filler that wastes attention and tokens, the text units many paid services bill for, because longer replies get rewarded in training.
YapBench fixes the target length for each prompt by writing a minimal sufficient answer, meaning the shortest reply that is still correct and clear.
It then counts extra characters beyond the baseline, called YapScore, which keeps comparisons fair even when models count tokens differently, and combines typical category scores into YapIndex.
The authors tested 76 assistant models on 304 prompts in 3 sets, vague inputs that should trigger a short question back, single fact questions, and 1 line coding requests.
They found typical extra length can differ by about 10 times, and newer top models were often more verbose than older ones like gpt-3.5-turbo.
The point is to make verbosity a thing that can be measured and improved, so apps can pick models that stay brief when brevity is best.
----
Paper Link – arxiv. org/abs/2601.00624
Paper Title: "Do Chatbot LLMs Talk Too Much? The YapBench Benchmark"

English
Vadim Borisov, PhD retweetledi

Do LLMs Talk Too Much?
There is a feeling familiar to almost everyone who regularly interacts with LLMs: you ask for a short answer and receive paragraphs of explanations, preambles and «just to clarify…» additions. The paper «Do Chatbot LLMs Talk Too Much?» attempts to measure this phenomenon systematically.
The authors introduce YapBench - a benchmark not about how smart the answer is, but about how much text a model generates beyond what is minimally necessary. If a question has an obvious short answer, everything else is a matter of assistant policy rather than necessity.
They collect 304 short prompts, deliberately chosen so that the ideal response should be concise. These fall into three types of situations:
• when the input is almost empty and the correct response is simply to ask for clarification
• when a short factual answer is required
• when a single one-line piece of code is sufficient
For each prompt, a minimally sufficient baseline answer is manually defined, and then the number of characters the model adds on top of that baseline is measured.
This yields the YapIndex - the median number of «extra» characters. The count is done in characters rather than tokens. Where possible, markdown is stripped out - temperature is set to 0, responses are single-turn and generated without system prompts. In other words, what is being measured is the behavioral tendency of models to say more than necessary.
The results are quite revealing.
On average, the most concise responses come from gpt-3.5-turbo (YapIndex ≈ 22.7), followed by kimi-k2, gpt-4, and grok-4-fast, while newer and ostensibly «smarter» models often turn out to be noticeably more verbose. Different types of prompts break models in different ways:
some begin «filling the vacuum» and inventing content when the input is empty,
others turn a simple fact into a mini reference article and others accompany a one-line code answer with explanations, headings, and duplicated content.
Crucially, this is not a fundamental limitation. In every category, there are models that behave cleanly and concisely. This means verbosity is not «how LLMs inherently work», but rather the result of post-training choices, preferences, and incentives that often reward answers which look more helpful, even when they are objectively redundant.
The authors also examine reasoning modes and arrive at a careful conclusion: reasoning does not necessarily make answers longer on the median, but it increases the risk of extreme cases, where a model produces an overly long response. They also observe a weak but noticeable trend: when models are plotted by release date, average verbosity slowly increases (with a correlation of about 0.21).
There is also a practical dimension. The authors calculate YapTax how many extra dollars are spent on «verbosity» per 1,000 requests. For expensive models, this is no longer negligible: for some GPT and Gemini variants, the cost amounts to several dollars purely due to excess text. In agentic systems and customer support, this turns into a quiet but persistent source of expense.
arxiv .org/abs/2601.00624

English
@Moleh1ll LLMs know everything about the world and nothing about themselves
English
Do LLMs know what they are capable of?
This paper asks a very simple question: can LLMs estimate the probability of their own success before they start solving a task? And do these estimates become more accurate as the work progresses? It turns out this is a separate ability and a poorly developed one.
The authors test it across three different scenarios, ranging from single-step problems to multi-step agentic processes.
• First, they use BigCodeBench, a set of 1,140 single-step Python tasks. For each task, the model is asked in advance to state the probability that it will succeed, and only then it actually attempts to solve the task. This allows a direct comparison between confidence and real performance.
The result is consistent across all models: all of them are systematically overconfident. Predicted success probabilities are consistently higher than actual success rates. Importantly, increasing model capability does not guarantee better self-calibration. For GPT and LLaMA families, this does not meaningfully improve. Within the Claude family there is some reduction in overconfidence, but it never disappears.
On average, they can distinguish easier tasks from harder ones better than chance. In other words, they have some sense of relative difficulty, but their absolute confidence remains inflated.
• The second experiment introduces a more realistic setting: contracts with risk.
The model receives a sequence of nine tasks. Each success earns +1, each failure costs −1. Before each task, the model must decide whether to accept or decline the contract, based on its predicted probability of success. The tasks are chosen so that success probability is roughly 50/50 - blindly accepting everything does not yield an advantage.
Here the core issue becomes clear. Even after a series of failures, models continue to believe that the next task will succeed. Their subjective probability of success stays above 0.5, despite the evidence.
Some models (notably Claude Sonnet and GPT-4.5) do end up earning more, but not because they become better at judging which tasks they can solve. Instead, they simply accept fewer tasks overall, becoming more risk-averse. Their gains come from declining more often, not from better self-assessment.
The authors also check whether the models’ decisions are rational given their own stated probabilities. And they largely are. The problem is not decision-making - it is that the probabilities themselves are too optimistic.
• The third experiment is the most relevant for agentic systems. Using SWE-Bench Verified, the authors evaluate real multi-step tasks involving tools. Models are given budgets of up to 70 steps. After each step, the model is asked to estimate the probability that it will ultimately complete the task successfully.
For most models, overconfidence does not decrease, and for some it actually increases as the task unfolds. Claude Sonnet shows this particularly clearly: confidence rises during execution even when final success does not become more likely. Among all tested models, only GPT-4o shows a noticeable reduction in overconfidence over time.
Notably, so-called reasoning models do not show an advantage in self-assessment. The ability to reason for longer does not translate into the ability to accurately judge one’s chances of success.
The overall conclusion of the paper is blunt: LLMs are already fairly good at solving tasks, but still poor at understanding the limits of their own capabilities. They can act, but they cannot reliably tell when they are likely to fail.
For future agentic systems, this matters a lot. In environments where mistakes are costly - whether in engineering, autonomous agents, or safety-critical settings - the ability to avoid hopeless scenarios may be more important than peak problem-solving ability.
For now, poor self-calibration acts as a limiting factor. But if this capability improves rapidly, the consequences will be significant.

English

As an area chair of #ICLR2026, it is just insane to see people replying 50 responses in a single paper... Figuring out whether they have addressed any reasonable concerns is now almost impossible. I strongly recommend future conferences to limit the number of responses to make our community more sustainable, considering how submissions grow every year @iclr_conf
English

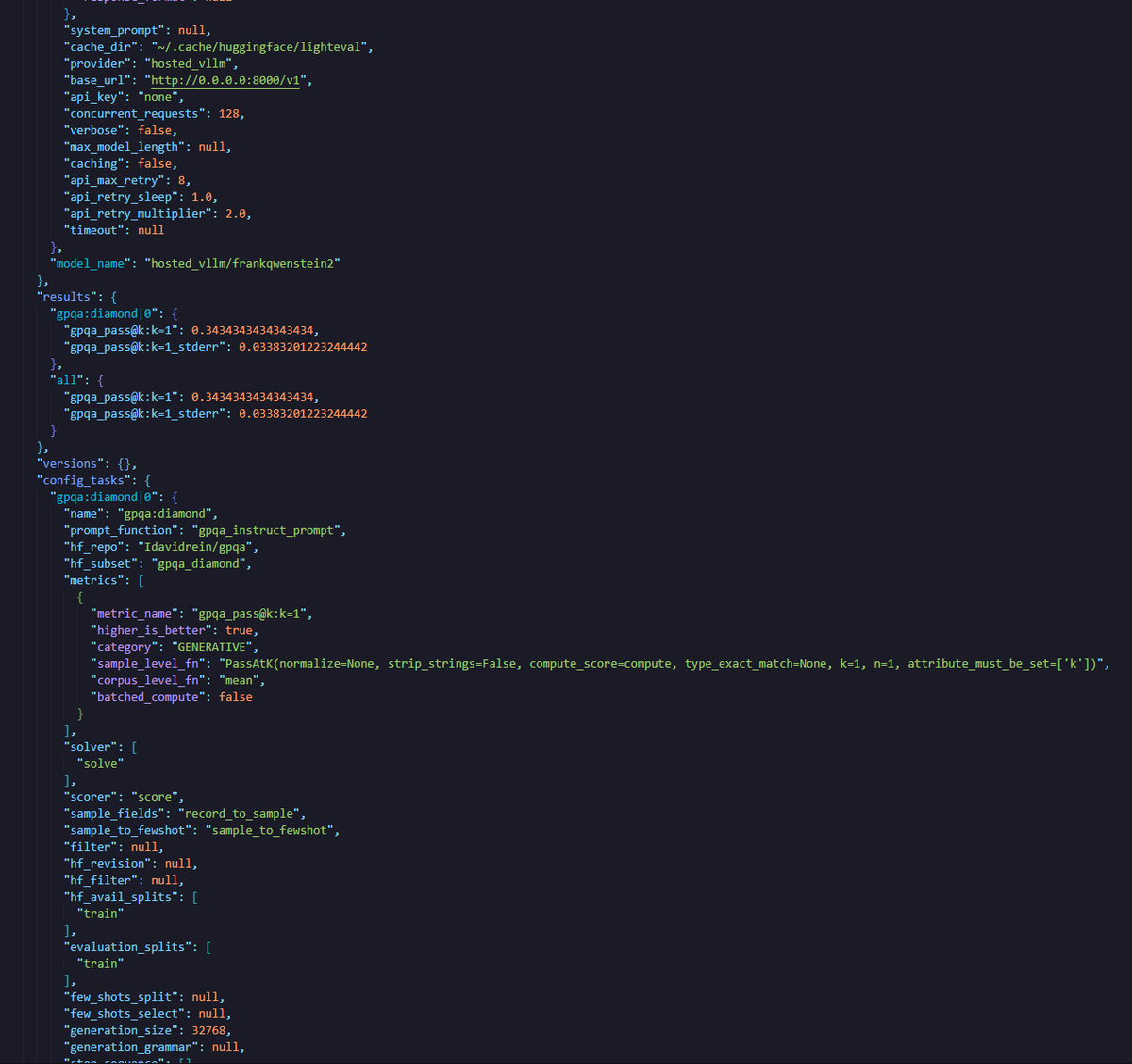
It turns out the SYNTH recipe scales well - the latest checkpoint of FrankQwenStein2 1B achieved 34,34% on GPQA-Diamond, making it far better than older, large-scale models. The most impressive aspect, beyond its size, is that it has only seen 148 billion tokens during training so far.
@pleiasfr 's SYNTH recipe is simply outstanding.
The chart is from the @EpochAIResearch website (I manually added FrankQwenStein)

English
Oh boy, 28% GPQA Diamond for a 164M parameters model is quite impressive, isn’t it?

English
Vadim Borisov, PhD retweetledi
New paper from top Chinese Labs show how to train an AI agent that learns a compact world model by practicing inside interactive games.
Standard agents try to plan everything in 1 huge thought, which is heavy and often locks in wrong assumptions.
This work instead lets the model act for several steps, see the real game response, and update its understanding on the fly.
From many such episodes it builds a world model, meaning an internal sense of what each action usually does in that environment.
WMAct adds reward rescaling, where the score is multiplied by the fraction of moves that changed the state, so pointless shuffling loses credit.
It also uses interaction frequency annealing, starting with many turns but slowly tightening this limit so the model must think more.
In maze, Sokoban, and taxi grid worlds, this training lets the agent solve many puzzles in a single shot that earlier needed trial-and-error dialogues.
The same model also gets noticeable gains on separate math, code, and general benchmarks, suggesting that this thinking-by-doing practice sharpens reasoning beyond these games.
----
Paper Link – arxiv. org/abs/2511.23476
Paper Title: "Thinking by Doing: Building Efficient World Model Reasoning in LLMs via Multi-turn Interaction"

English
Vadim Borisov, PhD retweetledi

A transformer's attention could be 99% sparser without losing its smarts!
A new research from MPI-IS, Oxford, and ETH Zürich shows it can.
A simple post-training method strips away redundant connections, revealing a cleaner, more interpretable circuit.
This suggests much of the computation we rely on is just noise.
Sparse Attention Post-Training for Mechanistic Interpretability
Paper: arxiv.org/abs/2512.05865

English
beautiful analysis on how people are using LLMs (via @openrouter)
openrouter.ai/state-of-ai
English
Vadim Borisov, PhD retweetledi

You know how some people seem to have a magic touch with LLMs? They get incredible, nuanced results while everyone else gets generic junk.
The common wisdom is that this is a technical skill. A list of secret hacks, keywords, and formulas you have to learn.
But a new paper suggests this isn't the main thing.
The skill that makes you great at working with AI isn't technical. It's social.
Researchers (Riedl & Weidmann) analyzed how 600+ people solved problems alone vs. with an AI.
They used a statistical method to isolate two different things for each person:
Their 'solo problem-solving ability'
Their 'AI collaboration ability'
Here's the reveal: The two skills are NOT the same.
Being a genius who can solve problems in your own head is a totally different, measurable skill from being great at solving problems with an AI partner.
Plot twist: The two abilities are barely correlated.
So what IS this 'collaboration ability'?
It's strongly predicted by a person's Theory of Mind (ToM)—your capacity to intuitively model another agent's beliefs, goals, and perspective.
To anticipate what they know, what they don't, and what they need.
In practice, this looks like:
Anticipating the AI's potential confusion
Providing helpful context it's missing
Clarifying your own goals ("Explain this like I'm 15")
Treating the AI like a (somewhat weird, alien) partner, not a vending machine.
This is where it gets strange.
A user's ToM score predicted their success when working WITH the AI...
...but had ZERO correlation with their success when working ALONE.
It's a pure collaborative skill.
It goes deeper. This isn't just a static trait.
The researchers found that even moment-to-moment fluctuations in a user's ToM—like when they put more effort into perspective-taking on one specific prompt—led to higher-quality AI responses for that turn.
This changes everything about how we should approach getting better at using AI.
Stop memorizing prompt "hacks."
Start practicing cognitive empathy for a non-human mind.
Try this experiment. Next time you get a bad AI response, don't just rephrase the command. Stop and ask:
"What false assumption is the AI making right now?"
"What critical context am I taking for granted that it doesn't have?"
Your job is to be the bridge.
This also means we're probably benchmarking AI all wrong.
The race for the highest score on a static test (MMLU, etc.) is optimizing for the wrong thing. It's like judging a point guard only on their free-throw percentage.
The real test of an AI's value isn't its solo intelligence. It's its collaborative uplift.
How much smarter does it make the human-AI team? That's the number that matters.
This paper gives us a way to finally measure it.
I'm still processing the implications. The whole thing is a masterclass in thinking clearly about what we're actually doing when we talk to these models.
Paper: "Quantifying Human-AI Synergy" by Christoph Riedl & Ben Weidmann, 2025.

English
Vadim Borisov, PhD retweetledi

The "Continuous Thought Machines" paper is amazing: arxiv.org/abs/2505.05522
Also, I love it when authors provide an interactive demo along with their paper:
pub.sakana.ai/ctm/
English
Vadim Borisov, PhD retweetledi

One point I made that didn’t come across:
- Scaling the current thing will keep leading to improvements. In particular, it won’t stall.
- But something important will continue to be missing.
Haider.@haider1
here are the most important points from today's ilya sutskever podcast: - superintelligence in 5-20 years - current scaling will stall hard; we're back to real research - superintelligence = super-fast continual learner, not finished oracle - models generalize 100x worse than humans, the biggest AGI blocker - need completely new ML paradigm (i have ideas, can't share rn) - AI impact will hit hard, but only after economic diffusion - breakthroughs historically needed almost no compute - SSI has enough focused research compute to win - current RL already eats more compute than pre-training
English
Vadim Borisov, PhD retweetledi

Crazy bug on Openreview @openreviewnet and ICLR @iclr_conf !!! ICLR becomes single-blind now! The Chinese social media just post a method to find the identity of any reviewer(See in the comment) ! I just find it to be true! Please fix the bug now! Please help the justice!

English