林克 Link
443 posts


林克 Link
@veoxft
Engineer @ Big Tech | Building & exploring LLMs everyday Sharing practical AI tips, prompting techniques Also: Hiking addict ⛰️ & Landscape photograph 📷
Katılım Ocak 2013
121 Takip Edilen53 Takipçiler

几个月前就用stitch来做产品原型设计了,当时效果就很强。
当时流程是先对话gpt做prd,在提交给stitch做原型设计,还可以做局部修改,最后直接让stitch出代码。最后把项目上传到github pages,使用cloudflare部署,静态页面都不需要服务器。
这个效果非常好,在产品会上直接把这个cloudflare链接放出来,直接没产品什么事了。。。
Stitch by Google@stitchbygoogle
Meet the new Stitch, your vibe design partner. Here are 5 major upgrades to help you create, iterate and collaborate: 🎨 AI-Native Canvas 🧠 Smarter Design Agent 🎙️ Voice ⚡️ Instant Prototypes 📐 Design Systems and DESIGN.md Rolling out now. Details and product walkthrough video in 🧵
中文



之前看马斯克的采访,对微信的设计大加赞赏,啥功能都有,包括支付购物聊天社交,现在搞出一个 X Money ,支持转账、存款收益。这算不算抄袭微信啊...
Cointelegraph@Cointelegraph
🔥 LATEST: Elon Musk hints X Money launch as users begin accessing beta wallet features like send, deposit, and yield on X.
中文

宣布一件大事,我们把 6551 的X + 全网新闻源MCP + SKILL 开源了!
很多人说,6551 的新闻源、推特面板很好用就是消息太多看不完。
还有很多朋友跟我说 X API 太难接,Skill 学不会,折腾半天龙虾就是跑不起来。
今天直接解决,我们把我们积累了1年的数据基础架构全部打包成 MCP + SKILL,任何人都可以几分钟部署,24h帮你看新闻。
🦞 你的龙虾现在可以:
• 直接连上 X 数据 + 全网50+实时新闻+链上数据,不用配 API 密钥。
• 24h 监控、分析、触发tg提醒。
照着 GitHub README 部署,几分钟就能装好。
欢迎大家安装试用和分享体验,有问题及时反馈及时迭代。
也欢迎👏🏻有热情的 dev 参加我们的生态
MCP
github.com/6551Team/openn…
github.com/6551Team/opent…
SKILL
clawhub.ai/infra403/openn…
clawhub.ai/infra403/opent…

中文




OpenAI 发布了 GPT-5.3-Codex-Spark,专为实时编程设计的小模型,也是 OpenAI 和 Cerebras 合作后的第一个成果。跑在 Cerebras 晶圆级芯片上,推理速度超过每秒 1000 个 token。x.com/OpenAI/status/…
Codex 之前的强项是长时间自主运行,连续工作几小时甚至几天。但日常写代码更多是改个函数、调个接口、重构一段逻辑,等模型想十几分钟再出结果,体验很差。
Codex-Spark 填的就是这个空缺:你可以一边看它输出一边打断、纠正、追问,像跟一个反应极快的搭档对话。
SWE-Bench Pro 上,Codex-Spark 达到 51% 准确率只需 2.3 分钟,GPT-5.3-Codex 同等准确率要 3 分钟,冲到 57% 则需要 16 分钟。
Terminal-Bench 2.0 上 Spark 得分 58.4%,比不上完整版 Codex 的 77.3%,但大幅超过上一代小模型的 46.1%。
OpenAI 顺便把整条推理管线做了优化:引入持久化 WebSocket 连接,往返开销降 80%,每 token 额外开销降 30%,首 token 响应减半。
Cerebras 晶圆级引擎负责极低延迟场景,GPU 仍是训练和推理主力,两者可混合使用。
目前 128K 上下文、纯文本、仅 ChatGPT Pro 用户研究预览。
后续规划是让实时交互和长线任务两种模式融合:Codex 在跟你实时对话的同时,把耗时任务分派给后台子智能体,用户不需要预先选模式。
模型越强,交互速度越是瓶颈,Codex-Spark 是 OpenAI 在这条路上的第一步。
中文
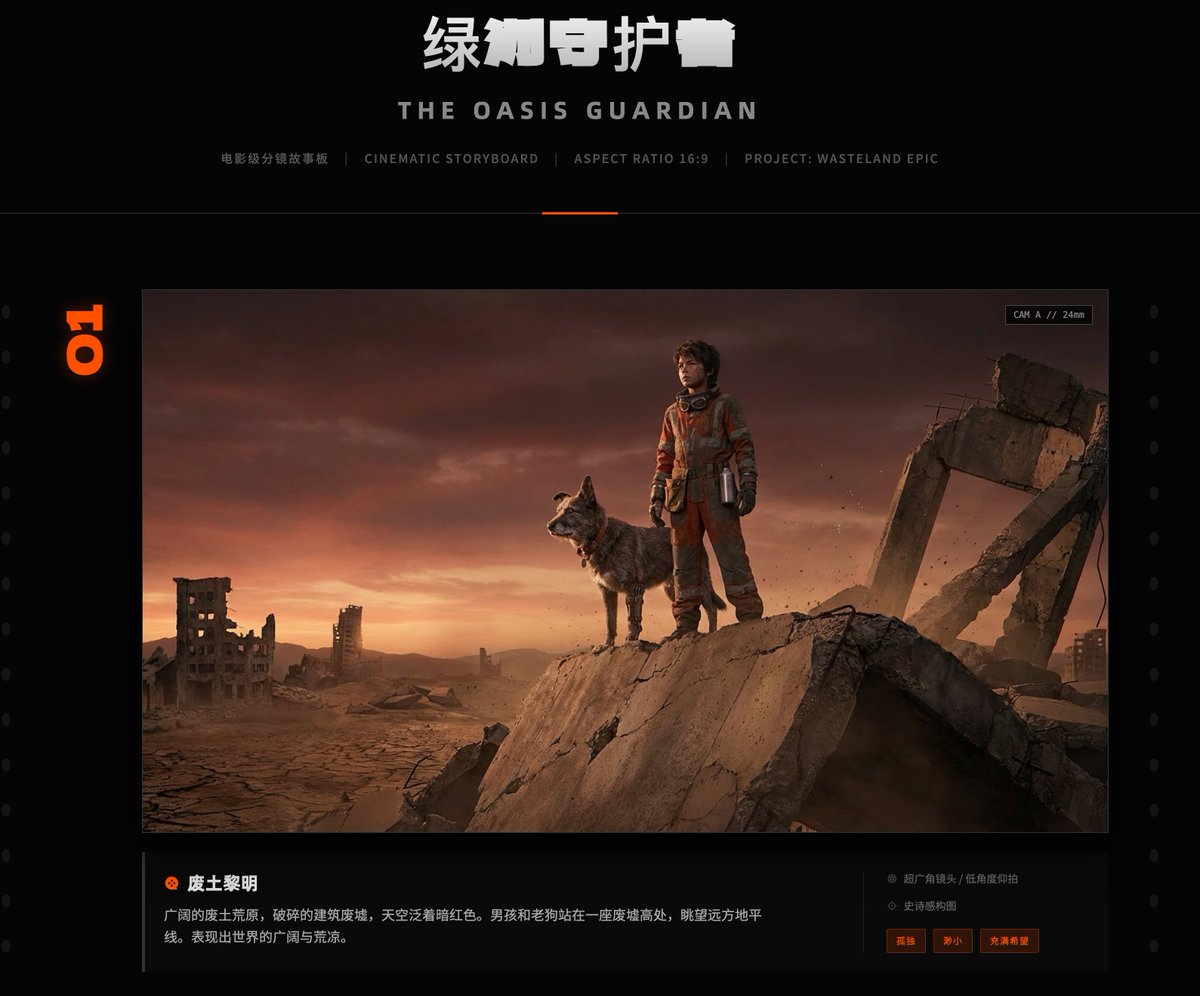
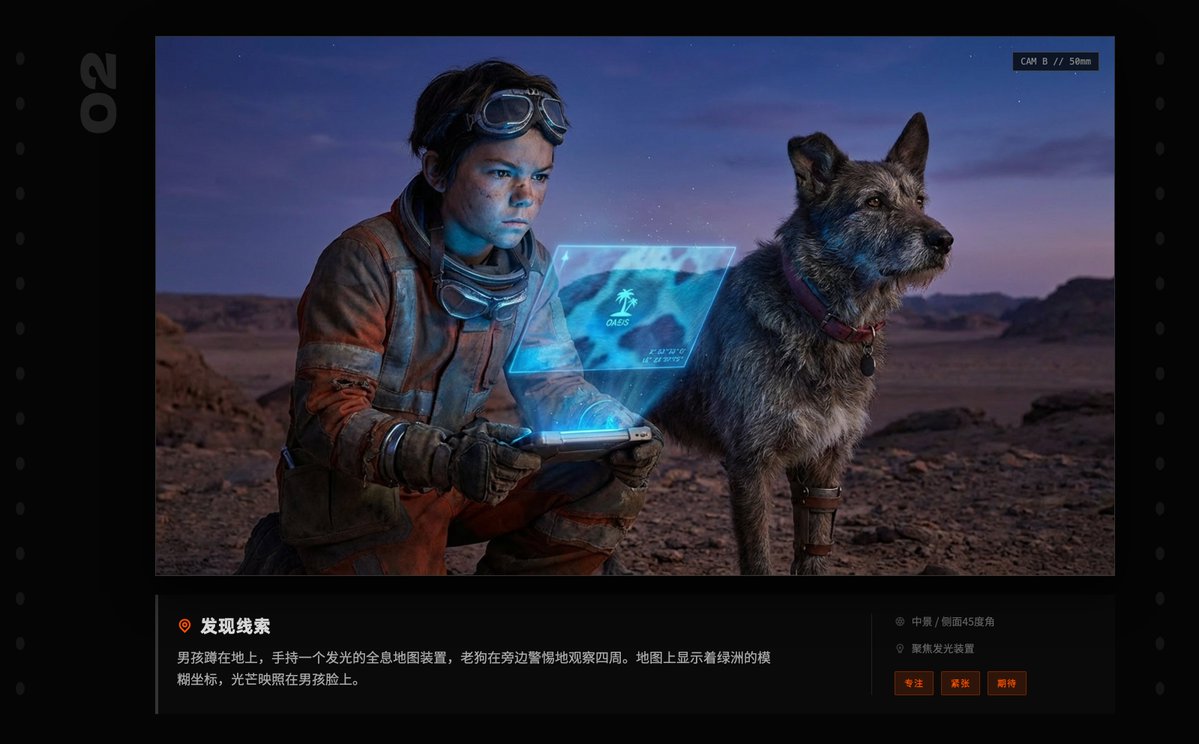
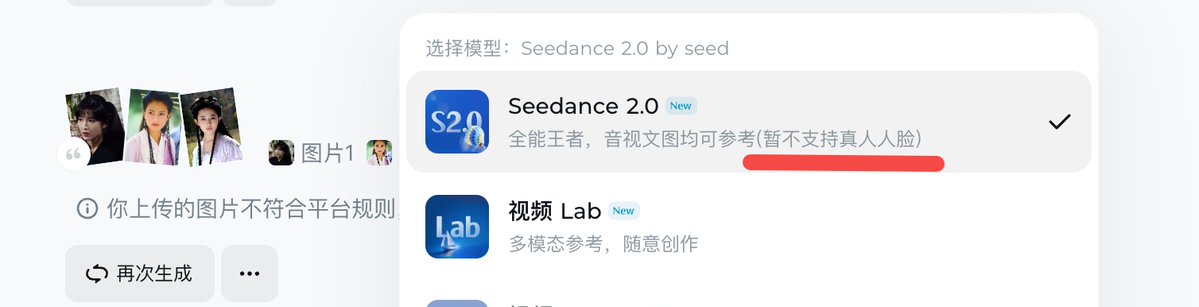
Seedance 2.0 这几天是真的火,X 上到处都是它生成的视频,又一次让海外 AI 圈羡慕国内 AI 圈。
影视飓风的 Tim 昨晚发了测试视频,对技术本身评价很高:分镜设计、运镜、音画匹配都是质的飞跃。
那条视频我也看了,其中他提到一个问题:上传自己照片做参考图时,生成视频的声音和他本人很像,而他从未提供过任何声音样本。
这倒不奇怪,影视飓风在全网有大量高清视频,肯定已经被用作训练数据。
之前谷歌 Veo 3 推出时,人们发现生成的视频也很像一些知名创作者的作品;OpenAI 最早推出 Sora 时,外媒也测试到它能高度模仿经典电影片段。用公开数据训练是国内外大模型的共同做法,Tim 作为明星级公众人物,素材进入公开数据集并不意外。
这种担忧挺合理的,但这趋势我们挡不住,现在已经没有人能阻挡 AI 的加速了。
最早音色克隆技术出来的时候,大厂掌握了技术但不敢放开,反倒是小团队先做出来发布了,慢慢大家也就跟进接受了。
这几天大火的 ClawdBot/OpenClaw 也是同样的路径,各种隐私安全问题被讨论,但因为是个人小团队项目,大家宽容度明显更高,等大厂后续下场反而更容易被接受。
这种事大厂反而能让人放心一点,大厂有能力也有动力去做合规限制,小作坊下料才是真的猛。
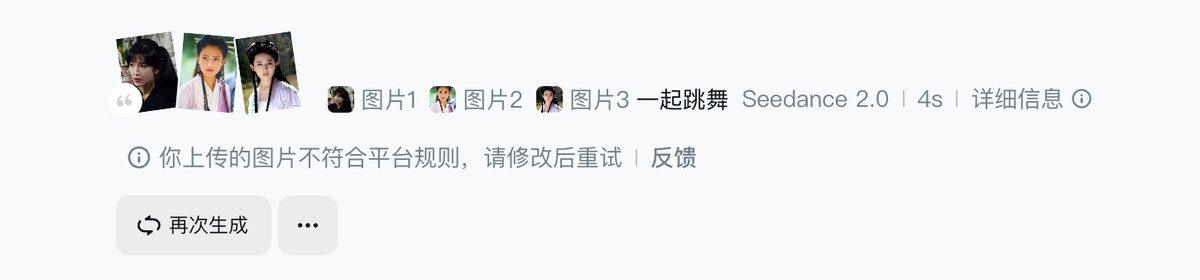
事实上即梦已经限制了真人人脸生成视频,大厂在技术狂奔时还是会守住一些底线。
结果倒是很多人在那哀叹,限制了真人人脸生成视频,少了一些可以测试的例子,很多视频都成了绝版。
与其焦虑不如多想想怎么在技术创新与数据合规之间找到平衡。
像 Sora 2 的分身(Chapter)功能就是一个不错的尝试方向,让你既能享受技术带来的乐趣,又减少一些隐私上的担忧。比如我给孩子制作了分身,我只会给家人分享,不会让别人用。
好消息是,人们对 AI 生成的音频视频正在建立起更多辨别力和免疫力,这本身也是一种自然的适应过程。我也经常跟家人朋友科普让他们小心 AI 视频。
我自己有个小技巧是先看视频时长是不是 10 秒 15 秒这种整数,不过这招已经快像看 AI 图片人物有没有六根手指一样不灵了。
你们都用什么技巧分辨 AI 生成的图片或者视频呢?
中文
yetone 都夸的 AI agent toolkit
OpenClaw 是基于它构建的
github.com/badlogic/pi-mo…
yetone@yetone
再次感叹一下,pi 的 agent loop 只提供四个工具: read, write, edit, bash, 真的是明智极了。其他所有的能力都依赖于 skills,真的是太聪明了,这样还能把 prompt caching 给利用到最大化
中文